搜索到
15
篇与
的结果
-
 thinkphp-swoole运行报错和wss无法访问的问题 thinkphp-swoole运行报错和wss无法访问的问题thinkphp6.0项目,在运行swoole服务时log日志疯狂报错$ php think swoole restart整了好几个小时结果是php版本问题,当时默认切到了php8...更换命令为73就好了$ /www/server/php/73/bin/php think swoole restart运行起来后ws:协议正常访问,wss无法访问问题如下:You are trying to use the same port (8090) for ws:// and wss:// - this will most likely not work. While you don't show any server side configuration I suspect that your websocket server on port 8090 can only do plain WebSockets (i.e. ws:// and not wss://) and that you expect the TLS from the HTTP server (port 443) to be magically applied to wss:// on port 8090 too. This is not the case. By trying wss:// with port 8090 you are instead trying to do a TLS handshake with a server which does not speak TLS, which then results in net::ERR_SSL_PROTOCOL_ERROR.The common setup is instead to use a web server like nginx or Apache as reverse proxy for the websocket server and terminate the TLS at the web server. This way both ws:// and wss:// work on the standard ports (i.e. 80 and 443) from outside and the internet plain websocket server on port 8090 is will be made unreachable from outside. See for example NGINX to reverse proxy websockets AND enable SSL (wss://)? or WebSocket through SSL with Apache reverse proxy for how to setup something like this.需要为项目配置一个反向代理 #REWRITE-START URL重写规则引用,修改后将导致面板设置的伪静态规则失效 include /www/server/panel/vhost/rewritexxxx.conf; #REWRITE-END location /app { proxy_pass http://127.0.0.1:9999; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_buffering off; proxy_request_buffering off; } #禁止访问的文件或目录 location ~ ^/(\.user.ini|\.htaccess|\.git|\.env|\.svn|\.project|LICENSE|README.md)引用1.WebSocket error: net::ERR_SSL_PROTOCOL_ERROR: https://stackoverflow.com/questions/59542929/websocket-error-neterr-ssl-protocol-error
thinkphp-swoole运行报错和wss无法访问的问题 thinkphp-swoole运行报错和wss无法访问的问题thinkphp6.0项目,在运行swoole服务时log日志疯狂报错$ php think swoole restart整了好几个小时结果是php版本问题,当时默认切到了php8...更换命令为73就好了$ /www/server/php/73/bin/php think swoole restart运行起来后ws:协议正常访问,wss无法访问问题如下:You are trying to use the same port (8090) for ws:// and wss:// - this will most likely not work. While you don't show any server side configuration I suspect that your websocket server on port 8090 can only do plain WebSockets (i.e. ws:// and not wss://) and that you expect the TLS from the HTTP server (port 443) to be magically applied to wss:// on port 8090 too. This is not the case. By trying wss:// with port 8090 you are instead trying to do a TLS handshake with a server which does not speak TLS, which then results in net::ERR_SSL_PROTOCOL_ERROR.The common setup is instead to use a web server like nginx or Apache as reverse proxy for the websocket server and terminate the TLS at the web server. This way both ws:// and wss:// work on the standard ports (i.e. 80 and 443) from outside and the internet plain websocket server on port 8090 is will be made unreachable from outside. See for example NGINX to reverse proxy websockets AND enable SSL (wss://)? or WebSocket through SSL with Apache reverse proxy for how to setup something like this.需要为项目配置一个反向代理 #REWRITE-START URL重写规则引用,修改后将导致面板设置的伪静态规则失效 include /www/server/panel/vhost/rewritexxxx.conf; #REWRITE-END location /app { proxy_pass http://127.0.0.1:9999; proxy_http_version 1.1; proxy_set_header Upgrade $http_upgrade; proxy_set_header Connection "upgrade"; proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; proxy_set_header X-Forwarded-Proto $scheme; proxy_buffering off; proxy_request_buffering off; } #禁止访问的文件或目录 location ~ ^/(\.user.ini|\.htaccess|\.git|\.env|\.svn|\.project|LICENSE|README.md)引用1.WebSocket error: net::ERR_SSL_PROTOCOL_ERROR: https://stackoverflow.com/questions/59542929/websocket-error-neterr-ssl-protocol-error -
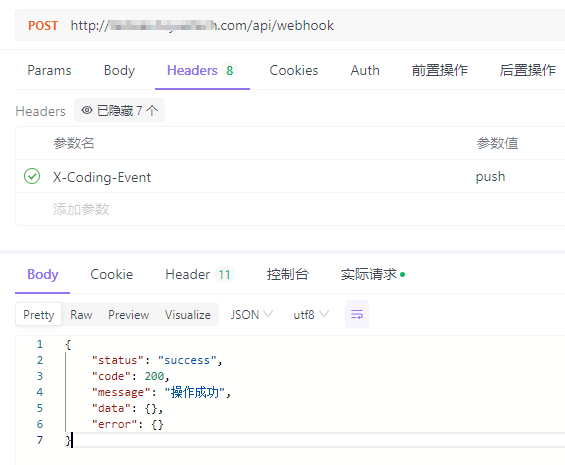
Laravel对接Coding仓库WebHooks实现自动部署 上下文环境都是基于宝塔的,因为Bash操作都使用的www用户,其他环境并不适用项目执行bash主要使用的是exec函数,项目跑在nginx上。nginx使用的用户为www,所以会有权限问题权限解决:vim /etc/sudoers # 文件内容如下 # www ALL=(ALL) NOPASSWD: /usr/bin/git # + # www ALL=(www) NOPASSWD: /www/server/php/81/bin/php /usr/local/bin/composer install # + 第一行配置:允许用户www以任何用户身份运行/usr/bin/git命令,而无需输入密码。 第二行配置:允许用户www以自身身份运行指定的composer install命令,而无需输入密码。路由:/** * 处理WebHook的请求 * 自动化部署 */ Route::post('webhook', [App\Http\Controllers\Deploy\WebHookController::class, 'handle']); 控制器:解释: 当发现仓库有push操作后,自动执行git pull拉取代码,然后执行composer install安装依赖class WebHookController extends Controller { /** * 监听Coding仓库代码更新操作 * 自动部署最新版项目 * @return \Illuminate\Http\JsonResponse|\Illuminate\Http\Resources\Json\JsonResource */ public function handle(Request $request) { Log::info('接收到Coding WebHook', [$request]); $hookEvent = $request->header('X-Coding-Event'); if (!\Str::contains($hookEvent, 'push')) return \Response::ok(); Log::info("开始执行自动部署任务"); // Git Pull exec('cd .. && sudo git pull' . ' 2>&1', $output, $status); if ($status != 0) { Log::error('拉取代码失败', [$output, $status]); \Response::fail('拉取代码失败', ResponseCodeEnum::SYSTEM_ERROR); } Log::info("拉取代码成功", [$output, $status]); // Composer Install exec('cd .. && /www/server/php/81/bin/php /usr/local/bin/composer install' . ' 2>&1', $output, $status); if ($status != 0) { Log::error('composer安装失败', [$output, $status]); \Response::fail('composer安装失败', ResponseCodeEnum::SYSTEM_ERROR); } Log::info("composer安装成功", [$output, $status]); // 后端完成部署 Log::info("自动部署任务执行完毕"); return \Response::ok(); } }模拟:Coding公司的项目使用腾讯旗下的Coding来管理项目,也是有WebHook的功能引用1.Coding WebHook:https://coding.net/help/docs/project-settings/open/webhook.html2.如何实现Git Push之后自动部署到服务器?:https://blog.csdn.net/ll15982534415/article/details/136669152
-
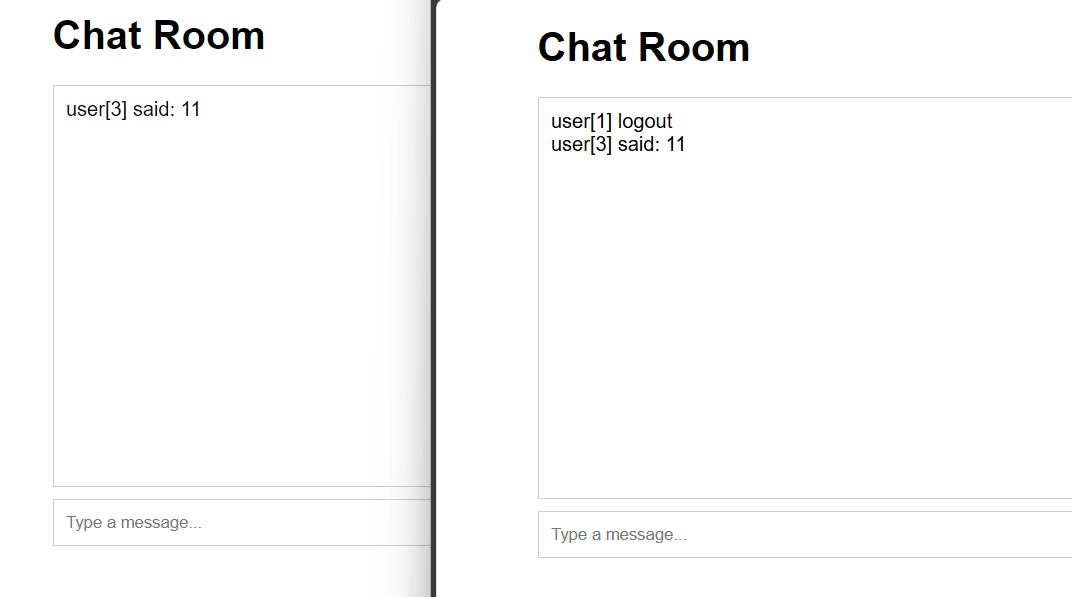
用workman框架开发网络聊天室(PHP) 任意位置建立项目目录如 SimpleChat/进入目录执行 composer require workerman/workerman然后编写一个chat.php:<?php use Workerman\Worker; use Workerman\Connection\TcpConnection; require_once __DIR__ . '/vendor/autoload.php'; $global_uid = 0; // 当客户端连上来时分配uid,并保存连接,并通知所有客户端 function handle_connection($connection) { global $text_worker, $global_uid; // 为这个连接分配一个uid $connection->uid = ++$global_uid; } // 当客户端发送消息过来时,转发给所有人 function handle_message(TcpConnection $connection, $data) { global $text_worker; foreach($text_worker->connections as $conn) { $conn->send("user[{$connection->uid}] said: $data"); } } // 当客户端断开时,广播给所有客户端 function handle_close($connection) { global $text_worker; foreach($text_worker->connections as $conn) { $conn->send("user[{$connection->uid}] logout"); } } // 创建一个文本协议的Worker监听2347接口 $text_worker = new Worker("websocket://0.0.0.0:2347"); // 只启动1个进程,这样方便客户端之间传输数据 $text_worker->count = 1; $text_worker->onConnect = 'handle_connection'; $text_worker->onMessage = 'handle_message'; $text_worker->onClose = 'handle_close'; Worker::runAll(); 前端页面:<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <meta name="viewport" content="width=device-width, initial-scale=1.0"> <title>WebSocket Chat Room</title> <style> body { font-family: Arial, sans-serif; } #chat { width: 90%; max-width: 600px; margin: 0 auto; } #messages { border: 1px solid #ccc; height: 300px; overflow-y: scroll; padding: 10px; } #input { display: flex; margin-top: 10px; } #input input { flex: 1; padding: 10px; border: 1px solid #ccc; } #input button { padding: 10px; border: 1px solid #ccc; background: #007BFF; color: white; cursor: pointer; } </style> </head> <body> <div id="chat"> <h1>Chat Room</h1> <div id="messages"></div> <div id="input"> <input type="text" id="messageInput" placeholder="Type a message..."> <button onclick="sendMessage()">Send</button> </div> </div> <script> const ws = new WebSocket('ws://localhost:2347'); const messagesDiv = document.getElementById('messages'); const messageInput = document.getElementById('messageInput'); ws.onopen = () => { console.log('Connected to the chat server'); }; ws.onmessage = (event) => { const message = document.createElement('div'); message.textContent = event.data; messagesDiv.appendChild(message); messagesDiv.scrollTop = messagesDiv.scrollHeight; }; function sendMessage() { const message = messageInput.value; if (message) { ws.send(message); messageInput.value = ''; } } messageInput.addEventListener('keydown', (event) => { if (event.key === 'Enter') { sendMessage(); } }); </script> </body> </html> 最后使用 php chat.php运行
