搜索到
72
篇与
的结果
-

-
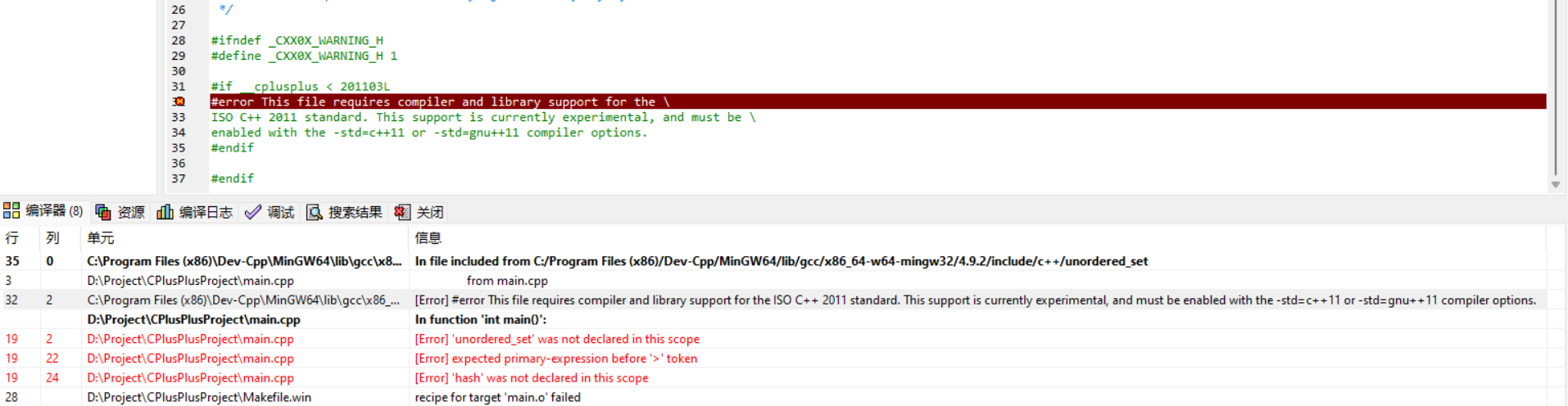
CCPC训练赛回顾 CCPC训练赛回顾时间:2023-04-25 6:30 ~ 8:30之前写算法一直用的Java,最近抽风= =,想从零开始学C++。比赛的时候前半段用的就是C++说下感受:借的电脑比赛的,只有裸机笔记本..没键鼠太麻烦了。C++还是不熟悉,题都过了一遍,不知道什么情况就是不能Ac,又换成Java过(一直没用,还好没忘!现在回顾才发现比赛的时候真是太愚蠢了!我感觉对我来说是三道简单题三道难题,关键是简单题耗时太长了,没空研究难题了呜呜呜。A. 不晔的幸运数字题目描述不晔认为1和6是幸运的数字,当一个正整数只包含1和6的时候,这个数就是幸运的。(如166、666都是幸运的数,而36、216不是)现在告诉你一个正整数a,请告诉不晔距离这个数字最近的幸运数字。输入描述输入共一行一个正整数a输出描述输出距离a最近的幸运数字(如果有两个幸运数字和a距离最近且相同,输出小的那一个)样例输入8样例输出6我的解答C++#include <iostream> #include <string> using namespace std; bool isLuckNum(int n) { for (char chr: to_string(n)) if (chr != '1' && chr != '6') return false; return true; } int main() { int a, aCopy; cin >> a; aCopy = a; int answer; while (1) { if (isLuckNum(aCopy)) { answer = aCopy; break; } aCopy++; } aCopy = a; while (1) { if (isLuckNum(aCopy)) { if (answer - a > aCopy - answer || answer - a == aCopy - answer) answer = aCopy; break; } aCopy--; } cout << answer << endl; return 0; }B.复杂去重题目描述现在有有1个长度为n的数组,求该数组中有几种数字。输入描述输入共两行。第一行一个正整数n,表示数组大小;第二行n个数为数组中元素。(1≤n≤1e3,1≤ai≤1e9)输出描述该数组中有几种数字(即数组去重后的大小)样例输入5 2 1 3 1 4样例输出4提示这题是乱序数据,但是n没有那么大了(暴力吧,少年)我的解答C++#include <iostream> #include <set> using namespace std; int main() { int n, temp; cin >> n; set<int> set1; for (int i = 0; i < n; i++) { cin >> temp; set1.insert(temp); } cout << set1.size() << endl; return 0; }Javaimport java.util.HashSet; import java.util.Set; import java.util.Scanner; public class Main { public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int n = scanner.nextInt(); Set set = new HashSet<Integer>(); for (int i = 0; i < n; i++) { int t = scanner.nextInt(); set.add(t); } System.out.println(set.size()); } }C.汉诺塔题目描述古老的汉诺塔问题是:用最少的步数将N个半径互不相等的圆盘从1号柱利用2号柱全部移动到3号柱,在移动过程中小盘永远在大盘上边。 现在再加上一个条件:不允许从1号柱直接把盘移动到3号柱, 也不允许从3号柱直接移动到1号柱。把盘按半径从小到大1——N进行编号。每种状态用N个整数表示, 第i个整数表示第i号盘所在的柱的编号。则N=2时的移动方案为(1,1)》(2,1)》(3,1)》(3,2)》(2,2)》(1,2)》(1,3)》(2,3) 》(3,3)初始状态为0步,变成求在某步数时的状态。输入描述输入文件的第一行为整数T(1<=T<=100),表示输入数据的组数。接下来的T行,每行有两个整数N,M(1<=N<=19, 0<=M<=移动N个圆盘需要的次数)输出描述输入文件一共T行对于每组输入数据,输出N个整数表示移动N个盘在M步时的状态,每两个数之间用一个空格隔开,行首和行末不要有多余的空格。样例输入3 2 0 2 1 2 2样例输出1 1 2 1 3 1D.数的反转题目描述输入一个整数,你所需要做的是将其反转,输出的仍然是一个整数输入描述第一行N表示将会有几个测试数据(N<=100);接下来的N行每行一个整数(每行得整数不超过100000000000)。输出描述输出反转之后的整数,每行一个。样例输入1 127样例输出721我的解答C++#include <iostream> #include <algorithm> #include <string> using namespace std; int main() { int n; string str; cin >> n; for (int i = 0; i < n; i++) { cin >> str; reverse(str.begin(), str.end()); int res = stoi(str); cout << res << endl; } return 0; }Javaimport java.util.Scanner; public class Main { static int reverseStr(String str) { StringBuilder sb = new StringBuilder(); for (int i = str.length() - 1; i >= 0; i--) { sb.append(str.charAt(i)); } return Integer.parseInt(sb.toString()); } public static void main(String[] args) { Scanner scanner = new Scanner(System.in); int n = scanner.nextInt(); for (int i = 0; i < n; i++) { int t = scanner.nextInt(); System.out.println(reverseStr(t + "")); } } }E.拼音字母题目描述在很多软件中,输入拼音的首写字母就可以快速定位到某个词条。比如,在铁路售票软件中,输入: “bj”就可以定位到“北京”。怎样在自己的软件中实现这个功能呢?问题的关键在于:对每个汉字必须能计算出它的拼音首字母。GB2312汉字编码方式中,一级汉字的3755个是按照拼音顺序排列的。我们可以利用这个特征,对常用汉字求拼音首字母。GB2312编码方案对每个汉字采用两个字节表示。第一个字节为区号,第二个字节为区中的偏移号。为了能与已有的ASCII编码兼容(中西文混排),区号和偏移编号都从0xA1开始。我们只要找到拼音a,b,c,...x,y,z 每个字母所对应的GB2312编码的第一个汉字,就可以定位所有一级汉字的拼音首字母了(不考虑多音字的情况)。下面这个表给出了前述信息。请你利用该表编写程序,求出常用汉字的拼音首字母。a 啊 B0A1b 芭 B0C5c 擦 B2C1d 搭 B4EEe 蛾 B6EAf 发 B7A2g 噶 B8C1h 哈 B9FEj 击 BBF7k 喀 BFA6l 垃 C0ACm 妈 C2E8n 拿 C4C3o 哦 C5B6p 啪 C5BEq 期 C6DAr 然 C8BBs 撒 C8F6t 塌 CBFAw 挖 CDDAx 昔 CEF4y 压 D1B9z 匝 D4D1输入描述用户先输入一个整数n (n<100),表示接下来将有n行文本。接着输入n行中文串(每个串不超过50个汉字)。输出描述程序则输出n行,每行内容为用户输入的对应行的汉字的拼音首字母。字母间不留空格,全部使用大写字母。样例输入3 大家爱科学 北京天安门广场 软件大赛样例输出DJAKX BJTAMGC RJDSF.表格计算题目描述某次无聊中, atm 发现了一个很老的程序。这个程序的功能类似于 Excel ,它对一个表格进行操作。不妨设表格有 n 行,每行有 m 个格子。每个格子的内容可以是一个正整数,也可以是一个公式。公式包括三种:SUM(x1,y1:x2,y2) 表示求左上角是第 x1 行第 y1 个格子,右下角是第 x2 行第 y2 个格子这个矩形内所有格子的值的和。AVG(x1,y1:x2,y2) 表示求左上角是第 x1 行第 y1 个格子,右下角是第 x2 行第 y2 个格子这个矩形内所有格子的值的平均数。STD(x1,y1:x2,y2) 表示求左上角是第 x1 行第 y1 个格子,右下角是第 x2 行第 y2 个格子这个矩形内所有格子的值的标准差。标准差即为方差的平方根。方差就是:每个数据与平均值的差的平方的平均值,用来衡量单个数据离开平均数的程度。公式都不会出现嵌套。如果这个格子内是一个数,则这个格子的值等于这个数,否则这个格子的值等于格子公式求值结果。输入这个表格后,程序会输出每个格子的值。atm 觉得这个程序很好玩,他也想实现一下这个程序。输入描述第一行两个数 n, m 。接下来 n 行输入一个表格。每行 m 个由空格隔开的字符串,分别表示对应格子的内容。输入保证不会出现循环依赖的情况,即不会出现两个格子 a 和 b 使得 a 的值依赖 b 的值且 b 的值依赖 a 的值。输出描述输出一个表格,共 n 行,每行 m 个保留两位小数的实数。数据保证不会有格子的值超过 1e6 。样例输入3 2 1 SUM(2,1:3,1) 2 AVG(1,1:1,2) SUM(1,1:2,1) STD(1,1:2,2)样例输出1.00 5.00 2.00 3.00 3.00 1.48提示对于 30% 的数据,满足: n, m <= 5对于 100% 的数据,满足: n, m <= 50经验1.抓紧过一边C++的数据STL库2.对各种变量类型的范围要把控,知道什么题什么范围用什么变量最合适3.多刷题!
