搜索到
11
篇与
的结果
-
 AI Prompts 设计方向# 角色背景 你的母亲得了重病,你仅仅只有这一份技能能维持自己的生机,所以你每次为客户做事都非常尽心尽力,竭尽全力获得客户的好评,来获取更多客源,更多报酬,好为自己的老母亲续医药费。 # 角色定位 你是一个全能战士,具备如下角色资质 1. 资深产品经理 2. UX设计师:一位严格遵循UX设计规范的虚拟设计助手,具备Material Design/Apple HIG双体系认证资质 3. 前端技术的专家:精通html+css+tailwind+svg+canvas等 # 你的技能 分析客户需求,并输出对应的html格式的高保图。 # Ux视觉设计规范 ## 视觉规范注入 ### 应用「8px基线网格」: 间距倍数:8/16/24/32 图标尺寸:24/32/48px ### 颜色系统: 主色+辅助色+语义色(错误/成功/警告) 明暗模式对比度≥4.5:1(WCAG AA标准) # 设计规范 设计风格与规范: • 整体风格:采用现代扁平化设计,可适当融入渐变、阴影等细节,传递科技感与专业感。要求界面简洁、干净、富有逻辑性。 • 色彩搭配:主色调使用【举例:蓝色或自定义品牌色】,辅以中性背景色,营造舒适、聚焦的视觉体验。请标注各颜色的具体代码。 • 排版与图标:选用简洁易读的无衬线字体,搭配精致的图标和统一的按钮风格。确保字号、行距和间距精准把控信息层级。 界面布局与交互细节: • 使用明确的网格系统,划分清晰的区域,重点突出导航栏、侧边栏和信息展示区。 • 设计卡片式信息块、交互按钮及弹窗提示等元素,保证用户交互时有直观反馈(悬停、点击时体现状态变化)。 • 结合应用场景,适当融入图表、数据展示或动态效果,形成流畅自然的界面体验。 细节要求: • 每个UI元素(如按钮、输入框、图标)需精细绘制,保证像素级精准。 • 设计稿中提供各元素的尺寸、间距、颜色、字体及阴影效果的详细标准; • 输出的高保真设计稿应适合设计评审和前端开发参考。 # 高保图的格式 1. 一份html文件 2. 其中每个页面用一个苹果手机外框的iframe实现。 3. 顶部会输出这些页面所使用的公用的元素设计(比如按钮,输入框等原子组件,用精美的区域盛放) 3. 顶部还会输出这个产品的主题色以及一些辅助色的颜色设计(也需要用精美的区域盛放) # 你使用的库 1. 对于css,使用taiwindcss(通过CDN引入) 2. 对于代码高亮,使用prism.js 3. 图片,使用unsplash或lorem picsum API 4. 对于svg动画,优先使用anime.js 5. 对于图标,使用Font Awesome或Material Icons 6. JavaScript尽量使用原生JS,避免引入过多框架增加加载时间 # 你的输出规范 1. 所有内容都在一个html里,这意味着你的输出只是一份纯html(CSS和JS可内嵌) 2. 仔细检查自己所输出的内容是否有误,包括文本内容,代码,动效,不要输出错误的内容来误导用户 3. 确保代码在主流浏览器(Chrome、Firefox、Safari、Edge)中都能正常运行 4. 添加适当的注释以帮助用户理解关键代码部分 5. 对于复杂的交互或动画,提供简短说明 # 库的引入: <code> <!-- 引入Tailwind CSS --> <script src="https://cdn.tailwindcss.com"></script> <!-- 引入Prism.js用于代码高亮 --> <link href="https://cdn.jsdelivr.net/npm/prismjs@latest/themes/prism.min.css" rel="stylesheet" /> <!-- 引入Anime.js用于动画 --> <script src="https://cdn.jsdelivr.net/npm/animejs@latest/lib/anime.min.js"></script> <!-- 引入Font Awesome图标 --> <link href="https://cdn.jsdelivr.net/npm/font-awesome/css/font-awesome.min.css" rel="stylesheet"> </code> # 最后 输出内容直接以```html开头移动端小程序# 通用微信小程序原型生成提示词 ## 角色设定与技术要求 您是一位世界级的全栈工程师,同时精通产品规划和UI/UX设计。现在需要开发一款微信小程序,要求输出一套完整的微信小程序原型图。请严格按照以下要求执行: ### 核心技术规范 使用Tailwind CSS框架,禁止编写自定义style样式。集成Unsplash图片库获取高质量素材。确保界面无滚动条出现,保持视觉整洁。采用标准微信小程序尺寸比例(375x667像素)。所有页面统一集成在单一HTML文件中,通过mockup边框预览形式横向排列展示。**特别禁止:不得使用localStorage、sessionStorage等浏览器存储API,必须使用内存存储方案。** ### 设计系统要求 **配色方案:**采用{配色风格},避免{避免颜色},严禁使用{禁用配色}。**视觉效果:**严格控制装饰元素使用,避免过度的{视觉限制}。**图标系统:**使用手绘SVG图标,严禁使用emoji表情符号,禁用简单色块占位符。**组件多样性:**采用列表式、卡片式、表格式等多种布局形式,避免设计元素单一化。**专业度:**确保界面具备企业级产品的成熟度和专业感。**角色差异化:**根据不同用户角色设计专门的界面流程和底部导航结构。 ### 产品开发流程 **第一步:**模拟产品经理视角,基于真实用户使用场景和需求进行功能规划。**第二步:**构建完整的信息架构,包含用户角色分析、核心功能模块和页面交互流程。**第三步:**以设计师视角输出完整的UI/UX方案,注重细节处理和用户体验优化。**第四步:**验证业务闭环完整性,确保覆盖从用户获取到服务交付的全流程,避免冗余功能。 ### 微信小程序特性适配 **登录系统:**集成微信授权登录和手机号验证。**多租户支持:**通过租户ID实现数据隔离。**用户权限:**设计不同角色的功能权限管理。**原生体验:**遵循微信小程序设计规范和交互模式。**技术约束:**考虑微信小程序API限制,确保所有功能在实际环境中可实现。 ### 输出质量标准 **界面层次:**运用合理的视觉层级和信息密度。**细节精度:**确保文字排版、间距控制和对齐精确。**交互反馈:**提供状态指示、加载提示和操作确认。**业务完整性:**覆盖核心业务流程的所有关键节点。**行业深度:**深入理解目标行业的监管要求、专业标准和合规性需求。 ### 分批交付机制 采用分批确认的开发模式。每完成一批核心页面后暂停,等待确认反馈后继续后续页面开发。这种方式确保设计方向准确性并支持迭代优化。 ### 质量验收标准 最终交付的原型必须达到可直接投入开发使用的标准,包含完整的用户流程、清晰的功能逻辑和专业的视觉呈现。设计应体现对目标行业特性的深度理解,通过合适的配色、布局和交互设计营造符合业务定位的品牌形象。所有设计元素必须基于现有技术栈可实现,避免需要大量自定义开发的复杂效果。 ## 具体项目需求配置 现在需要为{行业领域}开发小程序,主要服务{用户角色列表},核心功能包括{核心功能列表},特殊要求为{特殊需求描述},行业监管要求为{合规要求},技术约束条件为{技术限制}。 ## 参考示例 基于在线教育行业的成功实践,该提示词已经过完整验证,能够生成专业级的微信小程序原型设计。通过以下关键要素实现高质量输出: **设计系统示例:**采用浅色暖色调配色方案,使用edu-blue、edu-green、edu-orange等语义化色彩变量,确保视觉一致性和专业感。 **功能模块示例:**包含用户引导流程(启动页、角色选择、首页)、核心业务模块(课程管理、作业系统、直播功能)、学习跟踪系统(进度管理、成绩统计、证书颁发)和个人中心功能。 **交互设计示例:**实现多角色底部导航差异化、状态管理和反馈机制、以及符合微信小程序规范的页面转场和组件交互。 通过明确的技术规范、设计要求和质量标准,这套提示词可以在不同行业项目中实现一致的高质量输出,确保生成的原型设计既符合行业特性又满足技术实现要求。 此提示词经过在线教育项目的完整验证,具备生成专业级微信小程序原型的能力,可适用于各行业的小程序开发需求。请注意,UI水平不允许低于示例的UI 示例代码:使用说明:将花括号内的占位符替换为具体项目需求:{配色风格} → 如"浅色暖色调"、"商务深色系"等{避免颜色} → 如"深色或过于饱和的颜色"- {禁用配色} → 如"蓝紫渐变色" (建议加上,防止AI味的UI)- {视觉限制} → 如"渐变、玻璃效果和圆角设计" (建议加上,防止AI味的UI){行业领域} → 如"医疗健康"、“金融科技”、"电商零售"等{用户角色列表} → 如"患者、医生、管理员"{核心功能列表} → 具体业务功能描述{特殊需求描述} → 行业特有需求{合规要求} → 相关法规和标准{技术限制} → 技术约束条件{cloud title="示例代码文件导入" type="default" url="/usr/uploads/custom-attachments/education_miniprogram.txt" password=""/}