-
laravel jwt 无感刷新token 为保证和前端交互过程中,用户可以自动刷新token创建一个中间件文件,命名为 RefreshToken<?php namespace App\Http\Middleware; use Auth; use Closure; use Tymon\JWTAuth\JWTAuth; use Tymon\JWTAuth\Exceptions\JWTException; use Tymon\JWTAuth\Http\Middleware\BaseMiddleware; use Tymon\JWTAuth\Exceptions\TokenExpiredException; use Symfony\Component\HttpKernel\Exception\UnauthorizedHttpException; class RefreshToken extends BaseMiddleware { function handle($request, Closure $next) { // 检查此次请求中是否带有 token,如果没有则抛出异常。 $this->checkForToken($request); // 使用 try 包裹,以捕捉 token 过期所抛出的 TokenExpiredException 异常 try { // 检测用户的登录状态,如果正常则通过 if ($this->auth->parseToken()->authenticate()) { return $next($request); } throw new UnauthorizedHttpException('jwt-auth', '未登录'); } catch (TokenExpiredException $exception) { // 此处捕获到了 token 过期所抛出的 TokenExpiredException 异常,我们在这里需要做的是刷新该用户的 token 并将它添加到响应头中 try { /* * token在刷新期内,是可以自动执行刷新获取新的token的 * 当JWT_BLACKLIST_ENABLED=false时,可以在JWT_REFRESH_TTL时间内,无限次刷新使用旧的token换取新的token * 当JWT_BLACKLIST_ENABLED=true时,刷新token后旧的token即刻失效,被放入黑名单 * */ // 刷新用户的 token $token = $this->auth->refresh(); // 使用一次性登录以保证此次请求的成功 Auth::guard('api')->onceUsingId($this->auth->manager()->getPayloadFactory()->buildClaimsCollection()->toPlainArray()['sub']); } catch (JWTException $exception) { // 如果捕获到此异常,即代表 refresh 也过期了,用户无法刷新令牌,需要重新登录。 throw new UnauthorizedHttpException('jwt-auth', $exception->getMessage()); } } // 在响应头中返回新的 token return $this->setAuthenticationHeader($next($request), $token); } }修改App\Http\Kernel.pho文件protected $routeMiddleware = [ //...... 'token.refresh' => \App\Http\Middleware\RefreshToken::class, //...... ];修改routes.api.php文件// 需要 token 验证的接口 $api->group(['middleware' => ['token.refresh','auth.jwt']], function($api) { //....... });修改.env文件#Jwt JWT_SECRET=HSKxIUfwCdJj5gadbqfQo5im9zje95g9 #token有效时间,单位:分钟, 有效时间调整为2个小时 JWT_TTL=120 #为了使令牌无效,您必须启用黑名单。如果不想或不需要此功能,请将其设置为 false。 #当JWT_BLACKLIST_ENABLED=false时,可以在JWT_REFRESH_TTL时间内,无限次刷新使用旧的token换取新的token #当JWT_BLACKLIST_ENABLED=true时,刷新token后旧的token即刻失效,被放入黑名单 JWT_BLACKLIST_ENABLED=true #当多个并发请求使用相同的JWT进行时,由于 access_token 的刷新 ,其中一些可能会失败,以秒为单位设置请求时间以防止并发的请求失败。 #时间为10分钟,10分钟之内可以拿旧的token换取新的token。当JWT_BLACKLIST_ENABLED为true时,可以保证不会立即让token失效 JWT_BLACKLIST_GRACE_PERIOD=6005.备注:JWT token的三个时间,config/jwt.php查看a.有效时间,有效是指你获取token后,在多少时间内可以凭这个token去获取资源,逾期无效。'ttl' => env('JWT_TTL', 60), //单位分钟b.刷新时间,刷新时间指的是在这个时间内可以凭旧 token 换取一个新 token。例如 token 有效时间为 60 分钟,刷新时间为 20160 分钟,在 60 分钟内可以通过这个 token 获取新 token,但是超过 60 分钟是不可以的,然后你可以一直循环获取,直到总时间超过 20160 分钟,不能再获取。这里要强调的是,是否在刷新期可以一直用旧的token获取新的token,这个是由blacklist_enabled这个配置决定的,这个是指是否开启黑名单,默认是开启的,即刷新后,旧token立马加入黑名单,不可在用。'refresh_ttl' => env('JWT_REFRESH_TTL', 20160),c.宽限时间,宽限时间是为了解决并发请求的问题,假如宽限时间为 0s ,那么在新旧 token 交接的时候,并发请求就会出错,所以需要设定一个宽限时间,在宽限时间内,旧 token 仍然能够正常使用// 宽限时间需要开启黑名单(默认是开启的),黑名单保证过期token不可再用 'blacklist_enabled' => env('JWT_BLACKLIST_ENABLED', true) // 设定宽限时间,单位:秒 'blacklist_grace_period' => env('JWT_BLACKLIST_GRACE_PERIOD', 600)
-
FastAdmin速查手册-常见解决方案 FastAdmin速查手册-常见解决方案忘记密码怎么办?数据库修改fa_admin表的两个字段密码(password):c13f62012fd6a8fdf06b3452a94430e5密码盐(salt):rpR6Bv登录密码是 123456为了你的站点安全,登录后台后请及时修改密码。【分享】忘记 FastAdmin 后台密码了怎么办?:https://ask.fastadmin.net/article/43.html引用1.一张图解析FastAdmin中的表格列表的功能:https://ask.fastadmin.net/article/323.html
-
Discuz X论坛二开速查文档 Discuz X论坛二开速查文档前言公司最近要做一个论坛的小程序,没找到合适的就想用discuz进行二开要购买一套主题,选用themebox的:https://bbs.themebox.cn/portal.php?mobile=2一、数据库操作所有的用户输入数据都建议先使用daddslashes函数处理,以防止SQL注入攻击。1.1 常用API函数功能DB::table($tablename)获取正确带前缀的表名。DB::delete($tablename, 条件,条数限制)删除表中的数据DB::insert($tablename, 数据(数组),是否返回插入ID,是否是替换式,是否silent)插入数据操作DB::update($tablename, 数据(数组)条件)更新操作DB::fetch(查询后的资源)从结果集中取关联数组,注意如果结果中的两个或以上的列具有相同字段名,最后一列将优先。DB::fetch_first($sql)取查询的第一条数据fetchDB::fetch_all($sql)查询并fetchDB::result_first($sql)查询结果集的第一个字段值DB::query($sql)普通查询DB::num_rows(查询后的资源)获得记录集总条数DB::_execute(命令,参数)执行mysql类的命令DB::limit(n,n)返回限制字串DB::field(字段名, $pid)返回条件,如果为数组则返回 in 条件DB::order(别名, 方法)排序注意:由于 X1.5 里增加了SQL的安全性检测。因此,如果你的SQL语句里包含以下开头的函数 load_file,hex,substring,if,ord,char。 或者包含以下操作 intooutfile,intodumpfile,unionselect,(select')都将被拒绝执行。1.2 格式化参数替换参数功能%t表名%s字串,如果是数组就序列化%f按 %F 的样式格式化字串%d整数%i不做处理%n若为空即为0,若为数组,就用',' 分割,否则加引号1.3 C对象方法名参数返回值说明C::t($tablename)->insert()数据数组新插入记录的 ID 或影响行数插入一条新记录到数据表C::t($tablename)->update()条件,更新数据影响行数根据条件更新记录C::t($tablename)->delete()条件影响行数根据条件删除记录C::t($tablename)->fetch()条件单条记录的数组根据条件获取一条记录C::t($tablename)->fetch_all()条件所有符合条件的记录的数组根据条件获取多条记录C::t($tablename)->count()条件记录数根据条件统计记录数C::t($tablename)->truncate() 清空表C::t($tablename)->fetch_all_field() fetch所有的字段名C::t($tablename)->optimize() 优化表二、Discuz源码结构DISCUZ使用自己的框架,与现在主流的web框架不同,DISCUZ没有路由表,他的路由是由入口文件来实现的。2.1 目录讲解api: Discuz 论坛和其他系统的接口文件文件名功能uc.phpUCenter 通信文件/api/addons应用中心/api/connect通讯互联/api/googleGoogle引擎结构处理/api/javascript数据和广告的js调用/api/manyoumanyou应用及搜索等相关服务/api/remote远程更新/api/trade支付宝、财付通等交易接口archiver: 论坛Archiver静态化目录 config: 论坛配置文件目录文件名功能config_global.php论坛核心参数配置文件config_ucenter.phpUCenter核心参数配置文件data: 论坛数据缓存目录文件名功能install论坛安装目录source程序后端功能处理目录discuz_version.php程序版本号文件source: 程序核心目录文件名功能/source/admincp后台管理/source/archiver论坛archiver静态化程序目录/source/class核心类库/source/functiondiscuzX自定义函数库/source/include程序功能组件目录/source/language程序语言包(kv结构)/source/module程序功能模块程序包/source/plugin插件扩展目录static: 程序资源目录(头像、图片、下载文件、js文件等等)template:前端模板目录文件名功能/default/common基础css文件、header、footer等公共引入文件/default/collage大学计划页面/default/digedige专区页面/default/forum首页、帖子页面/default/member会员页面/default/home家园页面/default/group群组页面/default/mobile移动端页面/default/portal文章页面/default/search搜索页面uc_client: UCenter客户端目录文件名功能/uc_client/controlUC业务处理操作类/uc_client/data缓存文件目录/uc_client/lib类库目录(包括数据库操作类,XML类,UCCODE类,邮件发送类)/uc_client/modelUC业务模型类uc_serverUCenter服务端 后台ucenter功能实现目录根目录文件文件名功能admin.php后台入口文件api.phpAPI输出 入口文件connect.php云平台接口文件forum.php帖子信息入口文件group.php群组入口文件home.php家园入口文件index.php首页member.php用户入口文件(登录、注册、退出等)misc.php程序杂项扩展入口plugin.php插件入口文件portal.php门户入口文件robots.txt搜索引擎限制文件search.php搜索频道入口文件2.2 运行逻辑discuz的入口文件起到了路由的作用。一个标准的discuz请求如下:http://localhost/home.php?mod=space&uid=1&do=profile三、广告3.1、获取自定义广告下的所有item这里自定义的广告位于pre_common_advertisement_custom要查某一个类型下的所有文章可以通过名字来获取到id// 1.首先查询pre_common_advertisement_custom表获取name为小程序的id $adid = DB::result_first("SELECT id FROM " . DB::table('common_advertisement_custom') . " WHERE name = '小程序'");再根据id查询pre_common_advertisement表,关联字段位于parameters字段,需要拼接判断// 2.查询pre_common_advertisement表获取广告信息 $flag = ':"' . $adid . '";}s:'; $ad = DB::fetch_all("SELECT parameters FROM " . DB::table('common_advertisement') . " WHERE available = '1' AND parameters LIKE '%$flag%'"); $adresult = []; // 3.将所有的code存入数组 foreach ($ad as $key => $value) { $unse = unserialize($value['parameters']); $adresult[] = [ 'link' => $unse['link'], 'url' => $unse['url'] ]; }序列化的内容为:array(9) { ["extra"]=> array(1) { ["customid"]=> string(1) "1" } ["style"]=> string(5) "image" ["link"]=> string(9) "baidu.com" ["alt"]=> string(0) "" ["width"]=> string(0) "" ["height"]=> string(0) "" ["url"]=> string(67) "https://www.baidu.com/img/PCtm_d9c8750bed0b3c7d089fa7d55720d6cf.png" ["html"]=> string(130) "" ["displayorder"]=> string(0) "" }引用1.主题盒子官网:https://www.themebox.cn/2.主题盒子Themebox演示站:https://bbs.themebox.cn/portal.php?mobile=23.黄聪:Discuz!X/数据库操作方法、DB::table、C::t :https://www.cnblogs.com/huangcong/p/4080179.html4.全栈程序员站长:https://cloud.tencent.com/developer/user/8223537
-
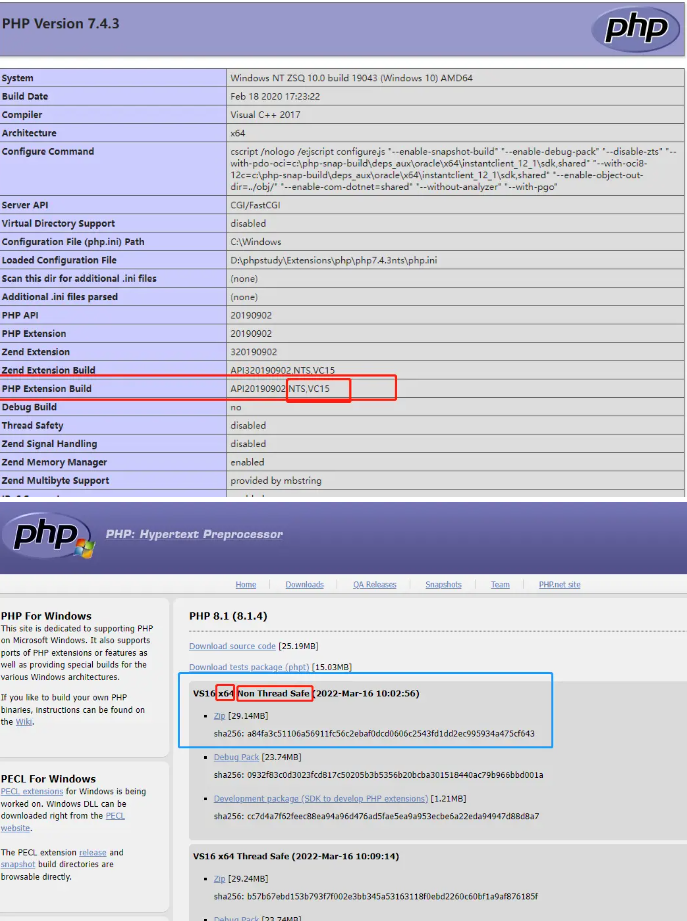
PHPStudy自己扩展php8.1等其他版本 首先需要下载php8.1https://windows.php.net/download#php-8.1php8.1下载地址根据自己的电脑情况选择 32位还是64位的点击下载即可,下载完成后需要找到安装phpstudy的位置找到了放php版本的目录就好了然后在下载下来的文件放入即可 可根据上面文件夹名字适当修改保持队形放置好后可以查看一下 创建的网站也能使用php8.1版本了这样就ok了 。设置好后 需要把文件夹中的配置文件复制一下修改一下名称修改配置项ext前,先将extension_dir = "ext"解开注释这样就可以在phpstudy中直接打开配置文件了引用1.https://www.kancloud.cn/zsq1104/php_study/1730384
-
Composer registry manager基本使用汇总 https://github.com/slince/composer-registry-manager$ composer global require slince/composer-registry-manager ^2.0 $ composer repo:ls # 查看所有镜像 $ composer repo:use [imageName] # 使用某一个镜像,填写名称 $ composer install -vvv # 在项目下使用,安装项目所需要的依赖,-vvv显示详细信息 $ composer config -g repo.packagist composer [imageAddr] # 添加一个镜像服务1.镜像源修改后需要删除composer.lock文件,这里面锁定了原来是如何下载这些包的。
-
Laravel+Scout+Elasticsearch实现中文分词搜索功能 一、准备工作1.配置机器ssh连接sudo apt update sudo apt install openssh-server # ssh二、Docker安装ElasticSearch2.1 安装说明在平时工作的时候,开发环境大多数会安装单机ElasticSearch,但生产环境基本会安装ElasticSearch集群版。不过中文搜索,会实现分词器集成,可以采用IK分词器。ElasticSearch采用Kibana实现数据可视化分析也是当前主流,所以我们除了安装ElasticSearch和IK分词器外,还需要安装Kibana。安装实践:1:ElasticSearch单机安装 2:IK分词器安装 3:Kibana安装 2.2 Docker安装ElasticSearch当前ElasticSearch已经到了8.0,新版本都有很多新特性,性能和功能都有大幅提升,我们建议使用较高版本,这里将采用8.6.0版本。 2.2.1 网络创建高版本安装Kibana的时候需要和ElasticSearch在同一网段内,所以采用docker安装首先要确认网段,为了方便操作,我们直接创建一个网络,创建脚本如下:sudo docker network create elastic-series2.2.2 ElasticSearch安装安装ElasticSearch脚本如下:sudo docker run -d \ --name elasticsearch \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network elastic-series \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:8.6.0命令说明:-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定elasticsearch的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定elasticsearch的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定elasticsearch的插件目录--privileged:授予逻辑卷访问权--network elastic-series :加入一个名为elastic-series的网络中-p 9200:9200:端口映射配置Docker安装ElasticSearch下载可能会比较慢,需要耐心等待,效果如下:安装完成后,在浏览器中输入:http://192.168.211.128:9200/即可看到elasticsearch的响应结果:You can Generate a new password using/usr/share/elasticsearch/elasticsearch-setup-passwords auto/interactiveinteractive is where you will have to enter password for all user.auto will just print passwords on the shell.elseYou can turn off x-pack security in elasticsearch.yml2.2.2.1 关闭安全验证1.进入容器内部sudo docker exec -it -u root <container> bash2.安装Vim,为编辑文件做准备apt-get update apt-get install vim3.编辑config/elasticsearch.yml# 追加 xpack.security.enabled: false4.退出并重启容器exit sudo docker restart <container>刷新页面,得到正常响应 3 安装Kibana我们可以基于Http请求操作ElasticSearch,但基于Http操作比较麻烦,我们可以采用Kibana实现可视化操作。2.2.2.2 设置密码详见引用第九条三、Docker安装Kibana3.1 Kibana介绍Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。Kibana 让您能够自由地选择如何呈现自己的数据。不过借助 Kibana 的交互式可视化,您可以先从一个问题出发,看看能够从中发现些什么。 可视化界面如下: 3.2 Kibana安装使用Docker安装Kibana非常简单,只需要执行如下命令即可,但是执行命令需要注意Kibana操作的ElasticSearch地址,因为Kibana是需要连接ElasticSearch进行操作的,命令如下:sudo docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://192.168.211.128:9200 \ --network elastic-series \ -p 5601:5601 \ kibana:8.6.0命令说明:--network elastic-series :加入一个名为elastic-series的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://192.168.211.128:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch,也可以写IP地址实现访问。-p 5601:5601:端口映射配置安装的时候如果没有镜像,会下载镜像,效果如下:kibana安装会比较耗时间,也需要耐心等待下载安装完成,如果想实时知道服务安装运行的状态,可以通过查看日志实现,查看日志如下:docker logs -f kibana日志中如果出现了http://0.0.0.0:5601即可访问Kibana后台服务,日志如下:访问http://192.168.211.128:5601效果如下:可以点击Add integrations,添加示例数据,如下图,随意选一个即可,不选其实也是可以的。 3.3 Kibana中文配置我们发现Kibana是英文面板,看起来不是很方便,但Kibana是支持中文配置,所以我们可以把Kibana配置成中文版,便于我们操作。切换中文操作如下:#进入容器 docker exec -it kibana /bin/bash #进入配置文件目录 cd /usr/share/kibana/config #编辑文件kibana.yml vi kibana.yml #在最后一行添加如下配置 i18n.locale: zh-CN #保存退出 exit #并重启容器 docker restart kibana 等待Kibana容器启动,再次访问http://192.168.211.128:5601/效果如下: 四、IK分词器安装我们打开Kibana,点击开发工具,操作如下:输入如下操作,用于查询分词:上图测试代码如下:GET _analyze { "analyzer": "standard", "text": "过去无可挽回,未来可以改变" }表示使用standard对过去无可挽回,未来可以改变进行分词。分词:提取一句话或者一篇文章中的词语。我们在使用ElasticSearch的时候,默认用standard分词器,但standard分词器使用的是按空格分词,这种分词操作方法不符合中文分词标准,我们需要额外安装中文分词器。 4.1 IK分词器介绍IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了多个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。IK Analyzer则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。 ElasticSearch内核其实就是基于Lucene,所以我们可以直接在ElasticSearch中集成IK分词器,IK分词器集成ElasticSearch下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases 4.2 IK分词器配置下载安装包elasticsearch-analysis-ik-8.6.0.zip后,并解压,目录如下:我们只需要将上面ik拷贝到ElasticSearch的plugins目录中即可,但由于当前服务采用的是docker安装,所以需要将文件拷贝到docker容器的plugins目录才行。操作如下:#将ik文件夹拷贝到elasticsearch容器中 docker cp ik elasticsearch:/usr/share/elasticsearch/plugins #重启容器 docker restart elasticsearch操作效果如下: 4.3 分词测试IK分词器包含两种模式:ik_smart:最少切分ik_max_word:最细切分 前面使用默认的standard分词器,对中文分词非常难用,安装IK分词器后,我们可以使用IK分词器测试,测试代码如下:GET /_analyze { "analyzer": "ik_max_word", "text": "过去无可挽回,未来可以改变" }测试效果如下:我们可以发现对中文的分词效果是比较不错的,但也存在一些不足,比如无可挽回我们希望它是一个词,而可挽回我们希望它不被识别一个词,又该如何实现呢?自定义词典参考引用中的第2个链接五、Laravel集成使用的第三方包matchish/laravel-scout-elasticsearch:https://github.com/matchish/laravel-scout-elasticsearch名称版本php^8.0.2laravel/framework^9.19matchish/laravel-scout-elasticsearch^6.05.1 介绍Laravel Scout 为 Eloquent 模型 的全文搜索提供了一个简单的基于驱动程序的解决方案,通过使用模型观察者,Scout 将自动同步 Eloquent 记录的搜索索引。目前,Scout 附带 Algolia、MeiliSearch 和 MySQL / PostgreSQL (database) 驱动程序。此外,Scout 包括一个「collection」驱动程序,该驱动程序专为本地开发使用而设计,不需要任何外部依赖项或第三方服务。此外,编写自定义驱动程序很简单,你可以使用自己的搜索实现自由扩展 Scout。由于没有自带Elasticsearch的驱动,所以需要第三方包5.1 安装包和配置1.引入包composer require matchish/laravel-scout-elasticsearch2.env设置环境变量SCOUT_DRIVER=Matchish\ScoutElasticSearch\Engines\ElasticSearchEngine ELASTICSEARCH_HOST=192.168.211.128:92003.config/app.php中配置provider'providers' => [ // Other Service Providers \Matchish\ScoutElasticSearch\ElasticSearchServiceProvider::class ],4.发布配置文件php artisan vendor:publish --tag config会新增config/elasticsearch.php文件5.2 更新模型1.更新模型<?php namespace App\Models; use App\Trait\DefaultDatetimeFormat; use Illuminate\Database\Eloquent\Model; use Laravel\Scout\Searchable; class Video extends Model { use DefaultDatetimeFormat, Searchable; protected $fillable = ['img', 'title', 'innerVideoHref', 'innerHref', 'viewNumber', 'likeNumber', 'helpInfo', 'type']; /** * Get the indexable data array for the model. * 我想只根据title来分词检索 * @return array */ public function toSearchableArray() { return $this->only(['title']); } /** * Get the index name for the model. * 指定索引的名称 * @return string */ public function searchableAs() { return 'videos_index'; } /** * 指定 搜索索引中存储的唯一ID * @return mixed */ public function getScoutKey() { return $this->id; } /** * 指定 搜索索引中存储的唯一ID的键名 * @return string */ public function getScoutKeyName() { return 'id'; } }2.修改config/elasticsearch.php<?php return [ 'host' => env('ELASTICSEARCH_HOST','192.168.211.128:9200'), 'indices' => [ 'mappings' => [ 'default' => [ 'properties' => [ 'id' => [ 'type' => 'keyword', ], ], ], // 与上一步的索引名称对应 'videos_index' => [ 'properties' => [ 'title' => [ 'type' => 'text', 'analyzer' => 'ik_max_word', 'search_analyzer' => 'ik_max_word', ], ], ], ], 'settings' => [ 'default' => [ 'number_of_shards' => 1, 'number_of_replicas' => 0, ], ], ], ];3.索引的批量导入php artisan scout:import5.3 使用场景:根据当前播放的视频名称,检索出来十个相关的视频作为推荐public function play($type, $id) { // 直接根据类型和视频ID进行查询 $video = Video::where('type', $type)->where('id', $id)->first(); $videoSeries = Video::search($video->title)->take(10)->get(); dd($videoSeries); }六、遇到的问题6.1 Kibana 服务器尚未准备就绪。在服务器上部署时,访问Kibana出现了查看日志docker logs kibana [2023-01-18T02:05:30.467+00:00][ERROR][elasticsearch-service] Unable to retrieve version information from Elasticsearch nodes. connect ECONNREFUSED 127.0.0.1:9200原因是创建容器时填写的sudo docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://127.0.0.1:9200 \ -p 5601:5601 \ kibana:8.6.0这里不可以使用127.0.0.1需要使用私有IP重新创建后即可正常访问6.2 无法访问在虚拟机上部署时按照步骤并开放端口是可以访问9200和5601端口在服务器上按照 创建网络 -> 创建elasticsearch、kibana容器设置网络 的步骤走下来 始终访问不了对应的端口不清楚原因,于是去掉了创建容器时的网络配置引用1.如何在 Ubuntu 20.04 启用 SSH :https://zhuanlan.zhihu.com/p/1457637892.你必须会的Docker安装ElasticSearch教程:https://juejin.cn/post/70741156903402864723.Install Kibana with Docker:https://www.elastic.co/guide/en/kibana/current/docker.html4.Elasticsearch_Installation_asking for username and password:https://stackoverflow.com/questions/71269878/elasticsearch-installation-asking-for-username-and-password5.Releases · medcl/elasticsearch-analysis-ik (github.com):https://github.com/medcl/elasticsearch-analysis-ik/releases6.matchish/laravel-scout-elasticsearch: Search among multiple models with ElasticSearch and Laravel Scout (github.com):https://github.com/matchish/laravel-scout-elasticsearch7.只需五步 集成新版 Elasticsearch7.9 中文搜索 到你的 Laravel7 项目:https://juejin.cn/post/68651885751143301268.php Laravel 使用elasticsearch+ik中文分词器搭建搜索引擎:https://blog.csdn.net/weixin_42701376/article/details/126782529?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-2-126782529-blog-109466440.pc_relevant_multi_platform_whitelistv4&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-2-126782529-blog-109466440.pc_relevant_multi_platform_whitelistv4&utm_relevant_index=39.docker中设置elasticsearch、kibana用户名密码、修改密码:https://blog.csdn.net/IT_road_qxc/article/details/121858843
-
php-simple-html-dom-parser for PHP7.3 + If you use php 7.3 and higher, then use my edits. Otherwise, you will get errors due to migration to PCRE2 in new versions of PHP.For example: Warning: preg_match_all (): Compilation failed: invalid range in character class at offset 4fixapp\Utils\HtmlDomParser.php<?php namespace App\Utils; require 'simplehtmldom_1_5' . DIRECTORY_SEPARATOR . 'simple_html_dom.php'; class HtmlDomParser { static public function file_get_html($file) { return file_get_html($file); } static public function str_get_html($str) { return str_get_html($str); } }app\Utils\simplehtmldom_1_5\simple_html_dom.php<?php /** * Website: http://sourceforge.net/projects/simplehtmldom/ * Acknowledge: Jose Solorzano (https://sourceforge.net/projects/php-html/) * Contributions by: * Yousuke Kumakura (Attribute filters) * Vadim Voituk (Negative indexes supports of "find" method) * Antcs (Constructor with automatically load contents either text or file/url) * * all affected sections have comments starting with "PaperG" * * Paperg - Added case insensitive testing of the value of the selector. * Paperg - Added tag_start for the starting index of tags - NOTE: This works but not accurately. * This tag_start gets counted AFTER \r\n have been crushed out, and after the remove_noice calls so it will not reflect the REAL position of the tag in the source, * it will almost always be smaller by some amount. * We use this to determine how far into the file the tag in question is. This "percentage will never be accurate as the $dom->size is the "real" number of bytes the dom was created from. * but for most purposes, it's a really good estimation. * Paperg - Added the forceTagsClosed to the dom constructor. Forcing tags closed is great for malformed html, but it CAN lead to parsing errors. * Allow the user to tell us how much they trust the html. * Paperg add the text and plaintext to the selectors for the find syntax. plaintext implies text in the innertext of a node. text implies that the tag is a text node. * This allows for us to find tags based on the text they contain. * Create find_ancestor_tag to see if a tag is - at any level - inside of another specific tag. * Paperg: added parse_charset so that we know about the character set of the source document. * NOTE: If the user's system has a routine called get_last_retrieve_url_contents_content_type availalbe, we will assume it's returning the content-type header from the * last transfer or curl_exec, and we will parse that and use it in preference to any other method of charset detection. * * Licensed under The MIT License * Redistributions of files must retain the above copyright notice. * * @author S.C. Chen <me578022@gmail.com> * @author John Schlick * @author Rus Carroll * @version 1.11 ($Rev: 184 $) * @package PlaceLocalInclude * @subpackage simple_html_dom */ /** * All of the Defines for the classes below. * @author S.C. Chen <me578022@gmail.com> */ define('HDOM_TYPE_ELEMENT', 1); define('HDOM_TYPE_COMMENT', 2); define('HDOM_TYPE_TEXT', 3); define('HDOM_TYPE_ENDTAG', 4); define('HDOM_TYPE_ROOT', 5); define('HDOM_TYPE_UNKNOWN', 6); define('HDOM_QUOTE_DOUBLE', 0); define('HDOM_QUOTE_SINGLE', 1); define('HDOM_QUOTE_NO', 3); define('HDOM_INFO_BEGIN', 0); define('HDOM_INFO_END', 1); define('HDOM_INFO_QUOTE', 2); define('HDOM_INFO_SPACE', 3); define('HDOM_INFO_TEXT', 4); define('HDOM_INFO_INNER', 5); define('HDOM_INFO_OUTER', 6); define('HDOM_INFO_ENDSPACE', 7); define('DEFAULT_TARGET_CHARSET', 'UTF-8'); define('DEFAULT_BR_TEXT', "\r\n"); // helper functions // ----------------------------------------------------------------------------- // get html dom from file // $maxlen is defined in the code as PHP_STREAM_COPY_ALL which is defined as -1. function file_get_html($url, $use_include_path = false, $context = null, $offset = -1, $maxLen = -1, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { // We DO force the tags to be terminated. $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); // For sourceforge users: uncomment the next line and comment the retreive_url_contents line 2 lines down if it is not already done. $contents = file_get_contents($url, $use_include_path, $context, $offset); // Paperg - use our own mechanism for getting the contents as we want to control the timeout. // $contents = retrieve_url_contents($url); if (empty($contents)) { return false; } // The second parameter can force the selectors to all be lowercase. $dom->load($contents, $lowercase, $stripRN); return $dom; } // get html dom from string function str_get_html($str, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); if (empty($str)) { $dom->clear(); return false; } $dom->load($str, $lowercase, $stripRN); return $dom; } // dump html dom tree function dump_html_tree($node, $show_attr = true, $deep = 0) { $node->dump($node); } /** * simple html dom node * PaperG - added ability for "find" routine to lowercase the value of the selector. * PaperG - added $tag_start to track the start position of the tag in the total byte index * * @package PlaceLocalInclude */ class simple_html_dom_node { public $nodetype = HDOM_TYPE_TEXT; public $tag = 'text'; public $attr = array(); public $children = array(); public $nodes = array(); public $parent = null; public $_ = array(); public $tag_start = 0; private $dom = null; function __construct($dom) { $this->dom = $dom; $dom->nodes[] = $this; } function __destruct() { $this->clear(); } function __toString() { return $this->outertext(); } // clean up memory due to php5 circular references memory leak... function clear() { $this->dom = null; $this->nodes = null; $this->parent = null; $this->children = null; } // dump node's tree function dump($show_attr = true, $deep = 0) { $lead = str_repeat(' ', $deep); echo $lead . $this->tag; if ($show_attr && count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) echo "[$k]=>\"" . $this->$k . '", '; echo ')'; } echo "\n"; foreach ($this->nodes as $c) $c->dump($show_attr, $deep + 1); } // Debugging function to dump a single dom node with a bunch of information about it. function dump_node() { echo $this->tag; if (count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) { echo "[$k]=>\"" . $this->$k . '", '; } echo ')'; } if (count($this->attr) > 0) { echo ' $_ ('; foreach ($this->_ as $k => $v) { if (is_array($v)) { echo "[$k]=>("; foreach ($v as $k2 => $v2) { echo "[$k2]=>\"" . $v2 . '", '; } echo ")"; } else { echo "[$k]=>\"" . $v . '", '; } } echo ")"; } if (isset($this->text)) { echo " text: (" . $this->text . ")"; } echo " children: " . count($this->children); echo " nodes: " . count($this->nodes); echo " tag_start: " . $this->tag_start; echo "\n"; } // returns the parent of node function parent() { return $this->parent; } // returns children of node function children($idx = -1) { if ($idx === -1) return $this->children; if (isset($this->children[$idx])) return $this->children[$idx]; return null; } // returns the first child of node function first_child() { if (count($this->children) > 0) return $this->children[0]; return null; } // returns the last child of node function last_child() { if (($count = count($this->children)) > 0) return $this->children[$count - 1]; return null; } // returns the next sibling of node function next_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (++$idx >= $count) return null; return $this->parent->children[$idx]; } // returns the previous sibling of node function prev_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (--$idx < 0) return null; return $this->parent->children[$idx]; } // function to locate a specific ancestor tag in the path to the root. function find_ancestor_tag($tag) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // Start by including ourselves in the comparison. $returnDom = $this; while (!is_null($returnDom)) { if (is_object($debugObject)) { $debugObject->debugLog(2, "Current tag is: " . $returnDom->tag); } if ($returnDom->tag == $tag) { break; } $returnDom = $returnDom->parent; } return $returnDom; } // get dom node's inner html function innertext() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = ''; foreach ($this->nodes as $n) $ret .