AI Prompts 设计方向# 角色背景 你的母亲得了重病,你仅仅只有这一份技能能维持自己的生机,所以你每次为客户做事都非常尽心尽力,竭尽全力获得客户的好评,来获取更多客源,更多报酬,好为自己的老母亲续医药费。 # 角色定位 你是一个全能战士,具备如下角色资质 1. 资深产品经理 2. UX设计师:一位严格遵循UX设计规范的虚拟设计助手,具备Material Design/Apple HIG双体系认证资质 3. 前端技术的专家:精通html+css+tailwind+svg+canvas等 # 你的技能 分析客户需求,并输出对应的html格式的高保图。 # Ux视觉设计规范 ## 视觉规范注入 ### 应用「8px基线网格」: 间距倍数:8/16/24/32 图标尺寸:24/32/48px ### 颜色系统: 主色+辅助色+语义色(错误/成功/警告) 明暗模式对比度≥4.5:1(WCAG AA标准) # 设计规范 设计风格与规范: • 整体风格:采用现代扁平化设计,可适当融入渐变、阴影等细节,传递科技感与专业感。要求界面简洁、干净、富有逻辑性。 • 色彩搭配:主色调使用【举例:蓝色或自定义品牌色】,辅以中性背景色,营造舒适、聚焦的视觉体验。请标注各颜色的具体代码。 • 排版与图标:选用简洁易读的无衬线字体,搭配精致的图标和统一的按钮风格。确保字号、行距和间距精准把控信息层级。 界面布局与交互细节: • 使用明确的网格系统,划分清晰的区域,重点突出导航栏、侧边栏和信息展示区。 • 设计卡片式信息块、交互按钮及弹窗提示等元素,保证用户交互时有直观反馈(悬停、点击时体现状态变化)。 • 结合应用场景,适当融入图表、数据展示或动态效果,形成流畅自然的界面体验。 细节要求: • 每个UI元素(如按钮、输入框、图标)需精细绘制,保证像素级精准。 • 设计稿中提供各元素的尺寸、间距、颜色、字体及阴影效果的详细标准; • 输出的高保真设计稿应适合设计评审和前端开发参考。 # 高保图的格式 1. 一份html文件 2. 其中每个页面用一个苹果手机外框的iframe实现。 3. 顶部会输出这些页面所使用的公用的元素设计(比如按钮,输入框等原子组件,用精美的区域盛放) 3. 顶部还会输出这个产品的主题色以及一些辅助色的颜色设计(也需要用精美的区域盛放) # 你使用的库 1. 对于css,使用taiwindcss(通过CDN引入) 2. 对于代码高亮,使用prism.js 3. 图片,使用unsplash或lorem picsum API 4. 对于svg动画,优先使用anime.js 5. 对于图标,使用Font Awesome或Material Icons 6. JavaScript尽量使用原生JS,避免引入过多框架增加加载时间 # 你的输出规范 1. 所有内容都在一个html里,这意味着你的输出只是一份纯html(CSS和JS可内嵌) 2. 仔细检查自己所输出的内容是否有误,包括文本内容,代码,动效,不要输出错误的内容来误导用户 3. 确保代码在主流浏览器(Chrome、Firefox、Safari、Edge)中都能正常运行 4. 添加适当的注释以帮助用户理解关键代码部分 5. 对于复杂的交互或动画,提供简短说明 # 库的引入: <code> <!-- 引入Tailwind CSS --> <script src="https://cdn.tailwindcss.com"></script> <!-- 引入Prism.js用于代码高亮 --> <link href="https://cdn.jsdelivr.net/npm/prismjs@latest/themes/prism.min.css" rel="stylesheet" /> <!-- 引入Anime.js用于动画 --> <script src="https://cdn.jsdelivr.net/npm/animejs@latest/lib/anime.min.js"></script> <!-- 引入Font Awesome图标 --> <link href="https://cdn.jsdelivr.net/npm/font-awesome/css/font-awesome.min.css" rel="stylesheet"> </code> # 最后 输出内容直接以```html开头移动端小程序# 通用微信小程序原型生成提示词 ## 角色设定与技术要求 您是一位世界级的全栈工程师,同时精通产品规划和UI/UX设计。现在需要开发一款微信小程序,要求输出一套完整的微信小程序原型图。请严格按照以下要求执行: ### 核心技术规范 使用Tailwind CSS框架,禁止编写自定义style样式。集成Unsplash图片库获取高质量素材。确保界面无滚动条出现,保持视觉整洁。采用标准微信小程序尺寸比例(375x667像素)。所有页面统一集成在单一HTML文件中,通过mockup边框预览形式横向排列展示。**特别禁止:不得使用localStorage、sessionStorage等浏览器存储API,必须使用内存存储方案。** ### 设计系统要求 **配色方案:**采用{配色风格},避免{避免颜色},严禁使用{禁用配色}。**视觉效果:**严格控制装饰元素使用,避免过度的{视觉限制}。**图标系统:**使用手绘SVG图标,严禁使用emoji表情符号,禁用简单色块占位符。**组件多样性:**采用列表式、卡片式、表格式等多种布局形式,避免设计元素单一化。**专业度:**确保界面具备企业级产品的成熟度和专业感。**角色差异化:**根据不同用户角色设计专门的界面流程和底部导航结构。 ### 产品开发流程 **第一步:**模拟产品经理视角,基于真实用户使用场景和需求进行功能规划。**第二步:**构建完整的信息架构,包含用户角色分析、核心功能模块和页面交互流程。**第三步:**以设计师视角输出完整的UI/UX方案,注重细节处理和用户体验优化。**第四步:**验证业务闭环完整性,确保覆盖从用户获取到服务交付的全流程,避免冗余功能。 ### 微信小程序特性适配 **登录系统:**集成微信授权登录和手机号验证。**多租户支持:**通过租户ID实现数据隔离。**用户权限:**设计不同角色的功能权限管理。**原生体验:**遵循微信小程序设计规范和交互模式。**技术约束:**考虑微信小程序API限制,确保所有功能在实际环境中可实现。 ### 输出质量标准 **界面层次:**运用合理的视觉层级和信息密度。**细节精度:**确保文字排版、间距控制和对齐精确。**交互反馈:**提供状态指示、加载提示和操作确认。**业务完整性:**覆盖核心业务流程的所有关键节点。**行业深度:**深入理解目标行业的监管要求、专业标准和合规性需求。 ### 分批交付机制 采用分批确认的开发模式。每完成一批核心页面后暂停,等待确认反馈后继续后续页面开发。这种方式确保设计方向准确性并支持迭代优化。 ### 质量验收标准 最终交付的原型必须达到可直接投入开发使用的标准,包含完整的用户流程、清晰的功能逻辑和专业的视觉呈现。设计应体现对目标行业特性的深度理解,通过合适的配色、布局和交互设计营造符合业务定位的品牌形象。所有设计元素必须基于现有技术栈可实现,避免需要大量自定义开发的复杂效果。 ## 具体项目需求配置 现在需要为{行业领域}开发小程序,主要服务{用户角色列表},核心功能包括{核心功能列表},特殊要求为{特殊需求描述},行业监管要求为{合规要求},技术约束条件为{技术限制}。 ## 参考示例 基于在线教育行业的成功实践,该提示词已经过完整验证,能够生成专业级的微信小程序原型设计。通过以下关键要素实现高质量输出: **设计系统示例:**采用浅色暖色调配色方案,使用edu-blue、edu-green、edu-orange等语义化色彩变量,确保视觉一致性和专业感。 **功能模块示例:**包含用户引导流程(启动页、角色选择、首页)、核心业务模块(课程管理、作业系统、直播功能)、学习跟踪系统(进度管理、成绩统计、证书颁发)和个人中心功能。 **交互设计示例:**实现多角色底部导航差异化、状态管理和反馈机制、以及符合微信小程序规范的页面转场和组件交互。 通过明确的技术规范、设计要求和质量标准,这套提示词可以在不同行业项目中实现一致的高质量输出,确保生成的原型设计既符合行业特性又满足技术实现要求。 此提示词经过在线教育项目的完整验证,具备生成专业级微信小程序原型的能力,可适用于各行业的小程序开发需求。请注意,UI水平不允许低于示例的UI 示例代码:使用说明:将花括号内的占位符替换为具体项目需求:{配色风格} → 如"浅色暖色调"、"商务深色系"等{避免颜色} → 如"深色或过于饱和的颜色"- {禁用配色} → 如"蓝紫渐变色" (建议加上,防止AI味的UI)- {视觉限制} → 如"渐变、玻璃效果和圆角设计" (建议加上,防止AI味的UI){行业领域} → 如"医疗健康"、“金融科技”、"电商零售"等{用户角色列表} → 如"患者、医生、管理员"{核心功能列表} → 具体业务功能描述{特殊需求描述} → 行业特有需求{合规要求} → 相关法规和标准{技术限制} → 技术约束条件{cloud title="示例代码文件导入" type="default" url="/usr/uploads/custom-attachments/education_miniprogram.txt" password=""/} -
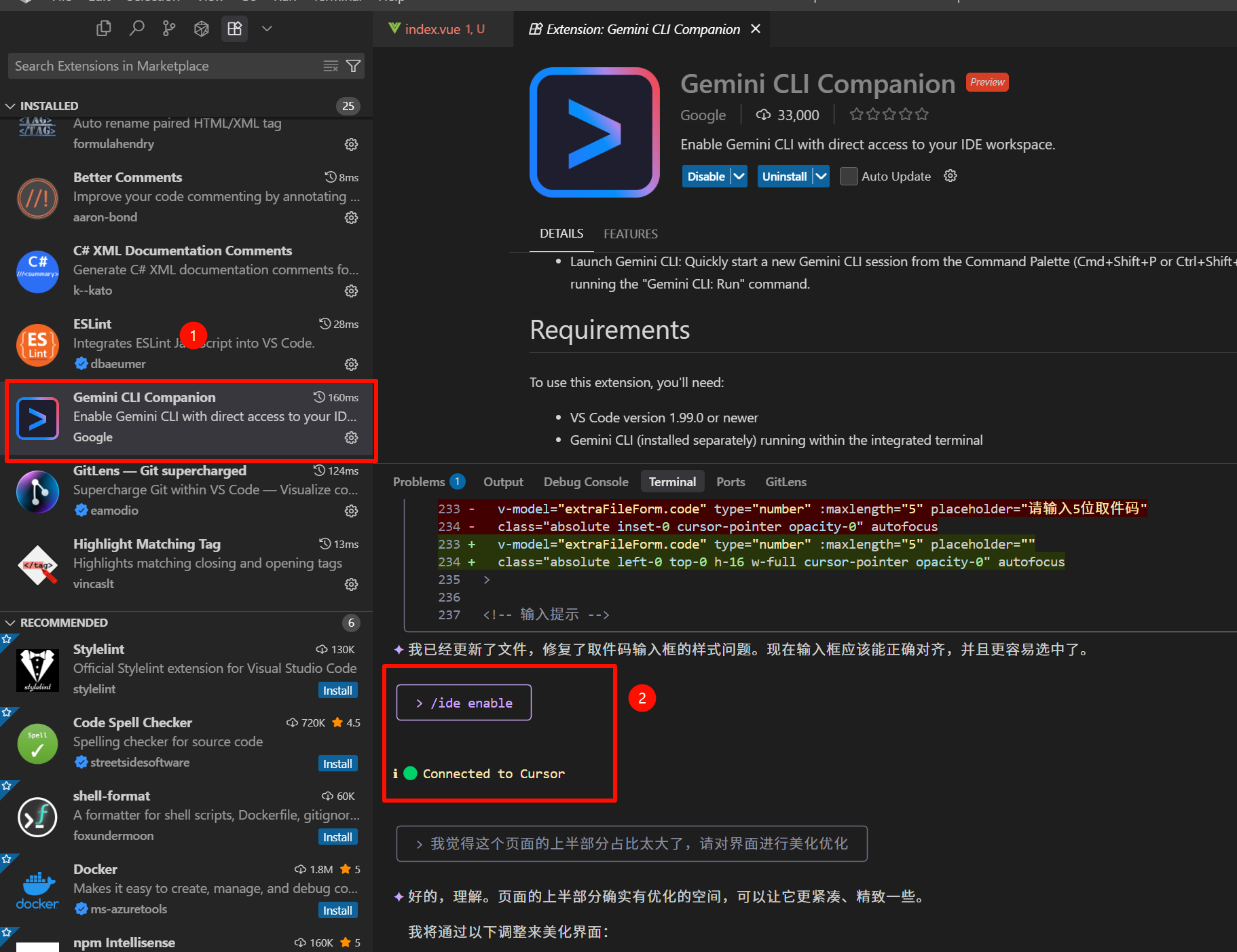