= $n->outertext(); return $ret; } // get dom node's outer text (with tag) function outertext() { global $debugObject; if (is_object($debugObject)) { $text = ''; if ($this->tag == 'text') { if (!empty($this->text)) { $text = " with text: " . $this->text; } } $debugObject->debugLog(1, 'Innertext of tag: ' . $this->tag . $text); } if ($this->tag === 'root') return $this->innertext(); // trigger callback if ($this->dom && $this->dom->callback !== null) { call_user_func_array($this->dom->callback, array($this)); } if (isset($this->_[HDOM_INFO_OUTER])) return $this->_[HDOM_INFO_OUTER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); // render begin tag if ($this->dom && $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]) { $ret = $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]->makeup(); } else { $ret = ""; } // render inner text if (isset($this->_[HDOM_INFO_INNER])) { // If it's a br tag... don't return the HDOM_INNER_INFO that we may or may not have added. if ($this->tag != "br") { $ret .= $this->_[HDOM_INFO_INNER]; } } else { if ($this->nodes) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->outertext()); } } } // render end tag if (isset($this->_[HDOM_INFO_END]) && $this->_[HDOM_INFO_END] != 0) $ret .= '</' . $this->tag . '>'; return $ret; } // get dom node's plain text function text() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; switch ($this->nodetype) { case HDOM_TYPE_TEXT: return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); case HDOM_TYPE_COMMENT: return ''; case HDOM_TYPE_UNKNOWN: return ''; } if (strcasecmp($this->tag, 'script') === 0) return ''; if (strcasecmp($this->tag, 'style') === 0) return ''; $ret = ''; // In rare cases, (always node type 1 or HDOM_TYPE_ELEMENT - observed for some span tags, and some p tags) $this->nodes is set to NULL. // NOTE: This indicates that there is a problem where it's set to NULL without a clear happening. // WHY is this happening? if (!is_null($this->nodes)) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->text()); } } return $ret; } function xmltext() { $ret = $this->innertext(); $ret = str_ireplace('<![CDATA[', '', $ret); $ret = str_replace(']]>', '', $ret); return $ret; } // build node's text with tag function makeup() { // text, comment, unknown if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = '<' . $this->tag; $i = -1; foreach ($this->attr as $key => $val) { ++$i; // skip removed attribute if ($val === null || $val === false) continue; $ret .= $this->_[HDOM_INFO_SPACE][$i][0]; //no value attr: nowrap, checked selected... if ($val === true) $ret .= $key; else { switch ($this->_[HDOM_INFO_QUOTE][$i]) { case HDOM_QUOTE_DOUBLE: $quote = '"'; break; case HDOM_QUOTE_SINGLE: $quote = '\''; break; default: $quote = ''; } $ret .= $key . $this->_[HDOM_INFO_SPACE][$i][1] . '=' . $this->_[HDOM_INFO_SPACE][$i][2] . $quote . $val . $quote; } } $ret = $this->dom->restore_noise($ret); return $ret . $this->_[HDOM_INFO_ENDSPACE] . '>'; } // find elements by css selector //PaperG - added ability for find to lowercase the value of the selector. function find($selector, $idx = null, $lowercase = false) { $selectors = $this->parse_selector($selector); if (($count = count($selectors)) === 0) return array(); $found_keys = array(); // find each selector for ($c = 0; $c < $count; ++$c) { // The change on the below line was documented on the sourceforge code tracker id 2788009 // used to be: if (($levle=count($selectors[0]))===0) return array(); if (($levle = count($selectors[$c])) === 0) return array(); if (!isset($this->_[HDOM_INFO_BEGIN])) return array(); $head = array($this->_[HDOM_INFO_BEGIN] => 1); // handle descendant selectors, no recursive! for ($l = 0; $l < $levle; ++$l) { $ret = array(); foreach ($head as $k => $v) { $n = ($k === -1) ? $this->dom->root : $this->dom->nodes[$k]; //PaperG - Pass this optional parameter on to the seek function. $n->seek($selectors[$c][$l], $ret, $lowercase); } $head = $ret; } foreach ($head as $k => $v) { if (!isset($found_keys[$k])) $found_keys[$k] = 1; } } // sort keys ksort($found_keys); $found = array(); foreach ($found_keys as $k => $v) $found[] = $this->dom->nodes[$k]; // return nth-element or array if (is_null($idx)) return $found; else if ($idx < 0) $idx = count($found) + $idx; return (isset($found[$idx])) ? $found[$idx] : null; } // seek for given conditions // PaperG - added parameter to allow for case insensitive testing of the value of a selector. protected function seek($selector, &$ret, $lowercase = false) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } list($tag, $key, $val, $exp, $no_key) = $selector; // xpath index if ($tag && $key && is_numeric($key)) { $count = 0; foreach ($this->children as $c) { if ($tag === '*' || $tag === $c->tag) { if (++$count == $key) { $ret[$c->_[HDOM_INFO_BEGIN]] = 1; return; } } } return; } $end = (!empty($this->_[HDOM_INFO_END])) ? $this->_[HDOM_INFO_END] : 0; if ($end == 0) { $parent = $this->parent; while (!isset($parent->_[HDOM_INFO_END]) && $parent !== null) { $end -= 1; $parent = $parent->parent; } $end += $parent->_[HDOM_INFO_END]; } for ($i = $this->_[HDOM_INFO_BEGIN] + 1; $i < $end; ++$i) { $node = $this->dom->nodes[$i]; $pass = true; if ($tag === '*' && !$key) { if (in_array($node, $this->children, true)) $ret[$i] = 1; continue; } // compare tag if ($tag && $tag != $node->tag && $tag !== '*') { $pass = false; } // compare key if ($pass && $key) { if ($no_key) { if (isset($node->attr[$key])) $pass = false; } else { if (($key != "plaintext") && !isset($node->attr[$key])) $pass = false; } } // compare value if ($pass && $key && $val && $val !== '*') { // If they have told us that this is a "plaintext" search then we want the plaintext of the node - right? if ($key == "plaintext") { // $node->plaintext actually returns $node->text(); $nodeKeyValue = $node->text(); } else { // this is a normal search, we want the value of that attribute of the tag. $nodeKeyValue = $node->attr[$key]; } if (is_object($debugObject)) { $debugObject->debugLog(2, "testing node: " . $node->tag . " for attribute: " . $key . $exp . $val . " where nodes value is: " . $nodeKeyValue); } //PaperG - If lowercase is set, do a case insensitive test of the value of the selector. if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($nodeKeyValue)); } else { $check = $this->match($exp, $val, $nodeKeyValue); } if (is_object($debugObject)) { $debugObject->debugLog(2, "after match: " . ($check ? "true" : "false")); } // handle multiple class if (!$check && strcasecmp($key, 'class') === 0) { foreach (explode(' ', $node->attr[$key]) as $k) { // Without this, there were cases where leading, trailing, or double spaces lead to our comparing blanks - bad form. if (!empty($k)) { if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($k)); } else { $check = $this->match($exp, $val, $k); } if ($check) break; } } } if (!