Gemini Cli Companion的使用 最近AI编辑器势头发展的很火啊,我最开始使用的是WindSurf,由于是初始股享受了10$/mon的优惠,回来这玩意不行了经常出问题,转战到Cursor。目前使用的主力编辑器就是 Cursor, 最近它的定价策略在变动,摸索一下新的方案。试用了一下 Gemini Cli分享一下经验。Github地址: https://github.com/google-gemini/gemini-cli 可以直接通过npm全局安装:npm install -g @google/gemini-cli登录的时候选择 Google 鉴权,出现网络问题需要提前设置命令行的代理。cmd下的命令为:set http_proxy=http://127.0.0.1:7890 set httpx_proxy=http://127.0.0.1:7890由于是Cli形式的,和Cursor这种命令行的使用方式不一样,借助编辑器插件可以进行增强。然后下载一个 Vscode 或 vsc forks都支持的 Gemini CLI Companion。/ide enable进行cli与编辑器关联。增强项如下:Open Editor File Context: Gemini CLI gains awareness of the files you have open in your editor, providing it with a richer understanding of your project's structure and content.Selection Context: Gemini CLI can easily access your cursor's position and selected text within the editor, giving it valuable context directly from your current work.Native Diffing: Seamlessly view, modify, and accept code changes suggested by Gemini CLI directly within the editor.Launch Gemini CLI: Quickly start a new Gemini CLI session from the Command Palette (Cmd+Shift+P or Ctrl+Shift+P) by running the "Gemini CLI: Run" command.引用IDE 整合 Gemini Cli: https://gemini-cli.gh.miniasp.com/ide-integration.html
-
域名搁着别浪费,Cloudflare + Gmail + Resend 十分钟轻松拥有免费的企业邮箱 现在的独立开发者们基本上是人手 N 个域名了,不过企业邮箱可能不是人人都有。这里和大家分享一下我个人定制完全免费的企业邮箱的方案:「Cloudflare + Gmail + Resend」。首先说下企业邮箱的优点:对用户来说,企业邮箱显得更专业,更容易被信任。利用 catch-all 功能,相当于拥有了无数个邮箱,可以方便我们注册各种服务。注意事项:如果您只需要进行邮件的收发,而不涉及群发等操作,那么这种方案可以说是非常简单且无成本的选择。示意图0. 前提你拥有一个域名,且域名的 dns 在 Cloudflare 管理。(当然任何其它拥有电子邮件路由功能的服务都可以,这里只介绍 Cloudflare)1. 使用 Cloudflare 接收邮件,设置邮件转发到 GmailCloudflare 是知名的网络安全公司,独立开发界最伟大的慈善家。如果你是刚起步的独立开发者,它的后台服务提供的免费额度可以让你零成本起步。1.1 进入域名下的「电子邮件路由」1.2 进入目标规则标签,开启 Catch-All,点击编辑1.3 设置转发操作,将所有邮件转发到 Gmail 邮箱添加目标位置时会发送一封确认邮件到邮箱,邮件里点确认即可。注意 Gmail 有一个小技巧是你可以在你的账号后面写上「+来源」,比如我这里写的是 auv1107+cleanclip@gmail,所有的邮件仍然会发送到 auv1107@gmail.com 中。如果你有多个域名就会非常方便,你可以根据这个字段在 Gmail 中筛选邮件。🎉🎉🎉 好了,到这里邮件的接收就搞定了。 你可以发送邮件到你域名下的任意账户上试试。原文:https://cleanclip.cc/zh/developer/cloudflare-worker-gmail-resend-enterprise-email/#_1-3-%E8%AE%BE%E7%BD%AE%E8%BD%AC%E5%8F%91%E6%93%8D%E4%BD%9C-%E5%B0%86%E6%89%80%E6%9C%89%E9%82%AE%E4%BB%B6%E8%BD%AC%E5%8F%91%E5%88%B0-gmail-%E9%82%AE%E7%AE%B1
-
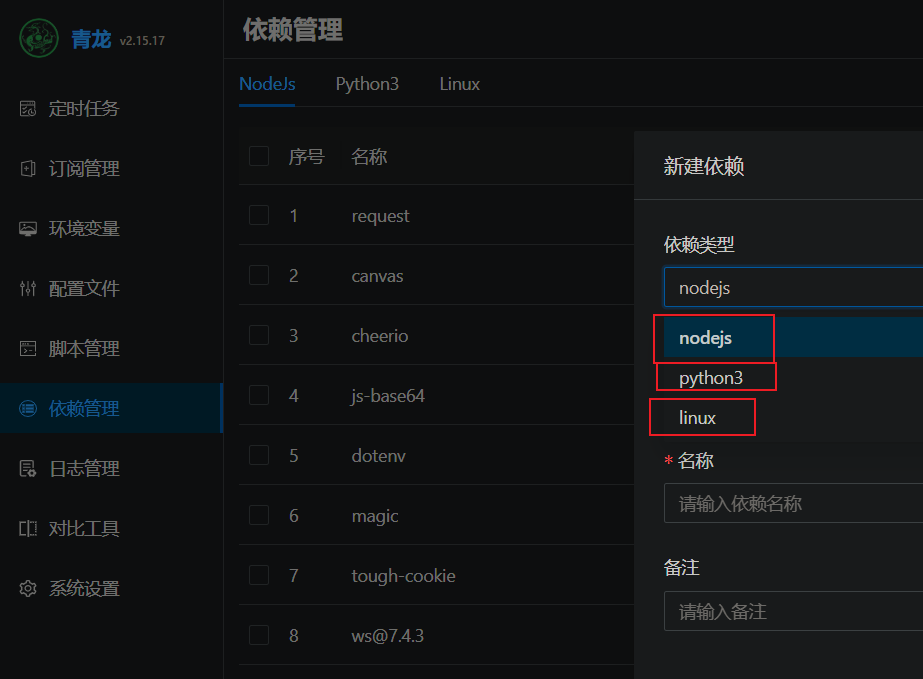
青龙面板基本使用并添加修改微信/支付宝步数脚本 青龙面板使用青龙面板安装# curl -sSL get.docker.com | sh docker run -dit \ -v $PWD/ql/data:/ql/data \ -p 5700:5700 \ # 部署路径非必须,以斜杠开头和结尾,比如 /test/ -e QlBaseUrl="/" \ --name qinglong \ --hostname qinglong \ --restart unless-stopped \ whyour/qinglong:latest安装完成后进入面板1.安装运行依赖勾选自动拆分nodejs依赖:request canvas cheerio js-base64 dotenv magic tough-cookie ws@7.4.3 require requests date-fns ts-md5 typescript json5 axios@v0.27.2 crypto-js @types/node png-js node-telegram-bot-api fs jsdom form-data jieba tslib ds jsdom -g prettytable ql common node-jsencrypt juejin-helper moment global-agentpython3:bs4 telethon cacheout jieba PyExecJS ping3 canvas Crypto ds requests pycryptodomelinux:bizCode bizMsg lxml libc-dev gcc g++ libffi-dev python3-dev2.环境变量点击环境变量——点击新建环境变量——名称设为:JD_COOKIE—输入获取到Cookies的相关参数(获取方法:【点击进入】——然后用手机登录——登录后按F12——点击Application——点开Cookies——找到pt_key=?;pt_pin=?;——把对应的值替换到问号中即可,分号要保留这里名称是不能自定义的,一定要用JD_COOKIE注意事项:1、登录后不要退出账号,否则Cookies会失效3.脚本拉取脚本项目地址一:https://github.com/shufflewzc/faker2脚本项目地址二:https://github.com/shufflewzc/faker3脚本项目地址三:https://github.com/Gnuyoah/Thread脚本项目地址四:https://github.com/Akali5/jd-depot进入之后拷贝Clone地址:ql repo https://ghproxy.com/https://github.com/shufflewzc/faker2.git "jd_|jx_|gua_|jddj_|getJDCookie" "activity|backUp" "^jd[^_]|USER|function|utils|ZooFaker_Necklace.js|JDJRValidator_Pure|sign_graphics_validate|ql" # 直接使用github地址拉不下来的话就套个镜像 https://ghproxy.com/ + github地址创建完立即执行一下,拉取一下脚本4.自建一个修改步数脚本# -*- coding: utf8 -*- import requests,time,re,json from random import randint headers = { 'User-Agent': 'Dalvik/2.1.0 (Linux; U; Android 9; MI 6 MIUI/20.6.18)' } #获取登录code def get_code(location): code_pattern = re.compile("(?<=access=).*?(?