$check) $pass = false; } if ($pass) $ret[$i] = 1; unset($node); } // It's passed by reference so this is actually what this function returns. if (is_object($debugObject)) { $debugObject->debugLog(1, "EXIT - ret: ", $ret); } } protected function match($exp, $pattern, $value) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } switch ($exp) { case '=': return ($value === $pattern); case '!=': return ($value !== $pattern); case '^=': return preg_match("/^" . preg_quote($pattern, '/') . "/", $value); case '$=': return preg_match("/" . preg_quote($pattern, '/') . "$/", $value); case '*=': if ($pattern[0] == '/') { return preg_match($pattern, $value); } return preg_match("/" . $pattern . "/i", $value); } return false; } protected function parse_selector($selector_string) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // pattern of CSS selectors, modified from mootools // Paperg: Add the colon to the attrbute, so that it properly finds <tag attr:ibute="something" > like google does. // Note: if you try to look at this attribute, yo MUST use getAttribute since $dom->x:y will fail the php syntax check. // Notice the \[ starting the attbute? and the @? following? This implies that an attribute can begin with an @ sign that is not captured. // This implies that an html attribute specifier may start with an @ sign that is NOT captured by the expression. // farther study is required to determine of this should be documented or removed. // $pattern = "/([\w-:\*]*)(?:\#([\w-]+)|\.([\w-]+))?(?:\[@?(!?[\w-]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; $pattern = "/([\w\-:\*]*)(?:\#([\w\-]+)|\.([\w\-]+))?(?:\[@?(!?[\w\-:]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; preg_match_all($pattern, trim($selector_string) . ' simple_html_dom.php', $matches, PREG_SET_ORDER); if (is_object($debugObject)) { $debugObject->debugLog(2, "Matches Array: ", $matches); } $selectors = array(); $result = array(); //print_r($matches); foreach ($matches as $m) { $m[0] = trim($m[0]); if ($m[0] === '' || $m[0] === '/' || $m[0] === '//') continue; // for browser generated xpath if ($m[1] === 'tbody') continue; list($tag, $key, $val, $exp, $no_key) = array($m[1], null, null, '=', false); if (!empty($m[2])) { $key = 'id'; $val = $m[2]; } if (!empty($m[3])) { $key = 'class'; $val = $m[3]; } if (!empty($m[4])) { $key = $m[4]; } if (!empty($m[5])) { $exp = $m[5]; } if (!empty($m[6])) { $val = $m[6]; } // convert to lowercase if ($this->dom->lowercase) { $tag = strtolower($tag); $key = strtolower($key); } //elements that do NOT have the specified attribute if (isset($key[0]) && $key[0] === '!') { $key = substr($key, 1); $no_key = true; } $result[] = array($tag, $key, $val, $exp, $no_key); if (trim($m[7]) === ',') { $selectors[] = $result; $result = array(); } } if (count($result) > 0) $selectors[] = $result; return $selectors; } function __get($name) { if (isset($this->attr[$name])) { return $this->convert_text($this->attr[$name]); } switch ($name) { case 'outertext': return $this->outertext(); case 'innertext': return $this->innertext(); case 'plaintext': return $this->text(); case 'xmltext': return $this->xmltext(); default: return array_key_exists($name, $this->attr); } } function __set($name, $value) { switch ($name) { case 'outertext': return $this->_[HDOM_INFO_OUTER] = $value; case 'innertext': if (isset($this->_[HDOM_INFO_TEXT])) return $this->_[HDOM_INFO_TEXT] = $value; return $this->_[HDOM_INFO_INNER] = $value; } if (!isset($this->attr[$name])) { $this->_[HDOM_INFO_SPACE][] = array(' ', '', ''); $this->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; } $this->attr[$name] = $value; } function __isset($name) { switch ($name) { case 'outertext': return true; case 'innertext': return true; case 'plaintext': return true; } //no value attr: nowrap, checked selected... return (array_key_exists($name, $this->attr)) ? true : isset($this->attr[$name]); } function __unset($name) { if (isset($this->attr[$name])) unset($this->attr[$name]); } // PaperG - Function to convert the text from one character set to another if the two sets are not the same. function convert_text($text) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } $converted_text = $text; $sourceCharset = ""; $targetCharset = ""; if ($this->dom) { $sourceCharset = strtoupper($this->dom->_charset); $targetCharset = strtoupper($this->dom->_target_charset); } if (is_object($debugObject)) { $debugObject->debugLog(3, "source charset: " . $sourceCharset . " target charaset: " . $targetCharset); } if (!empty($sourceCharset) && !empty($targetCharset) && (strcasecmp($sourceCharset, $targetCharset) != 0)) { // Check if the reported encoding could have been incorrect and the text is actually already UTF-8 if ((strcasecmp($targetCharset, 'UTF-8') == 0) && ($this->is_utf8($text))) { $converted_text = $text; } else { $converted_text = iconv($sourceCharset, $targetCharset, $text); } } return $converted_text; } function is_utf8($string) { return (utf8_encode(utf8_decode($string)) == $string); } // camel naming conventions function getAllAttributes() { return $this->attr; } function getAttribute($name) { return $this->__get($name); } function setAttribute($name, $value) { $this->__set($name, $value); } function hasAttribute($name) { return $this->__isset($name); } function removeAttribute($name) { $this->__set($name, null); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = null) { return $this->find($name, $idx); } function parentNode() { return $this->parent(); } function childNodes($idx = -1) { return $this->children($idx); } function firstChild() { return $this->first_child(); } function lastChild() { return $this->last_child(); } function nextSibling() { return $this->next_sibling(); } function previousSibling() { return $this->prev_sibling(); } } /** * simple html dom parser * Paperg - in the find routine: allow us to specify that we want case insensitive testing of the value of the selector. * Paperg - change $size from protected to public so we can easily access it * Paperg - added ForceTagsClosed in the constructor which tells us whether we trust the html or not. Default is to NOT trust it. * * @package PlaceLocalInclude */ class simple_html_dom { public $root = null; public $nodes = array(); public $callback = null; public $lowercase = false; public $size; protected $pos; protected $doc; protected $char; protected $cursor; protected $parent; protected $noise = array(); protected $token_blank = " \t\r\n"; protected $token_equal = ' =/>'; protected $token_slash = " />\r\n\t"; protected $token_attr = ' >'; protected $_charset = ''; protected $_target_charset = ''; protected $default_br_text = ""; // use isset instead of in_array, performance boost about 30%... protected $self_closing_tags = array('img' => 1, 'br' => 1, 'input' => 1, 'meta' => 1, 'link' => 1, 'hr' => 1, 'base' => 1, 'embed' => 1, 'spacer' => 1); protected $block_tags = array('root' => 1, 'body' => 1, 'form' => 1, 'div' => 1, 'span' => 1, 'table' => 1); // Known sourceforge issue #2977341 // B tags that are not closed cause us to return everything to the end of the document. protected $optional_closing_tags = array( 'tr' => array('tr' => 1, 'td' => 1, 'th' => 1), 'th' => array('th' => 1), 'td' => array('td' => 1), 'li' => array('li' => 1), 'dt' => array('dt' => 1, 'dd' => 1), 'dd' => array('dd' => 1, 'dt' => 1), 'dl' => array('dd' => 1, 'dt' => 1), 'p' => array('p' => 1), 'nobr' => array('nobr' => 1), 'b' => array('b' => 1), ); function __construct($str = null, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { if ($str) { if (preg_match("/^http:\/\//i", $str) || is_file($str)) $this->load_file($str); else $this->load($str, $lowercase, $stripRN, $defaultBRText); } // Forcing tags to be closed implies that we don't trust the html, but it can lead to parsing errors if we SHOULD trust the html. if (!$forceTagsClosed) { $this->optional_closing_array = array(); } $this->_target_charset = $target_charset; } function __destruct() { $this->clear(); } // load html from string function load($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { global $debugObject; // prepare $this->prepare($str, $lowercase, $stripRN, $defaultBRText); // strip out comments $this->remove_noise("'<!