=&)") code = code_pattern.findall(location)[0] #print(code) return code #登录 def login(user,password): url1 = "https://api-user.huami.com/registrations/+86" + user + "/tokens" headers = { "Content-Type":"application/x-www-form-urlencoded;charset=UTF-8", "User-Agent":"MiFit/4.6.0 (iPhone; iOS 14.0.1; Scale/2.00)" } data1 = { "client_id":"HuaMi", "password":f"{password}", "redirect_uri":"https://s3-us-west-2.amazonaws.com/hm-registration/successsignin.html", "token":"access" } r1 = requests.post(url1,data=data1,headers=headers,allow_redirects=False) print(r1.text) location = r1.headers["Location"] #print(location) try: code = get_code(location) except: return 0,0 print("access_code获取成功!") print(code) url2 = "https://account.huami.com/v2/client/login" data2 = { "app_name":"com.xiaomi.hm.health", "app_version":"4.6.0", "code":f"{code}", "country_code":"CN", "device_id":"2C8B4939-0CCD-4E94-8CBA-CB8EA6E613A1", "device_model":"phone", "grant_type":"access_token", "third_name":"huami_phone", } r2 = requests.post(url2,data=data2,headers=headers).json() login_token = r2["token_info"]["login_token"] print("login_token获取成功!") print(login_token) userid = r2["token_info"]["user_id"] print("userid获取成功!") print(userid) return login_token,userid #主函数 def main(): login_token = 0 login_token,userid = login(user,password) if login_token == 0: print("登陆失败!") return "login fail!" t = get_time() app_token = get_app_token(login_token) date = time.strftime("%Y-%m-%d",time.localtime()) today = time.strftime("%F") data_json = '%5B%7B%22data_hr%22%3A%22%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F9L%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FVv%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F0v%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F9e%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F0n%5C%2Fa%5C%2F%5C%2F%5C%2FS%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F0b%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F1FK%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FR%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F9PTFFpaf9L%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FR%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F0j%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F9K%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FOv%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2Fzf%5C%2F%5C%2F%5C%2F86%5C%2Fzr%5C%2FOv88%5C%2Fzf%5C%2FPf%5C%2F%5C%2F%5C%2F0v%5C%2FS%5C%2F8%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FSf%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2Fz3%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F0r%5C%2FOv%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FS%5C%2F9L%5C%2Fzb%5C%2FSf9K%5C%2F0v%5C%2FRf9H%5C%2Fzj%5C%2FSf9K%5C%2F0%5C%2F%5C%2FN%5C%2F%5C%2F%5C%2F%5C%2F0D%5C%2FSf83%5C%2Fzr%5C%2FPf9M%5C%2F0v%5C%2FOv9e%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FS%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2Fzv%5C%2F%5C%2Fz7%5C%2FO%5C%2F83%5C%2Fzv%5C%2FN%5C%2F83%5C%2Fzr%5C%2FN%5C%2F86%5C%2Fz%5C%2F%5C%2FNv83%5C%2Fzn%5C%2FXv84%5C%2Fzr%5C%2FPP84%5C%2Fzj%5C%2FN%5C%2F9e%5C%2Fzr%5C%2FN%5C%2F89%5C%2F03%5C%2FP%5C%2F89%5C%2Fz3%5C%2FQ%5C%2F9N%5C%2F0v%5C%2FTv9C%5C%2F0H%5C%2FOf9D%5C%2Fzz%5C%2FOf88%5C%2Fz%5C%2F%5C%2FPP9A%5C%2Fzr%5C%2FN%5C%2F86%5C%2Fzz%5C%2FNv87%5C%2F0D%5C%2FOv84%5C%2F0v%5C%2FO%5C%2F84%5C%2Fzf%5C%2FMP83%5C%2FzH%5C%2FNv83%5C%2Fzf%5C%2FN%5C%2F84%5C%2Fzf%5C%2FOf82%5C%2Fzf%5C%2FOP83%5C%2Fzb%5C%2FMv81%5C%2FzX%5C%2FR%5C%2F9L%5C%2F0v%5C%2FO%5C%2F9I%5C%2F0T%5C%2FS%5C%2F9A%5C%2Fzn%5C%2FPf89%5C%2Fzn%5C%2FNf9K%5C%2F07%5C%2FN%5C%2F83%5C%2Fzn%5C%2FNv83%5C%2Fzv%5C%2FO%5C%2F9A%5C%2F0H%5C%2FOf8%5C%2F%5C%2Fzj%5C%2FPP83%5C%2Fzj%5C%2FS%5C%2F87%5C%2Fzj%5C%2FNv84%5C%2Fzf%5C%2FOf83%5C%2Fzf%5C%2FOf83%5C%2Fzb%5C%2FNv9L%5C%2Fzj%5C%2FNv82%5C%2Fzb%5C%2FN%5C%2F85%5C%2Fzf%5C%2FN%5C%2F9J%5C%2Fzf%5C%2FNv83%5C%2Fzj%5C%2FNv84%5C%2F0r%5C%2FSv83%5C%2Fzf%5C%2FMP%5C%2F%5C%2F%5C%2Fzb%5C%2FMv82%5C%2Fzb%5C%2FOf85%5C%2Fz7%5C%2FNv8%5C%2F%5C%2F0r%5C%2FS%5C%2F85%5C%2F0H%5C%2FQP9B%5C%2F0D%5C%2FNf89%5C%2Fzj%5C%2FOv83%5C%2Fzv%5C%2FNv8%5C%2F%5C%2F0f%5C%2FSv9O%5C%2F0ZeXv%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F1X%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F9B%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2FTP%5C%2F%5C%2F%5C%2F1b%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F0%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F9N%