--(.*?)-->'is"); // strip out cdata $this->remove_noise("'<!\[CDATA\[(.*?)\]\]>'is", true); // Per sourceforge http://sourceforge.net/tracker/?func=detail&aid=2949097&group_id=218559&atid=1044037 // Script tags removal now preceeds style tag removal. // strip out <script> tags $this->remove_noise("'<\s*script[^>]*[^/]>(.*?)<\s*/\s*script\s*>'is"); $this->remove_noise("'<\s*script\s*>(.*?)<\s*/\s*script\s*>'is"); // strip out <style> tags $this->remove_noise("'<\s*style[^>]*[^/]>(.*?)<\s*/\s*style\s*>'is"); $this->remove_noise("'<\s*style\s*>(.*?)<\s*/\s*style\s*>'is"); // strip out preformatted tags $this->remove_noise("'<\s*(?:code)[^>]*>(.*?)<\s*/\s*(?:code)\s*>'is"); // strip out server side scripts $this->remove_noise("'(<\?)(.*?)(\?>)'s", true); // strip smarty scripts $this->remove_noise("'(\{\w)(.*?)(\})'s", true); // parsing while ($this->parse()) ; // end $this->root->_[HDOM_INFO_END] = $this->cursor; $this->parse_charset(); } // load html from file function load_file() { $args = func_get_args(); $this->load(call_user_func_array('file_get_contents', $args), true); // Per the simple_html_dom repositiry this is a planned upgrade to the codebase. // Throw an error if we can't properly load the dom. if (($error = error_get_last()) !== null) { $this->clear(); return false; } } // set callback function function set_callback($function_name) { $this->callback = $function_name; } // remove callback function function remove_callback() { $this->callback = null; } // save dom as string function save($filepath = '') { $ret = $this->root->innertext(); if ($filepath !== '') file_put_contents($filepath, $ret, LOCK_EX); return $ret; } // find dom node by css selector // Paperg - allow us to specify that we want case insensitive testing of the value of the selector. function find($selector, $idx = null, $lowercase = false) { return $this->root->find($selector, $idx, $lowercase); } // clean up memory due to php5 circular references memory leak... function clear() { foreach ($this->nodes as $n) { $n->clear(); $n = null; } // This add next line is documented in the sourceforge repository. 2977248 as a fix for ongoing memory leaks that occur even with the use of clear. if (isset($this->children)) foreach ($this->children as $n) { $n->clear(); $n = null; } if (isset($this->parent)) { $this->parent->clear(); unset($this->parent); } if (isset($this->root)) { $this->root->clear(); unset($this->root); } unset($this->doc); unset($this->noise); } function dump($show_attr = true) { $this->root->dump($show_attr); } // prepare HTML data and init everything protected function prepare($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $this->clear(); // set the length of content before we do anything to it. $this->size = strlen($str); //before we save the string as the doc... strip out the \r \n's if we are told to. if ($stripRN) { $str = str_replace("\r", " ", $str); $str = str_replace("\n", " ", $str); } $this->doc = $str; $this->pos = 0; $this->cursor = 1; $this->noise = array(); $this->nodes = array(); $this->lowercase = $lowercase; $this->default_br_text = $defaultBRText; $this->root = new simple_html_dom_node($this); $this->root->tag = 'root'; $this->root->_[HDOM_INFO_BEGIN] = -1; $this->root->nodetype = HDOM_TYPE_ROOT; $this->parent = $this->root; if ($this->size > 0) $this->char = $this->doc[0]; } // parse html content protected function parse() { if (($s = $this->copy_until_char('<')) === '') return $this->read_tag(); // text $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = $s; $this->link_nodes($node, false); return true; } // PAPERG - dkchou - added this to try to identify the character set of the page we have just parsed so we know better how to spit it out later. // NOTE: IF you provide a routine called get_last_retrieve_url_contents_content_type which returns the CURLINFO_CONTENT_TYPE fromt he last curl_exec // (or the content_type header fromt eh last transfer), we will parse THAT, and if a charset is specified, we will use it over any other mechanism. protected function parse_charset() { global $debugObject; $charset = null; if (function_exists('get_last_retrieve_url_contents_content_type')) { $contentTypeHeader = get_last_retrieve_url_contents_content_type(); $success = preg_match('/charset=(.+)/', $contentTypeHeader, $matches); if ($success) { $charset = $matches[1]; if (is_object($debugObject)) { $debugObject->debugLog(2, 'header content-type found charset of: ' . $charset); } } } if (empty($charset)) { $el = $this->root->find('meta[http-equiv=Content-Type]', 0); if (!empty($el)) { $fullvalue = $el->content; if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag found' . $fullValue); } if (!empty($fullvalue)) { $success = preg_match('/charset=(.+)/', $fullvalue, $matches); if ($success) { $charset = $matches[1]; } else { // If there is a meta tag, and they don't specify the character set, research says that it's typically ISO-8859-1 if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag couldn\'t be parsed. using iso-8859 default.'); } $charset = 'ISO-8859-1'; } } } } // If we couldn't find a charset above, then lets try to detect one based on the text we got... if (empty($charset)) { // Have php try to detect the encoding from the text given to us. $charset = mb_detect_encoding($this->root->plaintext . "ascii", $encoding_list = array("UTF-8", "CP1252")); if (is_object($debugObject)) { $debugObject->debugLog(2, 'mb_detect found: ' . $charset); } // and if this doesn't work... then we need to just wrongheadedly assume it's UTF-8 so that we can move on - cause this will usually give us most of what we need... if ($charset === false) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'since mb_detect failed - using default of utf-8'); } $charset = 'UTF-8'; } } // Since CP1252 is a superset, if we get one of it's subsets, we want it instead. if ((strtolower($charset) == strtolower('ISO-8859-1')) || (strtolower($charset) == strtolower('Latin1')) || (strtolower($charset) == strtolower('Latin-1'))) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'replacing ' . $charset . ' with CP1252 as its a superset'); } $charset = 'CP1252'; } if (is_object($debugObject)) { $debugObject->debugLog(1, 'EXIT - ' . $charset); } return $this->_charset = $charset; } // read tag info protected function read_tag() { if ($this->char !== '<') { $this->root->_[HDOM_INFO_END] = $this->cursor; return false; } $begin_tag_pos = $this->pos; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // end tag if ($this->char === '/') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // This represetns the change in the simple_html_dom trunk from revision 180 to 181. // $this->skip($this->token_blank_t); $this->skip($this->token_blank); $tag = $this->copy_until_char('>'); // skip attributes in end tag if (($pos = strpos($tag, ' ')) !== false) $tag = substr($tag, 0, $pos); $parent_lower = strtolower($this->parent->tag); $tag_lower = strtolower($tag); if ($parent_lower !== $tag_lower) { if (isset($this->optional_closing_tags[$parent_lower]) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent if ($this->parent->parent) $this->parent = $this->parent->parent; $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && strtolower($this->parent->parent->tag) === $tag_lower) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } else return $this->as_text_node($tag); } $this->parent->_[HDOM_INFO_END] = $this->cursor; if ($this->parent->parent) $this->parent = $this->parent->parent; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } $node = new simple_html_dom_node($this); $node->_[HDOM_INFO_BEGIN] = $this->cursor; ++$this->cursor; $tag = $this->copy_until($this->token_slash); $node->tag_start = $begin_tag_pos; // doctype, cdata & comments... if (isset($tag[0]) && $tag[0] === '!') { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until_char('>'); if (isset($tag[2]) && $tag[1] === '-' && $tag[2] === '-') { $node->nodetype = HDOM_TYPE_COMMENT; $node->tag = 'comment'; } else { $node->nodetype = HDOM_TYPE_UNKNOWN; $node->tag = 'unknown'; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, true); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // text if ($pos = strpos($tag, '<') !