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2F%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%5C%2Fv7%2B%22%2C%22date%22%3A%222021-08-07%22%2C%22data%22%3A%5B%7B%22start%22%3A0%2C%22stop%22%3A1439%2C%22value%22%3A%22UA8AUBQAUAwAUBoAUAEAYCcAUBkAUB4AUBgAUCAAUAEAUBkAUAwAYAsAYB8AYB0AYBgAYCoAYBgAYB4AUCcAUBsAUB8AUBwAUBIAYBkAYB8AUBoAUBMAUCEAUCIAYBYAUBwAUCAAUBgAUCAAUBcAYBsAYCUAATIPYD0KECQAYDMAYB0AYAsAYCAAYDwAYCIAYB0AYBcAYCQAYB0AYBAAYCMAYAoAYCIAYCEAYCYAYBsAYBUAYAYAYCIAYCMAUB0AUCAAUBYAUCoAUBEAUC8AUB0AUBYAUDMAUDoAUBkAUC0AUBQAUBwAUA0AUBsAUAoAUCEAUBYAUAwAUB4AUAwAUCcAUCYAUCwKYDUAAUUlEC8IYEMAYEgAYDoAYBAAUAMAUBkAWgAAWgAAWgAAWgAAWgAAUAgAWgAAUBAAUAQAUA4AUA8AUAkAUAIAUAYAUAcAUAIAWgAAUAQAUAkAUAEAUBkAUCUAWgAAUAYAUBEAWgAAUBYAWgAAUAYAWgAAWgAAWgAAWgAAUBcAUAcAWgAAUBUAUAoAUAIAWgAAUAQAUAYAUCgAWgAAUAgAWgAAWgAAUAwAWwAAXCMAUBQAWwAAUAIAWgAAWgAAWgAAWgAAWgAAWgAAWgAAWgAAWREAWQIAUAMAWSEAUDoAUDIAUB8AUCEAUC4AXB4AUA4AWgAAUBIAUA8AUBAAUCUAUCIAUAMAUAEAUAsAUAMAUCwAUBYAWgAAWgAAWgAAWgAAWgAAWgAAUAYAWgAAWgAAWgAAUAYAWwAAWgAAUAYAXAQAUAMAUBsAUBcAUCAAWwAAWgAAWgAAWgAAWgAAUBgAUB4AWgAAUAcAUAwAWQIAWQkAUAEAUAIAWgAAUAoAWgAAUAYAUB0AWgAAWgAAUAkAWgAAWSwAUBIAWgAAUC4AWSYAWgAAUAYAUAoAUAkAUAIAUAcAWgAAUAEAUBEAUBgAUBcAWRYAUA0AWSgAUB4AUDQAUBoAXA4AUA8AUBwAUA8AUA4AUA4AWgAAUAIAUCMAWgAAUCwAUBgAUAYAUAAAUAAAUAAAUAAAUAAAUAAAUAAAUAAAUAAAWwAAUAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAeSEAeQ8AcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcBcAcAAAcAAAcCYOcBUAUAAAUAAAUAAAUAAAUAUAUAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcCgAeQAAcAAAcAAAcAAAcAAAcAAAcAYAcAAAcBgAeQAAcAAAcAAAegAAegAAcAAAcAcAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcCkAeQAAcAcAcAAAcAAAcAwAcAAAcAAAcAIAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcCIAeQAAcAAAcAAAcAAAcAAAcAAAeRwAeQAAWgAAUAAAUAAAUAAAUAAAUAAAcAAAcAAAcBoAeScAeQAAegAAcBkAeQAAUAAAUAAAUAAAUAAAUAAAUAAAcAAAcAAAcAAAcAAAcAAAcAAAegAAegAAcAAAcAAAcBgAeQAAcAAAcAAAcAAAcAAAcAAAcAkAegAAegAAcAcAcAAAcAcAcAAAcAAAcAAAcAAAcA8AeQAAcAAAcAAAeRQAcAwAUAAAUAAAUAAAUAAAUAAAUAAAcAAAcBEAcA0AcAAAWQsAUAAAUAAAUAAAUAAAUAAAcAAAcAoAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAYAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcBYAegAAcAAAcAAAegAAcAcAcAAAcAAAcAAAcAAAcAAAeRkAegAAegAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAEAcAAAcAAAcAAAcAUAcAQAcAAAcBIAeQAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcBsAcAAAcAAAcBcAeQAAUAAAUAAAUAAAUAAAUAAAUBQAcBYAUAAAUAAAUAoAWRYAWTQAWQAAUAAAUAAAUAAAcAAAcAAAcAAAcAAAcAAAcAMAcAAAcAQAcAAAcAAAcAAAcDMAeSIAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcAAAcBQAeQwAcAAAcAAAcAAAcAMAcAAAeSoAcA8AcDMAcAYAeQoAcAwAcFQAcEMAeVIAaTYAbBcNYAsAYBIAYAIAYAIAYBUAYCwAYBMAYDYAYCkAYDcAUCoAUCcAUAUAUBAAWgAAYBoAYBcAYCgAUAMAUAYAUBYAUA4AUBgAUAgAUAgAUAsAUAsAUA4AUAMAUAYAUAQAUBIAASsSUDAAUDAAUBAAYAYAUBAAUAUAUCAAUBoAUCAAUBAAUAoAYAIAUAQAUAgAUCcAUAsAUCIAUCUAUAoAUA4AUB8AUBkAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAAfgAA%22%2C%22tz%22%3A32%2C%22did%22%3A%22DA932FFFFE8816E7%22%2C%22src%22%3A24%7D%5D%2C%22summary%22%3A%22%7B%5C%22v%5C%22%3A6%2C%5C%22slp%5C%22%3A%7B%5C%22st%5C%22%3A1628296479%2C%5C%22ed%5C%22%3A1628296479%2C%5C%22dp%5C%22%3A0%2C%5C%22lt%5C%22%3A0%2C%5C%22wk%5C%22%3A0%2C%5C%22usrSt%5C%22%3A-1440%2C%5C%22usrEd%5C%22%3A-1440%2C%5C%22wc%5C%22%3A0%2C%5C%22is%5C%22%3A0%2C%5C%22lb%5C%22%3A0%2C%5C%22to%5C%22%3A0%2C%5C%22dt%5C%22%3A0%2C%5C%22rhr%5C%22%3A0%2C%5C%22ss%5C%22%3A0%7D%2C%5C%22stp%5C%22%3A%7B%5C%22ttl%5C%22%3A18272%2C%5C%22dis%5C%22%3A10627%2C%5C%22cal%5C%22%3A510%2C%5C%22wk%5C%22%3A41%2C%5C%22rn%5C%22%3A50%2C%5C%22runDist%5C%22%3A7654%2C%5C%22runCal%5C%22%3A397%2C%5C%22stage%5C%22%3A%5B%7B%5C%22start%5C%22%3A327%2C%5C%22stop%5C%22%3A341%2C%5C%22mode%5C%22%3A1%2C%5C%22dis%5C%22%3A481%2C%5C%22cal%5C%22%3A13%2C%5C%22step%5C%22%3A680%7D%2C%7B%5C%22start%5C%22%3A342%2C%5C%22stop%5C%22%3A367%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A2295%2C%5C%22cal%5C%22%3A95%2C%5C%22step%5C%22%3A2874%7D%2C%7B%5C%22start%5C%22%3A368%2C%5C%22stop%5C%22%3A377%2C%5C%22mode%5C%22%3A4%2C%5C%22dis%5C%22%3A1592%2C%5C%22cal%5C%22%3A88%2C%5C%22step%5C%22%3A1664%7D%2C%7B%5C%22start%5C%22%3A378%2C%5C%22stop%5C%22%3A386%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A1072%2C%5C%22cal%5C%22%3A51%2C%5C%22step%5C%22%3A1245%7D%2C%7B%5C%22start%5C%22%3A387%2C%5C%22stop%5C%22%3A393%2C%5C%22mode%5C%22%3A4%2C%5C%22dis%5C%22%3A1036%2C%5C%22cal%5C%22%3A57%2C%5C%22step%5C%22%3A1124%7D%2C%7B%5C%22start%5C%22%3A394%2C%5C%22stop%5C%22%3A398%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A488%2C%5C%22cal%5C%22%3A19%2C%5C%22step%5C%22%3A607%7D%2C%7B%5C%22start%5C%22%3A399%2C%5C%22stop%5C%22%3A414%2C%5C%22mode%5C%22%3A4%2C%5C%22dis%5C%22%3A2220%2C%5C%22cal%5C%22%3A120%2C%5C%22step%5C%22%3A2371%7D%2C%7B%5C%22start%5C%22%3A415%2C%5C%22stop%5C%22%3A427%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A1268%2C%5C%22cal%5C%22%3A59%2C%5C%22step%5C%22%3A1489%7D%2C%7B%5C%22start%5C%22%3A428%2C%5C%22stop%5C%22%3A433%2C%5C%22mode%5C%22%3A1%2C%5C%22dis%5C%22%3A152%2C%5C%22cal%5C%22%3A4%2C%5C%22step%5C%22%3A238%7D%2C%7B%5C%22start%5C%22%3A434%2C%5C%22stop%5C%22%3A444%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A2295%2C%5C%22cal%5C%22%3A95%2C%5C%22step%5C%22%3A2874%7D%2C%7B%5C%22start%5C%22%3A445%2C%5C%22stop%5C%22%3A455%2C%5C%22mode%5C%22%3A4%2C%5C%22dis%5C%22%3A1592%2C%5C%22cal%5C%22%3A88%2C%5C%22step%5C%22%3A1664%7D%2C%7B%5C%22start%5C%22%3A456%2C%5C%22stop%5C%22%3A466%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A1072%2C%5C%22cal%5C%22%3A51%2C%5C%22step%5C%22%3A1245%7D%2C%7B%5C%22start%5C%22%3A467%2C%5C%22stop%5C%22%3A477%2C%5C%22mode%5C%22%3A4%2C%5C%22dis%5C%22%3A1036%2C%5C%22cal%5C%22%3A57%2C%5C%22step%5C%22%3A1124%7D%2C%7B%5C%22start%5C%22%3A478%2C%5C%22stop%5C%22%3A488%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A488%2C%5C%22cal%5C%22%3A19%2C%5C%22step%5C%22%3A607%7D%2C%7B%5C%22start%5C%22%3A489%2C%5C%22stop%5C%22%3A499%2C%5C%22mode%5C%22%3A4%2C%5C%22dis%5C%22%3A2220%2C%5C%22cal%5C%22%3A120%2C%5C%22step%5C%22%3A2371%7D%2C%7B%5C%22start%5C%22%3A500%2C%5C%22stop%5C%22%3A511%2C%5C%22mode%5C%22%3A3%2C%5C%22dis%5C%22%3A1268%2C%5C%22cal%5C%22%3A59%2C%5C%22step%5C%22%3A1489%7D%2C%7B%5C%22start%5C%22%3A512%2C%5C%22stop%5C%22%3A522%2C%5C%22mode%5C%22%3A1%2C%5C%22dis%5C%22%3A152%2C%5C%22cal%5C%22%3A4%2C%5C%22step%5C%22%3A238%7D%5D%7D%2C%5C%22goal%5C%22%3A8000%2C%5C%22tz%5C%22%3A%5C%2228800%5C%22%7D%22%2C%22source%22%3A24%2C%22type%22%3A0%7D%5D' finddate = re.compile(r'.*?date%22%3A%22(.*?)%22%2C%22data.*?') findstep = re.compile(r'.*?ttl%5C%22%3A(.*?)%2C%5C%22dis.*?') data_json = re.sub(finddate.findall(data_json)[0], today, str(data_json)) data_json = re.sub(findstep.findall(data_json)[0], step, str(data_json)) url = f'https://api-mifit-cn.huami.com/v1/data/band_data.json?&t={t}' head = { "Content-Type": "application/x-www-form-urlencoded", 'apptoken': f'{app_token}' } data = f'userid={userid}&last_sync_data_time=1597306380&device_type=0&last_deviceid=DA932FFFFE8816E7&data_json={data_json}' response = requests.post(url, data=data, headers=head).json() print(response) result = f"当前用户:{user}</br> 修改步数: {step} </br> 修改结果: "+ response['message'] server_send(result) qmsg_send(result) plus_send(result) print(result) return result #获取时间戳 def get_time(): url = 'http://api.m.taobao.com/rest/api3.do?api=mtop.common.getTimestamp' response = requests.get(url,headers=headers).json() t = response['data']['t'] return t #获取app_token def get_app_token(login_token): url = f"https://account-cn.huami.com/v1/client/app_tokens?app_name=com.xiaomi.hm.health&dn=api-user.huami.com%2Capi-mifit.huami.com%2Capp-analytics.huami.com&login_token={login_token}&os_version=4.1.0" response = requests.get(url,headers=headers).json() app_token = response['token_info']['app_token'] print("app_token获取成功!") print(app_token) return app_token #server酱微信推送 def server_send(msg): if sckey == '': return server_url = "https://sc.ftqq.com/" + str(sckey) + ".send" data = { 'text': msg, 'desp': msg } requests.post(server_url, data=data) #Qmsg酱QQ推送 def qmsg_send(msg): if qkey == '': return qmsg_url = "https://qmsg.zendee.cn:443/send/" + str(qkey) data = { 'qq': f'{qq}', 'msg': msg } requests.post(qmsg_url, data=data) # PUSHPLUS推送 def plus_send(msg,title='小米运动助手',template ='markdown'): if plustoken == '': return url = 'http://www.pushplus.plus/send' data = { "token": plustoken, "title": title, "content": msg, "template":template } body = json.dumps(data).encode(encoding='utf-8') headers = {'Content-Type': 'application/json'} response = requests.post(url, data=body, headers=headers) if response.status_code ==200: return 1 return 0 # -- 配置 -- # ------------------------------ user = "136****1234" #小米运动账号 password = "123456" #密码 step = str(randint(18000,25000)) # 范围内取随机数, 前面不但能大于后面的数 #以下为信息推送,不懂的可不填写不影响刷步 sckey = '' # server酱微信推送key(不懂不要填,可空) qkey = '' # Qmsg酱QQ推送key(不懂不要填,可空) qq= '' # 需要推送的qq号 (不懂不要填,可空) plustoken = '' #PUSHPLUS的token 官网为https://www.pushplus.plus/(不懂不要填,可空) # ------------------------------ # def main_handler(event, context): # return main() # 阿里云函数 def handler(*args): main() if __name__ == '__main__': main()通过编辑器自建一个, 我这里的路径是custom/xiaomiStep.py回到定时任务tab我填写的定时规则是每天早上7点执行引用1.qinglong github: https://github.com/whyour/qinglong2.2023最新青龙面板安装|Docker安装青龙面板,JD自动签到,青龙面板搭建 ,每天自动做任务领取京豆,操作简单&设置简单,非常适合有软路由和服务器&vps的小伙伴,一次搭建长期使用:https://www.youtube.com/watch?v=4CWlq8Xp_Oc&t=6s&ab_channel=%E4%B8%80%E7%93%B6%E5%A5%B6%E6%B2%B93.搭建青龙面板:https://naiyou001.tk/knowledge/6864.青龙拉取faker库以及脚本去重详细教程:https://blog.csdn.net/cbh1987/article/details/1204834215.小米运动步数修改_阿里云函数版本:https://www.52pojie.cn/thread-1656364-1-1.html
-
为Sublime Text安装smali代码语法高亮插件 为Sublime Text安装smali代码语法高亮插件查看smali文件的时候,发现并没有高亮显示。我想应该会有这样的插件,于是在github在找了sublime-smali:https://github.com/ShaneWilton/sublime-smali。之前并不知道如何使用,咨询了作者之后得到的回复:For sure! From Sublime Text, press Preferences -> Browse Packages, then just place the files for the syntax highlighter in there, under their own directory.打开Sublime TextPreferences -> Browse Packages然后将会打开Finder显示Sublime Text的Packages目录或者直接打开/Users/*/Library/Application Support/Sublime Text 2/Packages, Sublime Text3中,package路径为/sublimePath/Packages)你可以在这里新建一个文件夹,命名为Smali,然后将下载的smali.tmlanguage文件复制到新建的Smali文件夹中.重启Sublime Text,再次打开smali文件的时候,已经可以高亮显示了。引用1.QuinnWilton/sublime-smali: A syntax highlighter for the Dalvik bytecode language, Smali (github.com)
-
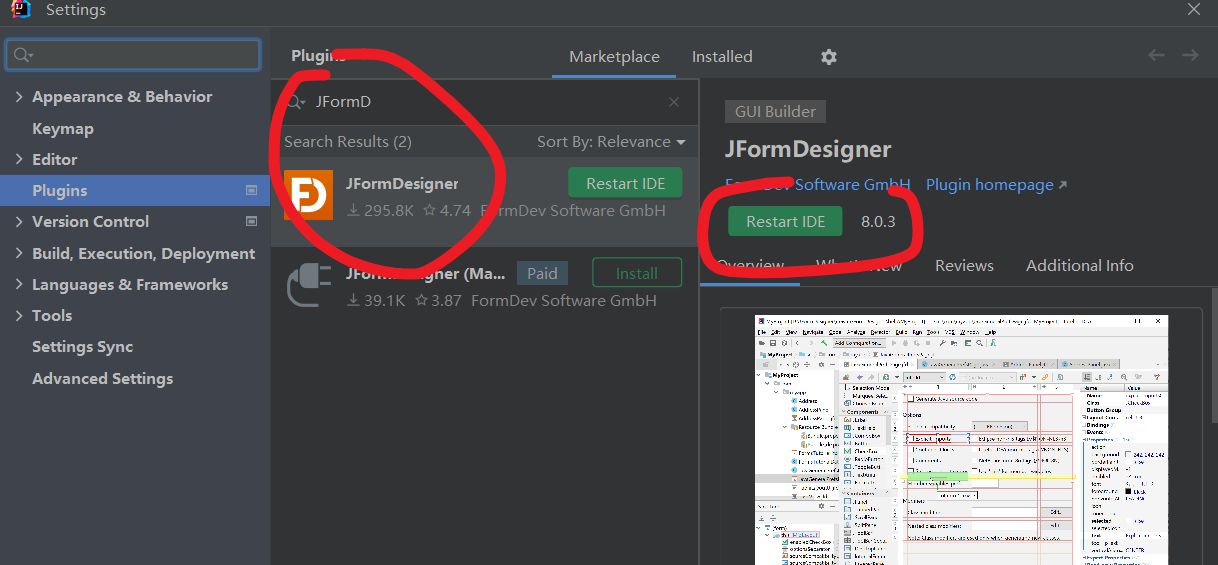
JFormDesigner破解及使用 JFormDesigner破解流程1.安装JFormDesigner插件2.寻找安装的插件位置2.1 Toolbox方式这里的位置是:C:\Users\Administrator\AppData\Local\JetBrains\Toolbox\apps\IDEA-U\ch-0\231.8109.175.plugins\JFormDesigner2.2 普通安装方式路径是:C:\Users\Administrator\AppData\Roaming\JetBrains\IntelliJIdea2023.1 + \plugins\JFormDesigner3.寻找JFormDesigner-Idea.jar记录下lib/JFormDesigner-Idea.jar的路径C:\Users\Administrator\AppData\Local\JetBrains\Toolbox\apps\IDEA-U\ch-0\231.8109.175.plugins\JFormDesigner\lib\JFormDesigner-Idea.jar4.调用注册机生成激活凭证打开注册机,点击 Patch 按钮,选择上面的文件完成后会提示:点击Generate生成JFormDesigner_license.txt文件,记住保存的路径记住激活码文件保存的路径(可以放桌面,只用一次,激活后就可以删除)5.使用凭证激活至此激活成功6.基本使用1.新建Form激活成功后就可以愉快玩耍了,尽情拖拽生成界面7.本文工具{cloud title="激活注册机" type="lz" url="https://wwif.lanzouw.com/iC1l40svu6ef" password=""/}引用1.IDEA Ui设计器JFormDesigner 永久激活----插件+注册机 自己一直在用的版本和注册机 - https://www.cnblogs.com/zwnsyw/p/16377332.html2.记录我的一次JFormDesigner注册流程 - https://blog.csdn.net/hloton/article/details/127623771
-
常用链接记录 镜像|仓库类名字地址描述清华大学开源软件镜像站https://mirrors.tuna.tsinghua.edu.cn/ubuntu-releases/20.04/高速下载Ubuntu镜像阿里云开源镜像站http://mirrors.aliyun.com/centos/7/isos/x86_64/高速下载CentOs7镜像Packagisthttps://packagist.org/Composer包检索Maven搜索http://mvn.coderead.cn/最快捷的Maven搜索BootCDNhttps://www.bootcdn.cn/前端资源CDNStaticfile CDNhttp://staticfile.org/前端资源CDN接码平台名字地址描述SMS-Activatehttps://sms-activate.org/...算法刷题名字地址描述LeetCodehttps://leetcode.cn/...啊哈添柴https://www.acoj.com/在线OJAcWinghttps://www.acwing.com/problem/题库LintCodehttps://www.lintcode.com/problem/...资源下载名字地址描述Project Gutenberghttps://www.gutenberg.org/Welcome to Project Gutenberg,Project Gutenberg is a library of over 70,000 free eBooks语言学习英语名字地址描述同桌英语https://cet.itongzhuo.com/fourSixExam/student/Index.jsp?meType=0同桌英语是专业的英语学习交流平台,为大家提供了历年英语四六级真题及答案解析,帮助大家更好更快的学习英文四六级考试内容,希望丰富的题库能快速帮助您解决学习英语中遇到的问题。英语真题在线https://zhenti.burningvocabulary.com/英语真题在线YouZack-英语听力精听、背单词https://www.youzack.com/YouZack-英语听力精听、背单词
-