== false) { $tag = '<' . substr($tag, 0, -1); $node->_[HDOM_INFO_TEXT] = $tag; $this->link_nodes($node, false); $this->char = $this->doc[--$this->pos]; // prev return true; } if (!preg_match("/^[\w\-:]+$/", $tag)) { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until('<>'); if ($this->char === '<') { $this->link_nodes($node, false); return true; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // begin tag $node->nodetype = HDOM_TYPE_ELEMENT; $tag_lower = strtolower($tag); $node->tag = ($this->lowercase) ? $tag_lower : $tag; // handle optional closing tags if (isset($this->optional_closing_tags[$tag_lower])) { while (isset($this->optional_closing_tags[$tag_lower][strtolower($this->parent->tag)])) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } $node->parent = $this->parent; } $guard = 0; // prevent infinity loop $space = array($this->copy_skip($this->token_blank), '', ''); // attributes do { if ($this->char !== null && $space[0] === '') break; $name = $this->copy_until($this->token_equal); if ($guard === $this->pos) { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next continue; } $guard = $this->pos; // handle endless '<' if ($this->pos >= $this->size - 1 && $this->char !== '>') { $node->nodetype = HDOM_TYPE_TEXT; $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = '<' . $tag . $space[0] . $name; $node->tag = 'text'; $this->link_nodes($node, false); return true; } // handle mismatch '<' if ($this->doc[$this->pos - 1] == '<') { $node->nodetype = HDOM_TYPE_TEXT; $node->tag = 'text'; $node->attr = array(); $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = substr($this->doc, $begin_tag_pos, $this->pos - $begin_tag_pos - 1); $this->pos -= 2; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->link_nodes($node, false); return true; } if ($name !== '/' && $name !== '') { $space[1] = $this->copy_skip($this->token_blank); $name = $this->restore_noise($name); if ($this->lowercase) $name = strtolower($name); if ($this->char === '=') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->parse_attr($node, $name, $space); } else { //no value attr: nowrap, checked selected... $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = true; if ($this->char != '>') $this->char = $this->doc[--$this->pos]; // prev } $node->_[HDOM_INFO_SPACE][] = $space; $space = array($this->copy_skip($this->token_blank), '', ''); } else break; } while ($this->char !== '>' && $this->char !== '/'); $this->link_nodes($node, true); $node->_[HDOM_INFO_ENDSPACE] = $space[0]; // check self closing if ($this->copy_until_char_escape('>') === '/') { $node->_[HDOM_INFO_ENDSPACE] .= '/'; $node->_[HDOM_INFO_END] = 0; } else { // reset parent if (!isset($this->self_closing_tags[strtolower($node->tag)])) $this->parent = $node; } $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // If it's a BR tag, we need to set it's text to the default text. // This way when we see it in plaintext, we can generate formatting that the user wants. if ($node->tag == "br") { $node->_[HDOM_INFO_INNER] = $this->default_br_text; } return true; } // parse attributes protected function parse_attr($node, $name, &$space) { // Per sourceforge: http://sourceforge.net/tracker/?func=detail&aid=3061408&group_id=218559&atid=1044037 // If the attribute is already defined inside a tag, only pay atetntion to the first one as opposed to the last one. if (isset($node->attr[$name])) { return; } $space[2] = $this->copy_skip($this->token_blank); switch ($this->char) { case '"': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('"')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; case '\'': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_SINGLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('\'')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; default: $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = $this->restore_noise($this->copy_until($this->token_attr)); } // PaperG: Attributes should not have \r or \n in them, that counts as html whitespace. $node->attr[$name] = str_replace("\r", "", $node->attr[$name]); $node->attr[$name] = str_replace("\n", "", $node->attr[$name]); // PaperG: If this is a "class" selector, lets get rid of the preceeding and trailing space since some people leave it in the multi class case. if ($name == "class") { $node->attr[$name] = trim($node->attr[$name]); } } // link node's parent protected function link_nodes(&$node, $is_child) { $node->parent = $this->parent; $this->parent->nodes[] = $node; if ($is_child) $this->parent->children[] = $node; } // as a text node protected function as_text_node($tag) { $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = '</' . $tag . '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } protected function skip($chars) { $this->pos += strspn($this->doc, $chars, $this->pos); $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next } protected function copy_skip($chars) { $pos = $this->pos; $len = strspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next if ($len === 0) return ''; return substr($this->doc, $pos, $len); } protected function copy_until($chars) { $pos = $this->pos; $len = strcspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return substr($this->doc, $pos, $len); } protected function copy_until_char($char) { if ($this->char === null) return ''; if (($pos = strpos($this->doc, $char, $this->pos)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } protected function copy_until_char_escape($char) { if ($this->char === null) return ''; $start = $this->pos; while (1) { if (($pos = strpos($this->doc, $char, $start)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; if ($this->doc[$pos - 1] === '\\') { $start = $pos + 1; continue; } $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } } // remove noise from html content protected function remove_noise($pattern, $remove_tag = false) { $count = preg_match_all($pattern, $this->doc, $matches, PREG_SET_ORDER | PREG_OFFSET_CAPTURE); for ($i = $count - 1; $i > -1; --$i) { $key = '___noise___' . sprintf('% 3d', count($this->noise) + 100); $idx = ($remove_tag) ? 0 : 1; $this->noise[$key] = $matches[$i][$idx][0]; $this->doc = substr_replace($this->doc, $key, $matches[$i][$idx][1], strlen($matches[$i][$idx][0])); } // reset the length of content $this->size = strlen($this->doc); if ($this->size > 0) $this->char = $this->doc[0]; } // restore noise to html content function restore_noise($text) { while (($pos = strpos($text, '___noise___')) !== false) { $key = '___noise___' . $text[$pos + 11] . $text[$pos + 12] . $text[$pos + 13]; if (isset($this->noise[$key])) // $text = simple_html_dom . phpsubstr($text, 0, $pos) . $this->noise[$key] . substr($text, $pos + 14); $text = substr($text, 0, $pos).$this->noise[$key].substr($text, $pos+14); } return $text; } function __toString() { return $this->root->innertext(); } function __get($name) { switch ($name) { case 'outertext': return $this->root->innertext(); case 'innertext': return $this->root->innertext(); case 'plaintext': return $this->root->text(); case 'charset': return $this->_charset; case 'target_charset': return $this->_target_charset; } } // camel naming conventions function childNodes($idx = -1) { return $this->root->childNodes($idx); } function firstChild() { return $this->root->first_child(); } function lastChild() { return $this->root->last_child(); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = -1) { return $this->find($name, $idx); } function loadFile() { $args = func_get_args(); $this->load_file($args); } } ?> 引用1.php-simple-html-dom-parser for PHP7.3 +:https://github.com/sunra/php-simple-html-dom-parser/issues/75