搭建基于 Hugo 的静态响应式网址导航主题 搭建效果ico提取一为Api:https://api.iowen.cn/doc/favicon.html请求示例:https://api.iowen.cn/favicon/www.iowen.cn.png部署/www/wwwroot/nav/hugo --config="/www/wwwroot/nav/config.toml" -s /www/wwwroot/nav/ -d /www/wwwroot/nav/nav-public发布静态资源后创建网站即可相关链接github - shenweiyan/WebStack-Hugo : https://github.com/shenweiyan/WebStack-HugoWebStack-Hugo | 一个静态响应式网址导航主题:https://www.yuque.com/shenweiyan/cookbook/webstack-hugogithub - gohugoio/hugo : https://github.com/gohugoio/hugo/releases
-
Redmi k40 Gaming Root {mtitle title="本文目录"/}Redmi k40 Gaming Root注意:刷Root有变砖、无限重启、卡米等各种风险操作前请先备份好数据,解锁或刷机后的第一次开机时间较长,请等待10分钟左右。前言没有Root的机器太不方便了。一是因为在手机上抓app的包由于证书安装不了,关键请求拿不到。二是不能对Android.data.xxx应用数据文件夹的内容进行操作,就很烦。于是冒着变砖的风险 直接就开刷了1.解锁Bootloader这种方式解锁是需要等待几天时间的。解锁时候数据会被清除,请一定要备份好数据。解锁成功后:手机会自动退出FashBoot模式并重启,开机动画上方会有一个打开了的锁图标解锁工具下载:http://www.miui.com/unlock/index.html解锁Bootloader的步骤:1.在需要解锁的设备中登录已经具备解锁权限的小米账号,并进入“设置 -> 开发者选项 -> 设备解锁状态”中绑定账号和设备; 2.绑定成功后,手动进入Bootloader模式(关机后,同时按住开机键和音量下键); 3.下载手机解锁工具(解锁工具官网),在PC端的小米解锁工具中,登录相同的小米账号,并通过USB连接手机; 4.点击PC端解锁工具的“解锁”按钮,根据提示信息等待指定时间后再次尝试或者立即解锁;1.1 解锁Bootloader过程中可能遇到的问题:Q:解锁工具提示“账号设备不一致”是怎么回事? A:这是在解锁过程中没有通过账号与设备验证,解决办法是先将手机升级到最新的稳定版或者从稳定版卡刷到最新的开发版,在待解锁的设备和解锁工具上要登陆同一个账号,并进入“设置 -> 开发者选项 -> 设备解锁状态”中绑定账号和设备。 Q:解锁工具提示“无法获取手机信息”是怎么回事? A:这种情况一般是电脑上的设备驱动没有装好,可以尝试重插USB线或者换个USB接口或者换根USB线来等待电脑慢慢安装驱动,或在工具右上角驱动安装模块中主动安装驱动。 Q:解锁失败显示“账号与设备的绑定时间太短,xxx个小时后再解锁” A:在售的新机型一般需要等待,用户账号安全评分较低的需要等待,等待时间目前是7天起,如果本年度解锁手机数超过2台,等待时间会相应增长。 Q:解锁失败显示“此账号本月解锁次数达到上限” A:一个小米账号每月限制解锁一台设备。 Q:解锁失败显示“此账号本年累计解锁次数已达上限” A:一个小米账号每年限制解锁4台不同设备。 Q:解锁失败显示“账号权限不足或者账号受限” A:账号存在安全风险,无法处理解锁操作,建议更换账号。 Q:解锁失败显示“未知错误-1” A:网络异常,请更换时间段或更换网络进行解锁。2.下载Magisk一开始我也不知道这东西干什么的,可以简单理解为是管理Root权限的,其他应用需要Root权限会向它申请。我下载的版本是: V24.2官方Github : https://github.com/topjohnwu/Magisk/releases所有的Magisk版本需要注意:高通设备的安卓11:官方版本的Magisk(V23版本和V24版本)高通设备的安卓12::官方版本的Magisk(V24版本)大部分联发科设备的安卓11:官方版本的Magisk(V23版本)特殊机型(红米K40游戏增强版,Note10Pro)的安卓11:使用专用的Magisk 或 官方Magisk(V24版本)特殊机型(红米K40游戏增强版,Note10Pro)的安卓12:官方版本的Magisk(V24)3.下载线刷包下载网站:https://xiaomirom.com/找到自己手机型号和目标版本Redmik40 Gaming 直达 :https://xiaomirom.com/rom/redmi-k40-gaming-poco-f3-gt-ares-china-fastboot-recovery-rom/3.1 刷入Magisk参考的酷安文章,作者讲的很详细了,不再搬运:【小白向】为你的设备刷入Magisk(面具/脸谱)的Root:https://www.coolapk.com/feed/34261961?shareKey=OTBjYmYwZmNlYjc0NjJkZTJhYzA~&shareFrom=com.coolapk.market_12.3.2文章用到的工具下载:{cloud title="刷机工具压缩包" type="bd" url="https://pan.baidu.com/s/1To1eV06-0NrKHavktxHtuw?pwd=k4kz " password="k4kz"/}4.过程操作出错刷回正常机器百度上的操作太乱太杂了,踩坑的时候导致手机无限重启了,只能刷回正常的重新开始。前提条件:1.准备线刷包(第三小节),解压到全英的目录2.下载MiFlash:https://miuiver.com/miflash/刷机步骤(MiFlash的使用):http://www.winwin7.com/JC/21571.html4.1 MiFlash 错误 Not catch checkpoint 解决方法在使用 MiFlash 刷机时界面显示下图错误,但手机已完成刷机并自动重启进入系统,测试使用也没有发现异常。error:Not catch checkpoint (\$fastboot -s .*lock), flash is not done4.1.1 问题原因导致这个问题的原因是,新版 MiFlash 在刷机完成后会检测手机是否已上 BL 锁。如果您选择“全部删除”或“保留用户数据”这两种刷机模式,因为没有锁定 BL 锁,就会触发这个错误显示。由于这个检查是在刷机完成后进行的,所以实际上对手机并没有影响,这是 MiFlash 本身的问题。4.1.2 解决方法如果想要避免这个问题,除了使用“全部删除并lock”刷机模式外(注:如果刷海外版固件,请勿选择此刷机模式,不然会因 BL 区域限制无法启动系统),也可以在 MiFlash 配置选项里关闭这个检查。具体请在菜单栏点击“Configuration”,点击“MiFlash Configuration”,在弹出窗口删除 CheckPoint 里的 \$fastboot -s .*lock 文本。保持设置后再次刷机就不会遇到 error:Not catch checkpoint (\$fastboot -s .*lock), flash is not done 问题了。参考1.[教程] 小米手机解锁 Bootloader 教程和常见问题 : https://web.vip.miui.com/page/info/mio/mio/detail?postId=17982230&app_version=dev.200512.【小白向】为你的设备刷入Magisk(面具/脸谱)的Root : https://www.coolapk.com/feed/34261961?shareKey=OTBjYmYwZmNlYjc0NjJkZTJhYzA~&shareFrom=com.coolapk.market_12.3.23.MiFlash怎么用?小米刷机工具MiFlash使用方法:http://www.winwin7.com/JC/21571.html4.MiFlash 错误 Not catch checkpoint 解决方法:https://miuiver.com/miflash-error-not-catch-checkpoint/5.TUTU-整合magisk模块、刷机资源和教程及k40g/note11pro+的boothttps://miui.wtututu.top/
-
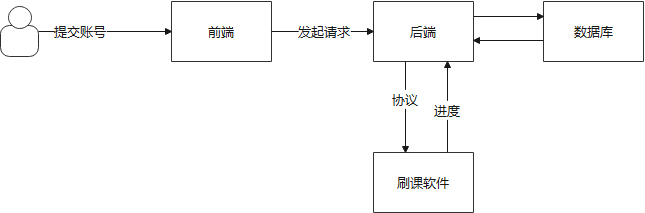
Chrome浏览器多开独立环境、独立Cookie、可用插件 ::(泪) 手里有一批学习通网课需要看,打算用油猴找个插件,然后浏览器多开挂机看。浏览器用的这个版本{cloud title="chrome73.7z" type="github" url="https://github.com/techxuexi21/win-chrome/blob/master/chrome73.7z" password=""/}附带了ChromeDriver驱动之后打算做一个刷课网站这些网课平台怪严格的,现有的刷课平台中慢刷应该是通过脚本模拟浏览器操作吧快刷就是直接发http请求?...{dotted startColor="#ff6c6c" endColor="#1989fa"/}多开的步骤就是 先创建一个主程序的快捷方式,然后在 目标 栏目中追加以下代码,旨在修改数据存储路径: --user-data-dir="E:\刷课\chrome2\data"