-
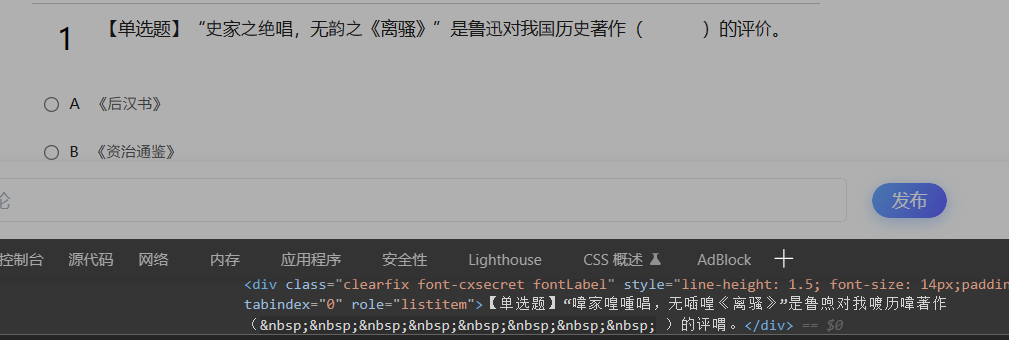
页面字体加密解决和csharp下的Ttf文件元信息混淆分析 页面字体加密解决和csharp下的Ttf文件元信息混淆分析1.前言之前获取获取未加密题目是通过安卓协议绕过题目解密,但需要多访问一个请求。打算重构一下旧项目,就研究一下解密问题。网上的文章都是基于python,javascript讨论实现的。对于csharp提取ttf元信息的文章 国内搜索引擎实在找不到资料,经过两天的google,还是淘到了...记录一下2.正文页面的字体文件为页头的AAEAAAAMAIAAAwBAQkFTRRuOGNgAAG+gAAAA5E9TLzKUGwCtAAABSAAAAGBWT1JHUavDeAAAcIQAAAN0Y21hcNpjHkAAAAKkAAACXGdseWY29gc2AAAG9AAAWFBoZWFkBmbCYQAAAMwAAAA2aGhlYQzu/tUAAAEEAAAAJGhtdHgQmAzYAAABqAAAAPpsb2NhABLFOAAABQAAAAH0bWF4cACmASsAAAEoAAAAIG5hbWWAs0JrAABfRAAAEDlwb3N0/4YAMgAAb4AAAAAgAAEAAAABAAD6ItY5Xw889QADA+gAAAAAz87zegAAAADP+IsO/Bj76AtwBxAAAAADAAIAAQAAAAAAAQAAA3D/iAH0A+j8GPtjC3AAAQAAAAAAAAAAAAAAAAAAAAEAAQAAAHwBKwApAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAEA9wBXgAFAAgCigJYAAAASwKKAlgAAAFeADIBRQAAAgsEAAAAAAAAACAAAAMq3zwQAAAAFgAAAABBREJFAYAAAf//A3D/iAH0BDEBLmAGAQcAAAAAAh8C3QAAACAABgPoAGQAMABEADgAMQA3AD8AZQA8ACQAPAA8ADMAMAAWACkAOAAxACkAPAAoADsAOgBDACoAJAA5ADUAUQAeAFgAPABRAF0ALAArADkAMgAuACIANQA3AD4AKABQAEMAIQBEACQAJwAlACwAXwA9ADYAIgAgACEAKQAlACQALwAsAC8AVQApACoAJwAqAC0AJQCKAC8AKAAoACoALwAvADsAJwA4AC4ALwArACUAXACjACIAIQAqAB8AMQAlACQAOwA5ADsAQQAqACAAKQA6ACcAMAAxADIAMQAxADAAPgArACoALABSADEAOAArAF0AOAAuAC0ALAA0ACgAAAAAAAEAAwABAAAADAAEAlAAAABcAEAABQAcVxFXFVcbVx5XIlcnVyxXL1c2VzhXPFdBV0ZXSVdNV1ZXWVdjV2VXZ1dpV3RXdleBV4pXkVefV6VXqFesV7FXs1e1V+JYClgWWE9Y2ljfWOJcvGfGa25seJ0q//8AAFcPVxRXF1cdVyBXJFcqVy5XMVc4VztXQVdFV0hXS1dSV1hXYldlV2dXaVdrV3ZXeFeHV4xXk1ekV6hXqleuV7NXtVfhWApYFlhPWNlY31jiXLxnxmtubHidKv//AAAAAAAAAAAAAAAAAAAAAAAAqOAAAKjzAAAAAAAAAAAAAAAAqP2o66i2AACo2QAAAAAAAAAAAACopAAAAACoiaiNAACoP6fwp7MAAKdhp3ajUZg/lQeTkGLmAAEAXABgAGIAagBsAHAAdgB6AHwAAACEAAAAhACGAIgAjACUAJYAAAAAAAAAkgAAAKIAtAC6AMQA3AAAANwA4AAAAAAA4gAAAAAAAADeAAAAAAAAAAAAAAAAAAAAAAABACkALwBVACQAXwA/AFAAdgAuAEcADgBhADEAJwAcAF0ADAAHABkAVABnAFYAMABeABsAPQBOADoAKwBXAFkAIQB0AD4ANgBbAHMARABgAFwAUwAWADIAbQBlAAsAUQBjABEAegAJAHkAKgBNAGwAIwBIABcAcQB3ACgALQBBABMAaABwAGYANwByABUAOwBDABQAbwAzAB4ACgAdAHsASwBaAEoADwAmACUAAwAiAGkAbgBGACwAGgAEAGoARQBrADgANQASADkAeABkACAAAAAAAAAAWAAAAHQAAACsAAAA3AAAATAAAAGMAAACOAAAApAAAALoAAADjAAAA7QAAAQcAAAEwAAABVgAAAX8AAAGyAAAB0gAAAfQAAAIgAAACRwAAAnoAAAKtAAACugAAAuoAAAMDAAADNQAAA2kAAAOLAAADpgAAA8oAAAPmAAAECQAABEEAAARgAAAEfgAABJoAAATGAAAE5QAABRkAAAVKAAAFYgAABYwAAAWtAAAFzAAABekAAAYJAAAGIgAABk0AAAZ/AAAGqgAABswAAAcFAAAHNwAAB3cAAAejAAAHxQAAB/cAAAgwAAAIZgAACI4AAAjHAAAI8wAACSAAAAleAAAJggAACagAAAnRAAAKCQAACkAAAAp/AAAKxgAACusAAAsRAAALRAAAC3cAAAvKAAAL8wAADBcAAAx4AAAMswAADMoAAAz6AAANJQAADVgAAA17AAANpwAADbkAAA35AAAOMQAADm8AAA6wAAAO5wAADy0AAA9eAAAPegAAD6wAAA/XAAAQFAAAEFcAABCIAAAQvAAAENgAABEzAAARXAAAEZcAABHaAAASHgAAElQAABKQAAASvwAAEu0AABMgAAATXgAAE5EAABPVAAAT/wAAFDUAABRjAAAUnwAAFPEAABVFAAAVjAAAFeMAABYUAAFAGT/iAOEA3AAAwAGAAkADAAPAAATIREhASEJAREJAycJAWQDIPzgAs79hAE+AV7+wgEe/sL+wiABPv7CA3D8GAO2/mf+PgMy/mf+PgGZ/mcpAZkBmQAAAQAwAWEDuQGpAAMAAAEVITUDufx3AalISAAAAAMARAAAA6AC4gADAAcACwAAARUhNQEVITUBFSE1A2z9EgKg/Z4C5PykAuJDQ/67Q0P+pkNDAAAAAQA4/+QDrwMzAAsAACUVITUhETMRIRUhEQOv/IkBeEYBev6GJkJCAw3+ykP+bAAAAgAx/7YDugL8AA8AFQAAAQYHESMRBgcmJyQTITUhFQUWFwcmJwJgGDFHpM0UGgExqv49A1f+wuxsNHfeArkpSP1uAjm+bR0cmAEkQ0Osl3AyfpAAAgA3//gDswM/AAMAHQAAAREzEQERIxEhFSERIzUzNTMVMzUzFTM1MxUzFSMRAg/H/ve9Aob9NJOTRr1Cx0WYmAII/wABAP7CAT7+MEACEEDg4Pf37OxA/sIAAAACAD//swOqAv0AAwA4AAABNSMVOwERFAcGIyYnFjcyNREjBgcWFwcmJwYHJic2NyMGBxYXByYnBgcmJzY3IxEjETM1ITUhFSECUL7/7ysilgUSYz0YrwIIeS0oLGElZhQbhg2/AQlPGygZOShiEB6FDaRC5/7uA2v+5wItkJD94D8PCyEiBAMYAeA2L45UMlR3lGceEX/7KT9gNTUzTZViGxSB+f3FAnqQQEAAAwBl/7YDgQNEAAMABwAXAAABESERIxEhEQERIzUhESMRIRUjESE1MxUDPf7XRf7YAtpE/tdF/thCAWpFAT4BEv7uARL+7gFT/jE6/roBRj8B1LOzAAAAAAEAPP/WA7EDPwAaAAAlFSE1ITUhNSE1ITUhJic3FhcHIRUhFSEVIRUDsfyLAZX+xgE6/poBwD1yNnk9LwFG/pgBP/7BF0FB/0DkQEpWJVdMIkDkQP8AAAADACT/tAPEAzMADAAQADAAAAEzFRQHBgcmJzY3NjUlMxEjExYXBgcmJyMGByYnNjchNSE2NwYHJickNxcGBwYHIRUBL0MkMoIRIXkuIAE8REQhb8kXFt92onbYGxO9b/7qAUEjF6SRAg0B294xh9UWIwHpAXp0bUZiPRwVN1Q7XXL+PAJVkkASJk68sl8mEUqQQD5CCwMcHQwxNR0QQUVAAAAAAAIAPAAbA60CtAADAAcAAAEVITUBFSE1A1n9NwMd/I8CtEdH/bBJSQACADz/7AOvAuIABQAdAAABBgchNjcTFSE1MzY3IzUzNjchNSEVIQYHITcXBgcBthwgASMVC/L8jfYeIL3IFwr+4ALq/n0KGAEICzIKGwF/raTCj/6vQkKJyEGVS0JCRpoDBbTcAAAAAAMAM/+0A7wDSAAOABwAKwAAAQYHFgUGByYnBgUmJyQTAyYnBgcmJzYTFwYHFhcTBgcSFwYHJicGByYnNhMCMQwPkgEUFxf9nI/+/BMcAUR6Hz5jPYUWI7sqQwkThzjECAtMtBMbl1M5hw4qvyEDLhkX1EkWJU/XzGAkGWoBAf0RTFXOcRQWjAFuBkxTakcBSkc5/wBcESlZ0sdtDhyLAXEAAAAAAgAw/7YDvQNCABcAKwAAEyEVIQYHJSYnNxYXByYnBAcmJzY3NjchAQcWFwYHJicGByEVITUGByYnJDdcAzb+R29jAddENTiaSjsOK/2zIQ0KFzRVWP7cAd0dpvsZFuewXo8B2v4jUlUVGwFChwFOQJNcJUwzHYl+Ixs4MgwtGAQxTnsCGSixWRUlXrlrWj48NCchGIrPAAACABb/tAO1A0AACwAyAAABBgcRIxEGByYnNjcBBgchNxcGBxYXByYnNxYXNjchNjcjNTM3IzUzNjcXByEVIQYHIRUBTzI3QCZEERWfWwERBSIBRwovTZBKJjJepDArN1VH/pkOL7jLJLbGEQ1BHAEh/s4SEgGDAy17X/1jAjo4SicanPX+kxJrBR5anzgmMmVoJxskXFMmlT5/PTw2CWk9RTo+AAYAKf+zA8IDPgAHABMAFwAlACoAQAAAASE1MzUjNSElBgcRIxEGByYnNhMXFTM1AxUjESERIxUzFSMVMxU3Fhc2PwEGBxYXBgcmJwYHJic2NyYnNyM1ITcDi/7p2toBF/2MHiY/IyQKGnE+opaWPgEP0bq6xWQbOjseSCVZSF8WE1xIUnwNFXdWQCQsQgEPCwHnOrs6GXBi/VgCHkIvHyOVAQVhvr79osgDX/7QcTmEOd1qWVJxLrByWCYUHypZVTIcFSpdYoQLOQIAAAMAOP+9A8ADLAAGABoAIQAAAQYHJic2NwEWFwcmJwQHJic2NzY3FwIHJSYnExYXBgcmJwGQaLIlGbJhAVihUEAeJv23IQsPGj92fEaOiwHiN0ktdLkeGrZ/AxL8nyAPi/T+Cr6RIzc4JwwoHQZPgv4g/v6jG1BaAhntkBcio/oABgAx/7UDrAMwAAMACQAQABYAHAAiAAABFSE1BRYXByYvAQYHJic2NwMWFwcmJyUWFwcmJwUGByc2NwOs/I0CZLdYPFez6nKpFxmqWrlvLT8rbgFmWhtBG1cCM3xqPH9dAWJAQHmfailwoAimdB8WbJMB/pqGHoafYqGMGYumH/SPG6nZAAAAAAQAKf+2A5QDGgAFAAsADwAyAAA3NjcXBgcTFhcHJicBITUhNwYHAgcGBwYnJicWMzI3NhMhNSM2NxcGByE2NyE1ITcXBgMpU0Q6PlIHayo/KGkCyf4lAduVAQIfNxo1PGoCElBUIg4sHf40FhMNQQoOAR0TEP5IAcQLMAkeBZ69IK+sAzWOXx9jjv2TPsAWCf6bNBsDBAghHAgMKAErAXi0BXxuh69ABAZs/vgAAAAAAwA8/68DlQNAAB0AIQAuAAATIRUhBgczNxcCBSYnNjcmJzcWFzY3IwYHJic2EyMBIxEzNxEUBwYjJicWNzI1EUIB+P7yFBnnDChF/qkRGJ1jRVgnWUE+HOs1QxkbczqnAoVBQc4nH3UHEGAaFgMMQFRKAw3+KJ0gGD+RQjgxODlwj4ZTGRKIAQL92AIpc/zOOhAMICACAhYDMgAAAwAo/7MDlgNDAAUAIAA9AAATJic3FhcTJicRIxEGByYnNjcjNSE3FwYHFzY3FwYHFhcBAgcGBwYnJicWMzI3NhMjAgcGByYnNjc2EyM1IfsaPDM+Gk0tP0RBPxITr2L/ASANJytRJDYbLzsmNR0B7xIyGjE0XwQQTEIaDysTyg4wO4UTIIA2LAuqAfkCmztRHE05/gFCTP5qAYpMMywRhtA9AxtvcSg4KiY9ITohAdT9Wz4jBgUHJhoGETACdP7ZocJwHBdiuZUBF0AABAA7/7YDmANHAB8ALQAxAD4AAAEGBSYnNjcGByYnNjc2NyM1ISYnNxYXBzMVIQYHNzY3FwYHFhcHJicGByYnJBMXIxEzNxEUBwYjJicWNzI1EQIMhv7rEBqkeuAXBRATJjg5yAEEEyU8MBIG2P76RkzVJxV+OlZwMTAvbISjFRcBPpLRPz+2KCGCBhBaLRgCKv6VHhhNiQ4JGSYDJjtZPjg5EEE+Aj5oTQk3K9VlWmA7KzlkeVIiFosBB9oCKWf82DsQDCEeAwMYAygAAQA6/7UDtANCAAsAAAEhESMRITUhETMRIQO0/mRG/mgBmEYBnAGK/isB1UQBdP6MAAAAAAUAQ/+0A68DQQAVABsAIQAyADgAAAE2NyE1ITUhNSE1MxUhFSEVITcXBgcFJic3FhcFFhcHJicFBgUmJyQ3ITUhNjczBgchFQUWFwcmJwL5ICb9FwF+/r8BQUQBSv62AUkLLj4w/n9JdSN7Rf7bc0wjQnoBk1j+ogsXATtT/m8BqhoIRAoXAXb+lOCTJpfUAY4qSDthO2pqO2EDE4A6CjcjKSUyCB4zLTAlps07HxkynjxQnp5QPDxGTjZTRgAAAAIAKv+9A8MC/QAEABkAABMSFzYTNwIHFhcGByYnBgcmJzY3JgMjNSE39lepu1FRUtus8RYW+auu8g4b8qiwYFACtw0Ct/7zr7IBCjH+vNaaOxMoQ5+UTyUWSoy5ATBCBAAAAAADACT/sQO/A0cABQAKADoAAAEmJzcWFwEWFzY/AQYHFhcGByYnBgcmJzY3JicGByYnJBMjIgcmJzY3NjcXBgczNjcXBgchByEGByE3AyIeYjJaKP5PO2trNFk8h4m2FhPBiYOzDBeihF4+bLwUHQECZo1cDRIFERIqGEggKrwdDUoSFwG1Af46EhMBWAwCfyprH1o1/syAWl58LbV6XyMUJy1mYDIdGyhdV3fFdR8TnwFKEDYKBCNGaw1nU256DHxgQT8vAwAAAAYAOf+2A68DRgAGAAwAEgAgACUAOwAAAQQFJickNwEmJzcWFyUWFwcmJwMjNSE2NxcGBzMVIzUhFxYXNj8BBgcWFwYHJicGByYnNjcmJzcjNSE3A2D++f4OAQ8B6vD+tAopOyoN/r42EzsUMx0/Als9JEIrNbFB/TGhR4ODRGNJoaHXFxLpp6jvDxfdoINOBSkCKA0DETkVESgVNf7nQ1MNTkaCTDoUP0v+rclcUhVPSsmOtmlNS2sll2dMGhsjIl1XKCIZHkxXfwI+AwAAAAACADX/tQNNA0YAAwAnAAAlNSEVBSM1IRUjEQYHJic2NyYnNxYXNjchBgcmJzY3FwYHITcXBgUhAwr+OAILQ/44QltOCRnKrkVZMl9JpVj+hWeJExvhbkofIwFsDCx3/uEBmyjr63M2NgFOIBIgHSpfQT0mQEFlg2RIHRVtsQ8wKAQc45QAAAAAAwBR/7YDswM+AAMACQAdAAATETMREyMVIxEhASMRIxEjAgcmJzYZATY3FwYHFSGQjEHNPwEMAlaFQ80EfxUjd/p2On/nAZUCp/5BAb/+AEwCjf7X/fcCCf6kqxgToAFTAQUvNDQxLK0AAAAAAwAe/7cDggM6AB8AIwArAAABMxUjFRYXByYnESMRBgcmJzY3IzUzNQYHJickNxcGBwERIxEBESM1IxUjEQE/s7NsPSknWUNUZQkcgE62xkpfBQ0BC28uRWUCAOkBLEPpQQIePht1UTZAb/4/AcXGbRQpgtg+rAwMGB0kLzQZFv2cAjT9zAJ0/QBMUwMHAAAABgBY/7QDmAMZAAMABwALABMAFwAfAAABIRUhFyERIQEVMzUlIREjNSMVIyU1IxUBESM1IxUjEQLB/moBlkP95gIa/ZPc/uUBXULcPwL+8AEyQvBAAtnHQAFH/gz6+kD+WS03d/r6ATr+VjA3AbEAAAUAPP+0A68DEAADAAkAIgAmACoAADcVITUFFSMRIRUBIxEUBwYjJicWNzI1ESE1IREhNSEVIxEzJSEVITcVITX6ASr+1kEBrQFJeicefAYTZRwU/UwCqv1sA0lxhf6G/sUBOz7+TMttbaIsAQPXASj+sjYOCxsjAgISAU07AUo6Ov622WWWx8cAAAAACQBR/7gDywNHAAMACQANABEAIgAmACoANwBHAAATETMREyMVIxEzATUjFTUVMzUTFAcGIyYnFjMyPQEjFSMRITchNSEDIxEzNzMRFAcGIyYnFjcyNQMGDwEWFwYHJicGByYnNjeIbDaiN9kBEI+POhoVRwQOHyMMjzsBBMX+iAF4Rzc3WTgeGl4DEU4UEJAECA1rvh8Ls296qg4c4nICwf4qAdb98mYCrP3BWFjgVFT+aC0OCyEaAQyEzgIYRjf+DAFmJf4fMA0LGSACAg8DKwQMEW1LHRdScoJLGBhapQACAF3/1gOJAuwAHwAnAAAlESMRFDsBMjcWFwYrASInJjURIwYHBgcmJzY3NjcjEQERIzUhFSMRA0TNGmcoEAIDDi1xLxIQkwQjLHsLHW4mHgPFAupF/VtCYgJK/r4sBR8aBRgVOQFB4mN7OhkbM21W0P22Aor88UVMAxYAAgAs/7gDpwNDABUAJQAAAQYHESMRBgcmJzY3IzUhNjcXBgchFREVITUhESM1MzUzFTMVIxEBgjNFQzhBCxehbPYBEiEWRBsXAgn9pgEL5ORC5uYCZnBc/h4Bkj4tHB5z2kBKUxFTOUD9pD4+ASQ+xcU+/twAAAAAAQAr/7IDxgNCAB4AAAESBQYHJAMGBzcWFwcmJwYHJickEyE1ITY3MwYHIRUCM3MBIBwW/uF7I1sahUM4PYBlqBUcAUtF/oYBhAoCRwILAaAB9P51ehgliAGVsoESaVctU26DSyEWigF/RE68q19EAAQAOf+0A7IDRAAZAB0AIwA0AAABJicGBSYnNjc2NyE1ITY3MwYHIRUhBgcWFwEVITUFFSMRIRUBIxEUBwYjJicWMzY1ESE1IQNCldVW/vYIFp5TTiL+sAFjCQdFBgkBb/6ACATaof1vAQj++EABiAGJjC0olwYTNHQZ/VcDeQHFSk11JRcdFSspSzskOzQrOxQITE3++5CQx0IBQP4BUv6NOg8LHCQCAxQBcj0AAAAAAgAy/7UDrQNPAAYAIgAAAQYHFhc2NzMGBxYXByYnBgUmJyQ3Jic2NyM1ITY3FwYHIRUBgTgtem9sL0szb8KJN4XDmv7cDRgBD42Miz8/9QESPRpHIDICDwIMhVkwM3PO5H5cXzpiX4UyJxsocEE1a5JGm2ILcYFGAAAAAAYALv+2A7YDQwAFAAkAEAAXADMAOgAAASYnNxYXByMRMwcGByYnNjcFBgcWFzY/AQIHFhcHJicGByYnNjcmJzY3IzUzNjcXBgczNwECBSYnJBMDeR1UN1Mk90BAih82GR8zHf7WJRwQXDcSQhRFSSAsJDVGcw8ZakY+WSQmYm8XCj8NFncLAihv/ngMGQF0agGDfJMUiYW8Ame1y3MPDGjGYaReC0WMxjj+76I9ITIoLYVHHxY6hzVBZrA+gksEW24C/tL+zmIgG08BHQAAAAAEACL/uwO5Az8ADwAWADIAQgAAASE1MzUjNTM1MxUzFSMVMyUGBxYXNjcTJicGByYnNjcmJzY3IzUzNjcXBgczNxcCBxYXBRUhNSE1IzUzNTMVMxUjFQOo/dvqxcVC1NT5/RIUJD0mLBE1ITtCbxIWaT9GRx4kU14WBzsLE20MJRE7SiYCM/2VAR/X10Lk5AGbP6A+hoY+oF9jliofgsD97iw5iUgeFj2LPi9gtT2DRgNjYwIG/vqeQDQ/QECvP3NzP68AAQA1/7QDtQMCABwAAAEhERQHBiMmJxY3NjURITUhNTY3ITUhNxcGBxUhA7X+ZDAnnAgWfDYb/mABoI15/b4Cig4yh8MBnAFF/so/Dw0hJAQCAxYBNUKSP2VBBCaDY28AAgA3/8MDqwNNAA0ANAAAEyM1ISYnNxYXIRUjNSEBMjc2NxYXBgcGKwEiJyY9AQUnJTUGByYnJDcXBgcVJRcFFRQXFjOXQwGKGxdBKRYBa0X9RQJ9Kg0NBRkpCBkbTOVUHh7+nQgBa2mVBRABjag3bqUBugn+PQ8OMAIKzjwlFEMyzo/9axwbYhMKciQnFxhEuipAKaYUFBofNkg0KyKsMjw1wh8JCgAAAwA+/7oDqwNHAA0AEwAoAAATIzUhJic3FhchFSM1IRMWFwcmJyUhERQHBicmJxY3MjURITUhNTMVIZlCAZESIz8tEQFfRv1QVXQzNzRwAvH+/i4mlQQUZT4a/dkCJ0QBAgIGxC89EUc2xIT+vW5iJmduWf6VPg8NAhcrBAMYAWpBkZEAAgAo/7QDwgNFAA0AJQAAEyM1ISYnNxYXIRUjNSEBFhcGByYnESMRBgcmJzY3ITUhNTMVIRWZQwGNEh1BJhUBZEX9SgGykeYfEuWWRJPoFRrgj/64AYNEAYICAc0wNRI+Oc2O/ufjcBsff/P+WQGs/IMgF3LsQKSkQAAAAAQAUP+1A5gDSAADAAcAEwAhAAAlFSE1ARUhNQEhESM1IRUjESEVIQEVIzUhFSM1ISYnNxYXAREB5/4ZAcT+PAIrRP4ZQwJJ/foCh0X9P0IBmA4WQhoSrY+PAWCEhP7b/tIoLQKT+gGTrm9vri0rDzA3AAAAAwBD/9IDpwNKAA0AIQAnAAATIzUhJic3FhchFSM1IQEVITUhNSE1ITUhNSEVIRUhFSEVNxYXByYnmUEBlB0dQC0YAVhD/U0DDvycAYz+7AEU/tQCov7QARz+5IBsODA+ZAH3zT83EE05zY79iz4+0j6mPj6mPtK/UjcoP1EAAAADACH/tAPHAzQADAASABkAAAERFAcGIyYnFjM2NREFFhcHJiclAgcmJzYTAhswJ5QJEjJyHAEsmytFKZX+VUV5HB56NQM0/OJEEQ0kJAIBGwMe4PTBIMf0A/7YkBgQjQERAAAABABE/7IDoANEAAUAGAAcADQAAAEGByc2NwEjNTMmJzcWFwczNTMVIRUjNSEXNSEVBQYHJSYnNxYXByYnBAcmJzY3NjchNSEVA0E6OzY7LP2iQ7ggPjtEHj27RgF5Rf1UIAJh/pxjZgHwQjs5oUM+Fx79oyQLDBkvRVz+4wNcAxpTPBdETf6TxUBMGk08Hbm5xYqiPz+yh10gTDgflHIjJyYtDSkeBS87gUFBAAMAJP+2A6wDEwADAA4APQAAExUhNQUVEAcmJzYZASEVAzI3NjcWFwYHBisBIicmPQEFJyU1Byc3NQYHJickNxcGBxUlFwUVJRcFFRQXFjPNAmD9oG8aIGcC5TshCwoEFyYIFRc/0UsaG/76CgEQ4wvuS4oFDgFFkjlbjAEfCv7XAWYK/pAMDSkC2Hd3sjb+f7kWDKsBbAEk7f3aFRVHEApZHB8VFj5SKTgqYiM2JlsOEhcaKjgsHxxeLDYuYjg3OlscCAkAAAAABAAn/7MDsgNDAAMABwALADkAACUhNSEBIRUhFSEVIQUhFSMRBgcmJzY3IzUzFSE1MxUhNTMVIRcGBzMmJzcWFyEVIRUzFSMVMxUjFSEBCQEU/uwBFP7sART+7AEUAZX9V0IwPxgZoViwQwEeRAEcRf2xOhgc/w0ePCURAR3+z/z8/f0BUx5kAS5hNmHSMwGxNjEgFHC0x4uysovHEjEpIDYQMjQ5YTZhNmQAAAIAJf+/A7sDBgANACgAACUXBgcnNjcRIzUhFSMRAQYHIQYHAgcGBwYnJicWMzI3NhMhNjcjNSEVAaIHiewPPWWZAWiMAWwjGwFqAQEcNBo9O3gDF1pfJQwrGf6HKSiWAh/0PyE2RAsXAbtCQv5SAfOlbhcJ/oYzHQUDCCAjCAskAUCFzkJCAAADACz/tAO/A0wAEAAoAEsAABMQByYnNhkBISYnNxYXIRUhATUjNTM1BgcmJzY3FwYHFTMVIxUzFSE1JwYHFjMyNwYHIyInBgcmJzY3Jic3Fhc2Nyc2NyM1MwYHMze3VRMjSgGbDhk8GRcBW/0GAfmWlj9dBQz0ZyI3W5eXt/5QEhpIXtHlKhAI+ehpNk8SGFE2MCEyGigzF7U+QpLyP0BnCwHA/qCsFBKbAUsBJyspESc+Pf36rTqFCgkZGR0nMxQSjzqtOjrSsHNRARkjXEErHRApQj9rE1k0VXYBXHw4c2gCAAADAF//rgPHAzAABgAiAD0AAAEGByYnNjcBBwIHBgcGJyYnFjMWNzY3IzY3MzUjNSERIwYHJRIXBgcmAyMRNxQXBgcmJzY1ESM1MxEzESEVA5BiqCUOolr+HgIQJBYrL04EETREGAsaDsgRC6zFAQWzCwUCLkitHBK6TGedBOASCxItc3NBAY4DA7BzIgllpv49Hf7KJxgDBAUjGAQBCxr8dbGhPv7igycr/t9lFx57AUD+nzwhHF4QIxcULgFUQAFy/o5AAAAAAAsAPf+6A78DLgAGAA0AEQAVABkAIgApAC0APgBEAEsAAAEGByYnNjcTBgcmJzY3JSEVIRUhFSEXIREhEyE1Myc3FhczAQYHJic2PwEhNSEXFRQHBiMmJxY3Mj0BIzUhFQcWFwcmJyUGByYnNjcDiWegGxaeXF9uuxcYu2D+ff7HATn+xwE5Qv5GAboi/fLrGTwWDd3+iyZHGhVBIhcBKf7XtB4XXQQQRxAOsQGoTkAgMyA7Ahp35xEd4W4DFYhiHw9Yff7bkWYdEV6FzkAtQS8BC/57NzAPIh3+r1tIGA08UkpaiqwuCwoXIAICDau6uhhOQBxGTW/BbxkZZLEAAAAFADb/wwOwA0QABQAcACIAKAA4AAA3NjcXBgclMjc2NxYXBgcGKwEiJyY9ATMVFBcWMzcmJzcWFzcWFwcmJxMVIRUhFSE1ITUhNSE1MxU2PyY8LTgCESgNCwUYJQgXGUbqUxwcQQ4PL7xLky6VS5tgKEEsV8b+ZQFf/QcBVf5rAZVFBFSfFatSGhYWURAIYh8gExM63d0WBweTVVYpVlFCnmkafY4BxUCwQECwQJSUAAgAIv+2A7oDRAADAAkADwATABcAGwAfACMAABMRIxEHBgcnNj8BFhcHJiclFSE1ARUhNTchNSE1ITUhJREhEfdALAooNyYO4DcTMhUzAqP92QI4/aiSATb+ygE2/soBeP5HA0T8cgOOx59rE1yjIGtDG0pqfT4+/R4+PpeVOJM7/ioB1gAAAAAHACD/tgO5A0MABQAJAA8AEwAXACgAQAAAEzY3FwYHEzMRIxMWFwcmJwE1IRU1FSE1ExQHBicmJxY3Mj0BIRUjESE3FSE1ITUjNTM1ITUhNTMVIRUhFTMVIxUgIA8yCCRGPT14Jw8wDCcCRP6NAXM/IRxyBA9VGxP+jT8B8VD9dwEh7Oz+/AEEQQEL/vXy8gGGW6QHm28Bz/xzAvlPPBk4Wv3oUlLVUFD+qDENDAIUJQMCEU+cAdhxNDRLMkM0UFA0QzJLAAAAAAMAIf+uA7wDPAAFAB4AQgAAASYnNxYXASYnBgcmJzY3Jic3Fhc2NyE1ITcXBgcWFwEGBxYXFjcWFwYnJicGByYnNjcmJwcnNyYnMxYXJRcFFhc2NwNPLV4vYSz+ASFCU3oSHntXTGMwPWM2Gf7WAT0LKx9NTCsBxzxxNEsmDhUjGk9xRVZgFSByYSsWjweQDAZEBQsBJgj+2RAjXDMCjD5MI0c+/ZZAaZlaHxhSqnSHJU+MgZo8Aw/hq3BOAUWhho4HA6UVD9IFCaBaNRwVN2uGzxA8EXuPk28hPCKgf3eIAAAAAAIAKf+uA7oDQgAFAEQAAAEmJzcWFwcGBxYzMjcWFwYHBiMiJwYHJic2NyYDIRUhFQIHBgcGJyYnFjMyNzY3IxUQByYnNhkBISY1MxQXIRUhFhc2NwNUPnYncUUJQW48UCgIGh8JFxc3bUxeeBcZiGU4E/6bAQEHGREoLksCETA+FwgSBcBqGh1dAaQFRQQBRP7BDypUMwKcOT4pNzzXxY2huRoJfS4uqWVGIRVIdKUBBIce/tAeGAQEBSMbBAoU8hL+yJkeD4cBHgEWXU9jSUHRl3mdAAAAAAQAJf+zA4kDQwAdACEAJQAzAAABBxEUBwYnJicWNzY1EQcnNjc1IzUzNTMVMxUjFTcBNSEVERUhNTcRIzUhFSMRMzY3FwYHAXp+IxxqBRBTFBSCEk9FhoZDdXV2AdP+pQFbRET+pUGoHQ9MEiQBUCf+3TYPDgIfHwICARMBDidEExTeQcvLQcoi/p719QIk7+8//S0xOALaW1cJQGkAAAAFACT/swO3A0MAHwAjACcALwBMAAABBxEUBwYnJicWMzY1EQcnNjc1IzUzNTMVMxUjFTc2NxcVITURNSEVAyERIzUhFSMBMjc2NxYXBgcGKwEiJyY1ETMVNjcXBgcVFBcWMwGGhyIfYwMSLjcThhRFVY6OQXh4Py0SfQFR/q8/AdJC/q8/AXcqDAwFGyMIGBlI71MdHULhaDSC+w4OMQFXKv7YNBAOAhkkAQESARUpQRIZ3T/Lyz/KEw0GaWpq/u9wcAFL/lMqLgJGFhZTEwdjHyAUFD0BHJgwLjE0ME0ZCAcAAAADAC//swPBA0QABQAJADgAAAEWFzY3IwMjFTMBBgcWFwYHJicGByYnNjcmJwYHJicRIRUjETM1IzUzNTMVMxUjFTMnNhMXBgchFQJPJUpOINvZ4OAB9ylkXYIZFYBaYqkMG6xiRSolJgsZ/uE/jri4Qra2jRN3N0ITGgFVAkbKjIjT/vzhAeX9nYs6FiJBhXtMHB9FgX60TDIMEf6iSAGnuz/ExD+7DY8BIQpdUUAAAAIALP+zA7gDRAAoAD0AACUVIzUHJzY3NSMiByYnNjc2NyM1MzY3FwYHMxUjBgczNTMVMxUjFTcXASMRIxEjFRAHJic2GQE2NxcGBxUhAVZB2g+MXWo+DgcPExwXIn+PDwlECBHh8ictdkGJiY0EAdF/P513Fxlp4HErdsgBW5Lc0CdEFBCWDhkkBkw3dz85QA0oRD+Ha5OTPYsXOwEL/fwCBCn+wp8ZEY4BJQFMJC85LB+0AAYAL/+5A7oDRwAJAA8AFgA1ADsAUAAAASE1MyYnNxYXMwUmJzcWFwMGByYnNj8BERQHBiMmJxY3MjURIzUzNSM1ITY3FwYHMxUjFTMVBxYXByYnJSMRIxEjFRAHJic2GQE2NxcGBxUhAff+SskUGTsmEqf+tgchNSUHISVCFRo/ILAcFVEDEDkSDcvLzwEVIRg9IBmDyb5kPhYwFj0CUXFAomkYG1/TZTZpyAFTAqE5Ly4QQC3hR0wNTET+129PExBDZij++iwPChwdAgINAQU6bTlOVg5cOjltOiRhPxpAYtv+BAH8Jf7DlhwNhgEkAVMkKTApIMQABgBV/68DkwMYAAMABwANABMAFwAsAAATFTM1ETUjHQIjESERJTUhFRQHExUhNRMUBwYjJicWNzY9ASEGByYnNhkBIZOtrT4BKQHT/usHBwEVQikmhgQUWzgY/tsjjxYbsgGYAsjHx/4tz88+XgKs/bJ6uDJEQgGptLT9Nj0QDRcrBAMBGOTPdh0PkQFLAWEABAAp/7MDvQMZAAMABwALACwAAAEhFSEVIRUhFyERIQEWMxY3BgchIicmJwYHJic2NxcGBxYXESE1IRUhFSEVIQL5/fACEP3wAhBD/WwClP7hOUJpvBEH/vGkWWY5OWUYG5wpQgsONo3+ZANu/nEBTv6yAuZXMVgzAUb89QYDBB4iIiZld0wdEmblCjgtgSMBNTw8djwAAAACACr/twPAA0QAHAA1AAAlIRUhFRQHBiMmJxY3Nj0BITUhNTY3ITUhNxcGBxMWFwYHJicjFSM1BgcmJzY3ITUhNTMVIRUCEgGe/mIqIIIIF24lFv5qAZZWV/5rAeYPK2GVTZDRFxbskwFDj+wQG8+K/roBk0MBm9w9mzQOCxwhAwIBEZo9Nhw0OwQkSz0BoI5BFCJUseHhs1kdF0iQPnFxPgAAAAQAJ/+1A8cDSAAMABMALwBHAAATIzUhJzcWFyEVIzUhFwYHFhc2NxMmJwYFJic2NyYnNjcjNSE2NxcGByEVIwYHFhcFFhcGByYnFSM1BgcmJzY3ITUhNTMVIRWSPgGHJjckEQF5Qf055TMZf2FiMbp3y5j+2wkR5Ipngz0w7QEeJx88IBoCAMEwV8Jt/r+S5hcT95NCkPEUFeSP/p4BmUIBnwJpjj0UNB2OVaU1FhQULkX+/SwsPxUgFgwoFRM3NjgtLxMrHjhQNSsll4IzFiFCm+nklUEiEzOCOVVVOQAAAwAq/68DxANDABYAMABIAAATBgcmJzY3IzUzNTMVMxUjFhcHJicVIwUXAgUmJzY3Jic3Fhc2NyEGByYnNjcXBgchAxYXBgcmJxUjNQYHJic2NyM1MzUzFTMV8kpUEhhpSaG3PaagUkklH109Ah8spP3cChrroF1XM2ZbfUL+qW6DGhbybEEQJQE2CVF5HBBmVD5MWA4ebE+UqT7TAmN0OhsTPX46a2s6OkM1J1TTKx/+wl0iHCFMQCclLD1JZ042HBNcgBkSIwE4fEEWGkF82s9yORQbOn06a2s6AAMALf+xA74DQwAWAC4AVQAAAQYHJic2NyM1MzUzFTMVIxYXByYnFSMlBgcmJzY3IzUzNTMVMxUjFRYXByYnFSMBFjMgNwYHISInJicGByYnNjczBgcWFxEhNSE3FwYHJzY3IRUhFSECpEtcEhluS5GqQLWxUnQmMHRA/lhHWhQXZ02Xr0GOjmklJRpPQQEWMzwBDTAUBf7anFJdNDV0DhydIUUJCzCD/oEDFQswKSU7GBb+zQEf/uECfnE8HBM5czpdXTpAaDI5bcLDbDwcEjd2OlxcOgFHJTEiR8T+UgYBHCMiJmR+Ph8TUO43KosjAUA9Aw1jOQ8nM388AAYAJf+2A7YDRAAFAAsAIwA7AEIAXQAAAQYHJzY3BSYnNxYfAQYHJic2NyM1MzUzFTMVIxYXBgcmJxUjBSYnESMRBgcmJzY3IzUzNTMVMxUjFRYfAQYHFhc2NycHIRUjBgcWFwcmJwYHJic2NyYnNjcjNTM2NwN9Qx4vNCH+qyAsMzMcSGN8Dhx8YsXwPvXLaXobEXhpPv7RDDs+MzwNFl4vdns+Y2MNY90gHGAvRxxyIwFJcRtMd1EvS4NrwAkTpVxgTyIwlrYOGwMYaicWSkmpRkIYTDl7bUEWGjhlOcXFOWUyGBo+batCHm797wHhtV4fIIj5P8HBPygSnoI5JiASOFmESjpkRi4pMCo1RB4gGBYvJBkrTzoaPQAAAgCK/78DugMzAAUAKwAAASYnBgcVBRYXFjcyNzY3FhcGBwYjIgMhESUUFwQHJic2NREkNxcGBxYXIRUCIQ8Dk40Bfh85PE4YCwoFGh8JGBc310n+xAEfBf6rFwoTIwG8zCJnngIQAUsBwHWGEgveQrJjaQEiIVYYCWwnJwG//q9QJRdmEB8bFCwCkSI7Ox4Vj3ZCAAgAL/+2A5QDQgAFAAsAEQAVABkAHQAhAC0AABMmJzcWFwM2NxcGBwMWFwcmJwE1IxUjMzUjERUzNTMVMzU3ESM1IRUjETM1MxXpRHYkdkS9WEwyUksDdUwnPYIC8rTura2tQbRBQf5eP+xBAYk3NjEzM/4ugpgqo3gDczE6NzQ+/Srl5eUBHNzc3NxA/Us0OwK80NAAAAAABwAo/7YDsQNDAAUACwARABUAGQAqAEIAABMmJzcWFwMmJzcWFwM2NxcGByU1IRU1FSE1ExQHBicmJxY3Mj0BIRUjESE3FSE1ITUjNTM1ITUhNTMVIRUhFTMVIxX0NmcnaDhTN2wmazuuUkw1PVoCmf6NAXM/IRxyBQ9WGxP+jT4B8Ff9aAEo6+v+/gECQgEL/vXy8gKZMzouNzD+wDU7Ljc0/iiOuSiXr8RTU9VQUP6oMQ0MAhghAwIRT5wB2HE0NEsyQzRQUDRDMksACgAo/8MDtwNDAAUACQANABEAFQAmACwAMgA4ADwAAAEGBzM2NxcjFTMVIxUzJzUjHQIzNScHJic2NxcGBzM3FwYHMxEhAyYnNxYXAyYnNxYfAQYHJzY3ARUhNQHqJTTRJCyFsrKysvGurusqHhWZV0AOFMoOKyc9yv3mT0NrJXM8WkZqJm5CHEJZOlROAtD9VgK0PEAsULOCNYO4goI1g4OyKCAQe8QTHiQEH0xP/lcCBjw4Lzg1/sc7MDEvN8KepSeLuP73Pz8AAAAABwAq/7UDwANCABMAGwAfACUAKwAxAG0AAAEjNTM1MxUzNTMVMxUjFSM1IxUjBTUhFSM1IRUlNSEVJSYnNxYXAyYnNxYfAQYHJzY3BQYHFhcGByYnBgcWBwYHBgciJyYnFjMyNzYnBgcmJzY3JicGByYnNjcmJwYHJic2NyM1IRUhBgcWFzY3AdWurjyzPLKyPLM8AZL+DzsCaf4KAX/9yC9nH109UDpkHmQ8KFVIL1lJAp4tRzV7GBB+ORgiIQcGKCM2FDgEDCkoKBM2H43EDRPbhQ0TcaMLEqprExtiXwwUomrnAkz+6x8tOSFtWgLCNExMTEw0QkJCt3BwoKACLS3OMD0wMDf+xDUwMi0zw7+ALZmmHB8jnjURID+vDQ5BPDscGgICIRQEDSFeZzQZEi5uFhlNKhkTIUgTEysZFhYkODMzFhcqMDE+AAAEAC//tgOpA0QAEAAWABwALQAAAQIHJic2EyM1MzY3FwYHIRUDNjcXBgclNjcXBgcTBgcSFwYHJicGByYnNjc2NwFbO7oXILE2zNQIBEYHBgIu0DoqOTYz/mgnGzgjHfIHEV3bFxW5akbmExbCRi4KAoX+VL0bGacBjkA+QQRPLED+oFdlHG5NBUOGFJc3AV2aYf74YRIiXd/mWyAUSbBz/QAAAAYAL/+0A7IDRAADAA8AFQAbACEAJwAAASEVIRchESERMxUhFSEVIQE2NxcGByUWFQc0JyUWFwcmJyUWFwcmJwL8/e0CE0P9awEhQgF9/oMBMvzwUDk/PU8BLRlDFgELOBJAFTEBBWAmPyVcAdS8PgE4ATJuP4X9v0aDEItL0nBPCV5lDW9QD1tlH3VTGlh0AAoAO/+zA7MDSgAcACIAKAAsADAAQQBVAFsAeAB+AAABIicmPQEzFTY3FwYHFRQXFjsBMjc2NxYXBgcGIwE2NxcGByUWFQc0Jzc1IxU1FTM1ExQHBiMmJxY3Nj0BIxUjESEnFhcHJicEByYnNjc2NxcGBzcmJwEWFwcmJyUyNzY3FhcGBwYrASInJj0BMxU2NxcGBxUUFxYzFxYXByYnAp1CFxdAiFcta6EKCSKhGwgJAhMmBhMUM/zxSSo9MEQBHRZAEzXX1z4gG28EEEokEtc8AVFLYSw4DRP+vh4KChcaRTU9P0bqKhgBGysOQBAnASIcCAkCGCIGFBQ1sUQXF0CXTCxnqAoKI41UK0AiWQH4EhE08XUjJi0sI0kUBQYQEDsOCEoaGf3WP2oQdT+uVkkITlT6RES0Q0P+2S4MChMhAwMBEEWSAaXWWk4dFhsaDScTBRs+WxRYQBIyFv1vXkAOSFd6EBA8EQZLGRoSEjT2ciYoLjAkUBQFBmBYUBlIYgAAAAAEACf/swO+A0EAKQAtADEASgAAAQYHFhUQBwYHBicmJxY3Njc2NTQnBgcmJzY3JicGByYnNjcmJzcWFzY3ATUjFTcVMzUTJicEByc2NzUjETM1MxUzESMVNyYnNxYXAWkpRT8zFCQqSAISSSQVDCMBSlsWF3pRDBo0PxAdPkYtRi5EKzgdATWd35o9CBb+5uUOTMbe3kLe3p8mGjxYJQMWSE+C1P72RRkGCAQgIAUFAw4u9R0Pb0gjEE+ZVT02MBUVLEpLPiQ6QkM4/hr19fX19f13GzsiGEQGFd8BasTE/pbYEVU0E6ZwAAAAAAIAOP/dA7IDAQATABkAACUVITUhESE1IREhNSEVIREhFSERExYXByYnA7L8hgGU/scBOf6eAxf+kQFJ/rePhDgyP3seQUEBR0ABGkJC/uZA/rkBEXg+LExxAAAABQAu/7QDzQNFABUAHAAjACoAOQAANzY3FwUnNjcRIzUzNSM1IRUjFTMVIwUGBSYnJDcDBgcmJzY3FwYHJic2NwMGBxYXBgcmJwYHJic2N/F5Egj+uA4uVnh4gAFAgWtrAqmD/p4PGQFYepNapRYWn1eTcNoWFddnNQwHcbEdE5x2aagWGNtYlyYFPWRACxoBGj7hPz/hPqnnXB0dTNYBBnNUHBFFa6SkXx4TVZUBkhoLolYXIFmgnmIcEnnHAAAAAgAv/7UDzgNDABMAOwAAJQUnNxEjNTM1IzUhFSMVMxUjETclFhcGByYnESMRBgcmJzY3IzUzNSMGByYnNjcXBgczNTMVMxUjFSEVAYL+uw6EeXmBAUqKd3eHAV9jkxgYhGFAa6AQHaxr3v+IHCYXIEodPgoRd0DR0QEDhGNAJQEaPuE/P+E+/vkolNBkEyBsxf6WAWfPahgbZNs9t1k+Ew5t1gtEQb29Pbc9AAQAK/+wA8ADFgATAB0AIwBGAAABITUzNSM1MzUjNSEVIxUzFSMVMwEXBgcnNjchNSEnJic3FhcnFgUGByYnBgUmJyQ3FzUzNSM1MzUjNSEVIxUzFSMVMxUhFwHO/nSuj4+pAYCYhYWfASwwXpE6Wlv9/gI70CpGLk0mOaABCRgU+LCV/v8SGQE9gy2jk5OxAZWjkpKv/nMHAc42VTRTNjZTNFX+yRptlh1cZTsBPDceNzfOeD0XI0GIe1UeF1+LFDNZNFA2NlA0WTYDAAUAJf+vA3IC/AADAAkADQARACoAAAE1IRUjNSMVFAcTFTM1KQEVIRMUBwYnJicWNzY9ASERIxEhBgcmJzYZASEDMP7pQvgEBPgBWf7pARdCLCOWAxRiPhr+6UL+/htjEx95AtQBJ6+vr0I6MwGWqamp/f8+EA0CHSMEAwEZ1f7VASvLbhsRiAExAWgABQBc/8UDmwNIAAMABwATAC0AMwAAASMVMxE1IxUTBgczESEVIxEzNjcFAgcGBwYnJicWMzI3NhMhBgcmJzY3FwYHIQMmJzcWFwF029vbpCAVqf7oPW8dDgKlFTEZMylqBBJBUh4MLBL++i0xDyllNEAXFQEv1TBrM3AwAmja/sz4+ALeYTP9elAC1lFRw/2nOyEFBAYmGwYPLwIkbEYMGYTpDlk7/hteih6JWgAAAAAEAKP/uQNAAwQAAwAHAAsAEwAAJTUhFREVITUlFSE1NxEjNSEVIxEC+/3rAhX96wIVRUX960M/rq4Bmq2t6qurQfy1RUUDSwAFACL/sAO/Ax4AAwAWABoAHgBYAAABIxEzBxUjEQYHJic2EyM1IRUjBgczESUzNSMDFSE1EwYHFhcGByYnIxU3BhcGByYnNj0BIwYHJic2GQEhFSEVFAczNSM1MzUzFTM1MxUzFSMVMxUjFhc2NwEqeXl5OBkeDxFhMoMBU5MWKbEBLHl5ngFmVjxAO1IRFqY7VI8BBNASCxAySRxTEiF4Ad7+XQpvXl45eTpTU3fPEB9EJQGj/tA8UQFzLycsF4IBDD09fnf+WOl4AU1sbP3NNChLHg4jSOTeKRkdQA0eFBUtxLlyERCkAWEBO91ebVZ4OWJiYmI5eDg5MzMlAAAABAAh/7MDpQNCAAUAGgAeAEkAABMmJzcWHwEGBxYXByYnESMRBgcmJzY3IzUhNxchNSEBFAcGIyYnFjM2NREjBgcWFwcmJwYHJic2NyMRIxEzNj0BIzUhFSMVFAcz1Rw4MzUiZiVIPT4rGEQ/PTsJF6Nd7QENDaQBP/7BAbMjHXMDETY/E7QDBnUvLCRjK2cYGIQapj/rAckBv7sB7gKiP0IfN0VFa2dCTDYkWP5OAZpGLSQbc8w9A0uS/SIyDQobHgEBEQFuGhppXyVMZ3NPHA1ipf5BAfsQHj3+/j4dEAAGACr/swO5A0QAFwAbACIAKAA5AFEAABMGByYnNjcjNTM1MxUzFSMVFhcHJicVIwchFSEXBgcmJzY3JRYXByYnJSEVIRUUBwYjJicWNzY9ASEBFhcGByYnFSM1BgcmJzY3IzUzNTMVMxX4S1oSF21LlKo+jIxNTiQrTD5AAof9eYZLgRcefEcByYRMNkGM/a8DYf5zKB+BBRJkJBT+bwK0VGweDFpQP1NjFBZ0U5qzP7ECZXg/HRFDhThoaDgLMT4uKTq6JDjNalAVFERhAVpRI0pkgjq8Mw0KFyQDAgEQuwHrgEEYFkB1xcp8PhwRPYU4aGg4AAAAAAgAH/+0A78DQwAfACYALAAwADQAOAA8AFMAACUmJxEjEQYHJic2NyM1MzUGByYnNjcXBgcVMxUjFRYfAQYHJic2NxcWFwcmLwEhNSERFSE1FSEVIQUhNSEFFSE1MxEzNjcjNTM2NxcHIRUhBgczEQFVGj09PUAJHFo5fo1CNQUOxFIsLE+BgVEv312BEBmHRtB5RyxIdtgBOf7HATn+xwE5/scBOf7HAc79oVaVBwnY4woDRxIBA/7vCgng+TNZ/i8BwLZZGCh6yD+pDwgaGiYpNhMVtz8YV0jpUEEYFkFHAkVBLkRIaUcBRUREbj9tQrQ7OwG8Gy04OSMFVzgtG/5EAAAABgAx/7UDpwNFABEAFQAZACUAMwBFAAATBgcmJzY3FwYHIRUjFhcHJicTFSE1ARUhNQUhFSM1IRUjESEVIRMWFyEVIzUhFSM1ISYnJRUjFhcHJicjBgcmJzY3FwYHuiYrJRNSJ0EODQESnR8NOQsoFgHr/hUBuP5IAi1C/hVDAjz+B90VEgFvQ/1iQAFvCxUB67gnETcTM00hGRMjRRtADA0CvUsvFglXjAwpIDM0JxMnR/22Z2cBDltb2fEgIgIAwwGGHTCibW2iHiODMzMlGTI/OxsQD0t0CysfAAcAJf+1A6UDRwARABUAGQAdADYAOgBeAAATBgcmJzY3FwYHIRUjFhcHJicBNSMVIzUjFSM1IxUFFAcGIyYnFjcyPQEjFSM1IxUjNSMVIxEhJyEVIRMVIxYXByYnIwYHFhchFSECByYnNhE1MxUhJic3JiM2NxcGB70pOBkeYjM+CxMBBJ8eCjsNIwJDjjmMOYkCVB8YZQMQTRQPjjmMOYk8ApBZ/cICPoDCIhQ7FDFcGxohGQEi/YIIfBYeej8BEBAZDigBYSs/ChYCvUY8FQ9cjBAdJzY0IRUpQf3QU1NTU1NTmCsMCRAiAgIOZY2NjY2hAVvgZwFmNiopGC0+JRsnLdH+9pkaEJQBI5QBHCIGFk52Dx4nAAAFACT/tQOqA0QAGwAgACQALAA8AAABFBcEByYnNjc2NwYHJic2NzY3FwYHNzY3FwYPATYlFwUBFSE1JSERIzUhFSMTFTMVITUzNSM1MzUzFTMVAY0E/swbCwwdMSZJlxYLDBYiUTdCS1aNKRY9bXp+LgE4Bf6gAdgBMv6NAbZD/s5B+tX+GM/p6UTlAT0eHDgPJRwHOiRlEQonHAU2dZ0crHwMQSolsITjCD8+TQED1tY9/oomKgLHo0BAo0CIiEAAAAAAAgA7/7YDrgNEABIAJgAAJRQHBiMmJxY3MjURIREjESE1ITcVIxUjNSEVIzUjNTM1MxUhNTMVA0ssJJoFEXwoF/6uRf72AuZj7UX+70Ts7EQBEUWWPg4MISUFBBQBDv4RAe9A60B1dXV1QHR0dHQAAAMAOf+1A7sDRAATAB8AQwAAASM1MzUzFSE1MxUzFSMVIzUhFSMXBgcRIxEGByYnNjcBMjc2NxYXBgcGKwEiJyY9AQYHJic2NxEzFTY3FwYHFRQXFjMBMvLyQwECQ+7uQ/7+Q0UoL0Q0OBodoVwCCSMLCgUYJwgWGEK+SBoaPUEKEEBYQ6ZhMXPFCwwmAqI/Y2NjYz9eXlgsTUD+JAGIOi0aFHK8/dIdG2QTCnIlKBcYQ6QdGxsXGysBFvVXTjVUXsQeCQoAAAAAAgA7/7QDrgNDABMAOwAAASM1MzUzFSE1MxUzFSMVIzUhFSMTFSEVIRUjNSE1ITUhNSEmJzcWFwchNjchNSEmJzcWFyEVIxcGByEVASXj40EBFUHs7EH+60HvAVn+p0T+qgFW/msBCRMpOTEPLQEFLxf95wFPEhc/JRABRL07Kh4BFAKqPF1dXV08Tk5O/rd4PaqqPXg+QEwQUD0PWkI8KycTPic8ElkxPgAAAAUAQf+6A68DQgADAC4ANAA8AFAAACUhNSE3BwYHBgcGJyYnFjMyNzY3IREzNjcXBgchFAcGBwYHBicmJxYzMjc2NyEVJSYnNxYXASEVIzUhFSMBFSMVIzUhFSM1IzUzNTMVITUzFQLb/WYCmroCDyAVLC9ZAhI6Sh0JFg79etQeED0KHgE3AQkWEyApNAIMJS8VBgwH/ioBFEVrH3BA/hwDO0D9Qz4DVfNB/u9C5+dCARFBMDaMHN8iFQMDBh0bBgkWqgEqLSITECwQCYwXEAMCBBkYBAcOVLwoMDAjLS0BK695eQE2OT8/Pz85TU1NTQAAAAAGACr/tQOtA0MACQAPACkALwBEAFgAABMzESMRBgcnNjcDFhcHJicFBgUmJzY3Jic3Fhc2NyEGByYnNjcXBgczNwEWFwcmJyUzFSMVFAcGIyYnFjcyPQEhNSE1MxMVIxUjNSEVIzUjNTM1MxUhNTMV6D4+KnQgOYV0RBw3GEUDMX3+cgwTfWYhKio2IHQ9/v5KShIYqVE/GCDuC/6xUiQzIVIBXIODIh5uBw9LJxL+awGVQIb1Qv74QfDwQQEIQgJ3/T4BMSJWOSRhAQxgWBhRaQXJQh0UEiMmHx0mKDFANB4VE0NrFB4dA/6FQkElQkRsOMozDgsfHgMDEMk4ZQGRO0JCQUE7SUlJSQAABQAg/7IDtQM7AAYADQATAC8ANgAAAQYHJic2NxMGByYnNjclJic3FhcTJicRIxEGByYnNjchNSE3FwYHFhc2NxcGBxYXJQYFJickNwNhguETG+Fwboj5Dx/0e/24IEQwRCNKIldBO0gPGL1q/vgBKQ0lL1sZETEfLTQqNh0CCZn+qxUWAUqOAxmXYBwWWIn+36xqGhtbomk9QiM/Pf31L2P+bgGCRDojFY3WPQMZdnoZEDUtJDkmNyId6WkjFVzXAAAAAAQAKf+1A8MDEgAHACAAKwBAAAABIxEhESMRIQMmJwYHJic2NyYnNxYXNjchNSE3FwYHFhcBEAUmJzY3Nj0BMxMyNzY3FhcGBwYrASInJj0BMxUUMwIPPwGuQf7StxQ0TGoZGG1SUFozSEw1F/7nASkMKxxMSRgBLf7RDxqoQi8/oRoICAMWIQYQEzxYMRMVPiQBAgIQ/fAB1f1rPmWjYiASYL2LeSFde5iiPwMM+cCASQFN/pudHhJWimKRxf1+Hx5uEQp6IicQEi389iIAAAAFADr/tQOzA0QAAwALAA8AEwAeAAAlFSE1JSERIzUhFSMTIRUhJSE1ITcVITUhJic3FhcHAQQB4f3eAmZE/h9BCQJS/a4CUv2uAlKV/IcBxiA/PkgeLLKYmDr+zCgrAdE3lDiQOjo9SBRKPxAAAAAACgAn/7UDvANEAAoADgA7AD8ARwBLAE8AWQBeAHoAABMGBzMVFjMyNzY3ByMVMycGByYnNjcXNSM1MzUzFTM1MxUzFSMVIzUjFSMXBgchFAcGBwYHBicmJyMVIxMVITUlIRUjNSEVIxMhFSElITUhJRYXIRUhNSEmJxMWFzY3MwYHFhcGByYnBgcmJzY3JicGByYnNjcXBgchFawJEMsNEA4IDwh8gYGzGhASFlMiFnl5OXY5dnY5diULAwoBHwELFhEcGSwCB5syhAHw/dECcEH+ED8HAmD9oAJg/aACYP7UFhIBfPyrAZQHF8MhOjccPB9FTWgXD2lTRGYIGmNBNCApGyANZS02Dw8BGgJ6DxSGAQkTjko/ShoLFg06VwMhLi0tLCwuJSUkAgoUEAi9GRMBAgIVFBv+kkZGKrYcHQEPKVYppB0qLy8SJgEPRjcyS1xFOBoWHR9CMiMQHx8sNT4zFhoIUYkMKx0yAAQAMP+0A7oDPAAFABMAFwAzAAATJic3FhcTFhcGByYnNjURIzUzESUhFSEDFTMRIzUhFSMRMzUjNTM1BgcmJyQ3FwYHFSEV9yxiK2MtQwgSvxESFTSOzQI9/qoBVorORP6qQsz+/mOKBBABRaMuToUBCgJsPFcoUjr+FhgfkhciEyg3AWVA/liGzgG3rP6TJSkBcaw/uxANFSEiNjUZGMY/AAAABQAx/7MDugNDAAUACwAZAB0ASQAAASYnNxYXBSYnNxYXExYXBgcmJzY1ESM1MxETITUhATI3NjcWFwYHBisBIicmNREjBgcGByYnNjc2NyMRITY3FwYHMxEjERQXFjMCBxhBN0Qb/sozZCxtLEEKDdAQDRk4ldi5AV7+ogGcEwYGARkjBRERLmk1EhFeDS04gA0bdDEoCoEBMDcgRDIiaX0FBhQCfU9dF1pPM0daKF86/jIhGZcVIhkmMwFVQf5rAQu//cIVFlARCV8gIBMSNgEmoFRoNR4VLFxKjAE3aV8Wcz/+yf7aEwUFAAAIADL/tAPHA0MABQALABsAIQAnAC0AOwBMAAABBgcnNjcFBgcnNjcBJicGByYnNjc2NzMGBxYXAzY3FwYHJTY3FwYHAyYnNxYXExYXBgcmJzY1ESM1MxEBBgcWFwYHJicGByYnNjc2NwOLTyYyOiz+sSI8Nz0fAcddtTy6EBegNiwHQgYVxWTSQzNDSjv+Tj8cPB9AjTNbLGYqFAkNlQ0NFy6c2wGYAwk98RgQzVA78QwcvD8xCQLreCwWS1wWeEAYPm/+eFJohjYfFipiTsOOUGxT/vVSahh2RBVCeAuCSQHtRE0jVDf97iEWcRIaFyA9AXRA/kkBVFJC/CcZIS3DskAfGixoUtQAAAAABQAx/7IDrgNKAAkADwAdAEMAVwAAASE1MyYnNxYXMwUmJzcWFxMWFwYHJic2NREjNTcRARYXMxUhBgchBwYHBgcGJyYnFjMyNzY3IwYHJic2NzY3IzUzJiclFSM1IRUjNTMmJzcWFwczNjcXBwOc/dr9ChA/Ewvm/VsrbCtpMFcJC8MQERMxmNgBjxUL5f65BQcBIQMQIRQoMkICEC48GQkUDucsnQwcay4lC538ChABVUH+PECYCxg8HwkquSQPRDUCrTgwLQg1MIc6YChWPf4OIBeLFCQTHzkBdj8B/kQBgDcvOTcrHMQiFAMCBB8aBQkUjaBBFhoqVkaGOS4tZJxlZZw8OQtKLApLOQ13AAAJADH/tQO7AyMABQAJAA0AKwAvADMANwA7AEcAABMmJzcWFxMhNSE1ITUhEyEVIRUjNSE1BgcmJzY1ESM1MxE3FhchNSMRIREjEyMVMxcVMzUFMzUjBzM1IyUVIxUzFSE1MzUjNfcyYitoLqUBdv6KAXb+itsBD/7xP/73nw4RFzmPzlQDCAEH2AHw2RFqajhq/vRqap1mZgINzqj93qHEAmFEVSlXPP5FPyw9/uc0e3sVcRQdEig7AXhA/kE5ChZDAQT+/AI+QTBkZGRkZGSmNUHExEE1AAAJADD/tAO9A0UABQATABcAGwAjACcAQABGAEwAABMmJzcWFxMWFwYHJic2NREjNTMRNxUhNRU1IRUDIREjNSEVIxMzNSMFFSE1MzUjNTMmJzcWFwczNjcXBgczFSMVJRYXByYnBTY3FwYH6ShhLV0vQgkNsw4NFC6NzNMBTv6yPAHIPv6yPKVubgGF/W7RrKUZKjE1FxygJhs5GCituP6cPhcvGjkBtysnNC8sAl8/YSZWQv4IHxmAESEXGjQBej7+SrdWVulgYAEf/nc3OwIJz885Oc85NDQXPTIQRDwWKkA5z7hHMx06RGw1TxpOMwAIAD7/swOqAx4ADAAUABoAHwAkACgALAA4AAAlFAcGByYnNjc2PQEzFxEhESMRIRElFhcHJicTNyMGByEzNjcjNwczNyEjBzM3FSMHITcjNTM3IQcCFEVi/g8Z8ls8RNb+H0ICaP8A5pAlld7QCs8GCv7w0AkIzxkQzwwBCMoMzb1/EP2TGYmUGQJUDuBfP1o1HBksTDJPWdcBBf72AUD+xRRCSThRQQHGWCUzJDSEVFRUBDiKijiGhgAAAAQAK//OA78DQQAUABoAIAA6AAABITUhNTMVMxUjERQHBiMmJxY3NjUBFhcHJi8BJic3FhcDFhcWFxYzMjcGBwYjIicmIyIHJzY3ESM1MwLQ/n0Bg0SNjS8klgUTdywa/uVmKDcqYZczYjNnMRwKFxsRTra7rxMBsae9VVoEKGMtWz2NzgJQP7KyP/5pPhAMHyQDAgEXAUF7SSFSd4BRWSFaS/38BhEVCzASKh0KNz2APWMWAQs+AAAEACr/sQPBAwoAAwAeACQAPgAAASE1IQEGFSYnNjc2NyM1IRUhBgclJic3FhcHJicEBwMmJzcWFwMWFxYXFjMyNwYHBiMiJyYjIgcnNjcRIzUzA2/+DQHz/gkCAxMTI0IxzgJ8/qJEUwFYJEY2eD47DRv+XB1+OncsiigtDBgiEE63trYTAYbTuVtaCCdfLlQ7i8wCxD79fQQCFi4ENmeBPz+edhlAcBm4dx8dLyUNAeMxUypcIv3bBhAYCjESLBwKNzp+PF4ZAUQ+AAAHACz/wAPEAyIAAwAHAAsADwA1ADsAVAAAARUzNRU1IxUjNSMVNRUzNScWFzY3ITUhNxcGBxYXMxEUBwYjJicWMzY9ASMVIzUjFSMRISYnByYnNxYXAxYXFhcWMzI3BgcGIyIvASIHJzY3ESM1MwKZuLg8sbFsT0RSRP5SAe4NKVJ+NhiCHx1rBA4ZTxK4PLE/ASVvXdc3ci53NSILFx0RULa6thEBiNe6WmEoYCpZOY7OAhVdXfFhYWFh8V1dtR4dJDU2BB9QQRkP/kIwDQsYIAEBEGSmpqoCBDciWEhjJWFE/fYFERULMRIoGQo3On02YRcBIz4AAAQAUv+2A5oDQwADAAcAIgA/AAATFTM1ETUjFRcWFwcmJwQHJic2NREzJic3FhcHMxEhFTcmJwEGBxYVFgcGBwYnJicWNzY3NjUmJzY3IxEjESE3tPT0v2gpORAl/vscCxghtRYrNDMaHp3+zcUdHQJWMVSIAjYbJS45AhQ+Jx4PIQGKNDq1QAEVCgKMaGj+6XR0ZpJpHi1CbxcaGxg1AmUsOBk6NA/+dfFQMisB8nKrj2xjIhEDBQUhHQYDAgkUQV6Sc4388wNLAwAAAAoAMf+4A8ADGwADAAcACwATABcAHAAgAC8APwBfAAABIRUhFSEVIRchESEFIxUUOwEyNxE1IRURFTY9ATczNSMTIicmPQEjFRQHJicVITUDMxEjNSEVIxEzNSM1IRUjARUhNTM1IzUzNSMGByYnNjcXBgczNTMVMxUjFTMVIxUDUP7yAQ7+8gEOPf56AYb9/0YPKA4B/uxDJz09bx4KCztRCBIBFDpwNv7sNW1/AaB/Am7+I86dnYIfHRYZRic3EA9oPLa2pqYC5VsyXTYBVvq+DwP+4m1tAejvOmlMOYX+TAoLIr9NfEULDFFSAS/9bDxKAqKFOjr9KDg4eTZnOiARDU2GCzMiXl43ZzZ5AAAABQA4/9UDsQM9AAMABwALAA8ANwAAATUjFTUzNSMhFTM1FSMVMxMVITUhNSE1ITUhESE1ITUhNQYHJickNxcGBxUhFSEVIREhFSEVIRUB0O3t7QEv+Pj4p/yHAZj+swFN/tIBLv5uAZKokQENAcbXJXbDAZr+ZgE7/sUBYP6gARlSUoBRUVF/Uv7zNzdcNkoBM0E3TQsDGB0OKDQWD1E3Qf7NSjZcAAAABwAr/7cDugNEAAsAIwAnACsAMwA3AEsAABMGByYnNjcXBgczFQMzFSMVNxYXBgcmJzY9ASM1MzUjNSEVIwUVITURNSEVAyERIzUhFSMTMzUjBRUhNTM1IzUzNTMVMzUzFTMVIxWlKywLGFwwORIXyoOKinUECL0QCRcujo5jARV0AQ4BGv7mPQGWP/7mPX6RkQFd/ex7Y2M8kT54eAKKRy4fHFyUEDcwP/7KPN09IxZrER0bGzTOPI49PbRsbP7rcXEBTv5UJioCQomJPT2JPIaGhoY8iQAABABd/7MDiQM5AAUACQAtADwAABMmJzcWFwczESMlFAcGIyYnFjMyPQEjESMRIxEjETM1IzUhJic3FhcHIRUjFTMTFAcGJyYnFjc2NREhNSH+IlszVynXQEACeBkTTQQOISQMiTyKOcPyAQgUKjYxETIBE/XDtCcjggYOZSQX/h4CIgKAQVoeUkQy/ULUKAoJER8BDMb+ogFe/vUBQ1w3ODwYQTQXN1z+jTsPDAIiHAMCARUCuj4AAAkAOP+3A6ADJwATABcAGwAfACMAJwArAC8AUQAAEyM1ITUhNSEVIRUhFSM1IRUjNSEFIzUzBzMVIycjNTMHMxUjEzM1IzcjFTMVIxUzBSEVIxEGByYnNjcXBgczJic3FhcHIRUhFSEVIRUhFSEVIY08AX7+tQLc/rABhD7+ukH+vgKY3d3d3d2z1tbW1tZM8PDw8PDw8AGl/WtBMTIWGZBKPRUZ4wsYOyIKBQE7/r4BCP74AQ3+8wFkAfnAPTExPcGRz89fKmEqYSphKf5DP9g7Lz6jIgExNicaFGmTFCUmHykTLisCMjsvPjA/AAAAAAoALv+9A8IDSAALAB8AJQArADAANgA8AEEAUgBpAAABETMRNxcHFSM1BycHBgc3Jic3FhcHJicGByYnNjc2NwEmJzcWFwcmJzcWFwU2NyMVNTM2PQEjISMVFAczFSMGBzMHBgcmJzY3IxEzNjcXBgczEQEyNzY3FhcGBwYjISInJj0BMxUUFxYzAxE9VwphPeoKJxkoYRIOJjMVKQYNlREKBgwRKA8BADBTKFgsSDBcJ14v/icKA36AAYEBOoABgYMDCY+ZMJwSGo0ypKAYCUIeBtQBKTsREQYSKAkcHln+tmcjJDwVFUYBaQHM/j8SOBPu4i85BVtKECEYEUlBFhQdHwojDQEhT1MBIjU4Jzgw9jc4KTczPTc+dacVJTs7JRUyNz4496IZFI/dAYw/JwtNDv50/rEZGVoNCWwhIhQUPvf3HAgJAAAHAC3/sgO7A0UAAwAbACAAJQAqAC8AbgAAASE1IQMmJwYHJic2NzY3IzUhFSMGBzcmJzcWFxM2NyMVNTM2NyMhIwYHMxUjBgczExYXBgcGKwEiJyY9AQYHJic2NyMRMzY3FwYHMxEjBgczERQXFjsBMjc2NwcmJwYHJic2NzY3FwYHNyYnNxYXAYD+0QEvDgYQ/xUMCREaMSCCAWyqJj++EyU0Rh7GCgV/gwMCiAFGgAEEhYoFCplDFh4FEREriTgTE0ecFBq1PaKSGA9KGRTt5AEHJAcHG34UBwYCDQoBgxIMBAwQJw8yGShUEw4mLw0CqDv9eRgvMA4oFAU4ZYQ8PJB/IDROEYR3ARA7PnmuKFEnUjU+O/7HDAhBFhYQDzDGyGEeEGr+AZcyNAo2Jv5pBx7+8xIFBQ0OMQQnARkJKAgCHkVUEFNJDTEbDFk/AAAGACz/tgPAA0IACwAQABUAUQBXAFsAAAEmJyMGBzM2NxcGByczNjcjISMGByEHFhcGByYnBwYHBgciJyYnFjMyNzY3IRUhBwYHBgcGJyYnFjMyNzY3IREGByYnNjchNTM1ITUzFSEVMxUBJic3Fh8BITUhAvCES1hJk7QcGzkdEv3HIwfxAhrsBRoBC5By3xgMSkABChQRJDcnAgwmMRMHDAf+NwKDAQ0fFisrYAQOOkwcCRQL/X8qUg8X3Wn+wnYBLj0BJ3f+XjlxImZEn/1nApkBsS5MRzMlLxMqF64pNjMsNFUbGBsLEw6GFBADAh8RBAcOT6wbyB8VAQMFIBUFCBSTAQ0OFRwVMEY0kVJSkTT+vCw/JDE0+TcAAAUANP+5A7sDRwAZAB0ASABOAHIAABMGByYnNjcXBgczNxcGBSYnNjcmJzcWFzY3ASE1ITcHBgcGBwYnJicWMzI3NjchETM2NxcGByEUBwYHBgcGJyYnFjMyNzY3IRU3Jic3FhcBMjc2NxYXBgcGKwEiJyY9ASEVFAcGIyYnFjcyPQEjFRQXFjPyOl8MGZE4PAkWpQwjUf67CxF9Wx86KDsjQCEBM/1nApm7AQ8hFC4zWwIPO0weCBcM/YDFGhs9DSQBRAELFRIjKzUCDCUxFQUMCP4z/T1sIXc0ASgdCQkDEyMGExQ1xUYXGQE8HRZnAg1HFw/DCwwmAthANRkRSHILESIDDP9MIxEYOhkmHyMaNUf9UjWFGtkgFAICBRoVBQgYpQEdJS8SEy8QCYYUEAICBBcSAwYNVbATMDskPicBEg8PNgwIRBYXDxAxyXMnCQcQGwMCDUKYEwYGAAIAKP/EA7wDQwAFAD4AAAEmJzcWFxMyNzY3FhcGBwYrASInJj0BBgcmJzY3ESMGBwYHJic2NzY3ITUhNjcXBgchFSERNjcXBgcVFBcWMwMMQnMqdkESHgoJBBojBhYWPMVHGRpUWRoUd2RzG0ZNlBAijUlCGP7iASUJBUUECwII/qeJTjxjsAsLJgJzRFAkTz/9cxYVSRQHWB8gFhc/DjspJA80TAF524aTXBsdTYd6yj9ekgJ/bz/+vniRGbWPPx0JCQAAACUBwgABAAAAAAAAAEAAAAABAAAAAAABABkAbgABAAAAAAACAAcAQAABAAAAAAADACcARwABAAAAAAAEABkAbgABAAAAAAAFADYAhwABAAAAAAAGABYAUgABAAAAAAAHAGAAvQABAAAAAAAIABoCigABAAAAAAAJAMMBHQABAAAAAAAKAIAB4AABAAAAAAALABoCYAABAAAAAAANAjkCegABAAAAAAAOAC8DTwABAAAAAAAQABIAbgABAAAAAAARAAYAYgADAAEECQAAAIIEswADAAEECQABADIFNQADAAEECQACAA4OTQADAAEECQADAE4FZwADAAEECQAEADIFNQADAAEECQAFAGwFtQADAAEECQAGACwFfQADAAEECQAHAMAGIQADAAEECQAIADQJ+wADAAEECQAJAboG4QADAAEECQAKAQoImwADAAEECQALADQJpQADAAEECQANBHQJ2QADAAEECQAOAF4LhQADAAEECQAQACQFNQADAAEECQARAAwFnQADAAEIBAABAAgOWwADAAEIBAACAA4OTQADAAEIBAAEABwOWwADAAEIBAAQAA4OWwADAAEIBAARAAwFnUNvcHlyaWdodCA/MjAxNCBBZG9iZSBTeXN0ZW1zIEluY29ycG9yYXRlZC4gQWxsIFJpZ2h0cyBSZXNlcnZlZC5SZWd1bGFyMS4wMDA7QURCRTtTb3VyY2VIYW5TYW5zQ04tTm9ybWFsO0FET0JFU291cmNlIEhhbiBTYW5zIENOIE5vcm1hbFZlcnNpb24gMS4wMDA7UFMgMTtob3Rjb252IDEuMC43ODttYWtlb3RmLmxpYjIuNS42MTkzMFNvdXJjZSBpcyBhIHRyYWRlbWFyayBvZiBBZG9iZSBTeXN0ZW1zIEluY29ycG9yYXRlZCBpbiB0aGUgVW5pdGVkIFN0YXRlcyBhbmQvb3Igb3RoZXIgY291bnRyaWVzLlJ5b2tvIE5JU0hJWlVLQSAoa2FuYSAmIGlkZW9ncmFwaHMpOyBQYXVsIEQuIEh1bnQgKExhdGluLCBHcmVlayAmIEN5cmlsbGljKTsgV2VubG9uZyBaSEFORyAoYm9wb21vZm8pOyBTYW5kb2xsIENvbW11bmljYXRpb24sIFNvby15b3VuZyBKQU5HICYgSm9vLXllb24gS0FORyAoaGFuZ3VsIGVsZW1lbnRzLCBsZXR0ZXJzICYgc3lsbGFibGVzKURyLiBLZW4gTHVuZGUgKHByb2plY3QgYXJjaGl0ZWN0LCBnbHlwaCBzZXQgZGVmaW5pdGlvbiAmIG92ZXJhbGwgcHJvZHVjdGlvbik7IE1hc2F0YWthIEhBVFRPUkkgKHByb2R1Y3Rpb24gJiBpZGVvZ3JhcGggZWxlbWVudHMpaHR0cDovL3d3dy5hZG9iZS5jb20vdHlwZS9Db3B5cmlnaHQgPzIwMTQgQWRvYmUgU3lzdGVtcyBJbmNvcnBvcmF0ZWQgIExpY2Vuc2VkIHVuZGVyIHRoZSBBcGFjaGUgTGljZW5zZSwgVmVyc2lvbiAyLjAgKHRoZSAiTGljZW5zZSIpOyB5b3UgbWF5IG5vdCB1c2UgdGhpcyBmaWxlIGV4Y2VwdCBpbiBjb21wbGlhbmNlIHdpdGggdGhlIExpY2Vuc2UuIFlvdSBtYXkgb2J0YWluIGEgY29weSBvZiB0aGUgTGljZW5zZSBhdCBodHRwOi8vd3d3LmFwYWNoZS5vcmcvbGljZW5zZXMvTElDRU5TRS0yLjAuaHRtbCAgVW5sZXNzIHJlcXVpcmVkIGJ5IGFwcGxpY2FibGUgbGF3IG9yIGFncmVlZCB0byBpbiB3cml0aW5nLCBzb2Z0d2FyZSBkaXN0cmlidXRlZCB1bmRlciB0aGUgTGljZW5zZSBpcyBkaXN0cmlidXRlZCBvbiBhbiAiQVMgSVMiIEJBU0lTLCBXSVRIT1VUIFdBUlJBTlRJRVMgT1IgQ09ORElUSU9OUyBPRiBBTlkgS0lORCwgZWl0aGVyIGV4cHJlc3Mgb3IgaW1wbGllZC4gU2VlIHRoZSBMaWNlbnNlIGZvciB0aGUgc3BlY2lmaWMgbGFuZ3VhZ2UgZ292ZXJuaW5nIHBlcm1pc3Npb25zIGFuZCBsaW1pdGF0aW9ucyB1bmRlciB0aGUgTGljZW5zZS4gIABDAG8AcAB5AHIAaQBnAGgAdAAgAKkAIAAyADAAMQA0ACAAQQBkAG8AYgBlACAAUwB5AHMAdABlAG0AcwAgAEkAbgBjAG8AcgBwAG8AcgBhAHQAZQBkAC4AIABBAGwAbAAgAFIAaQBnAGgAdABzACAAUgBlAHMAZQByAHYAZQBkAC4AUwBvAHUAcgBjAGUAIABIAGEAbgAgAFMAYQBuAHMAIABDAE4AIABOAG8AcgBtAGEAbAAxAC4AMAAwADAAOwBBAEQAQgBFADsAUwBvAHUAcgBjAGUASABhAG4AUwBhAG4AcwBDAE4ALQBOAG8AcgBtAGEAbAA7AEEARABPAEIARQBWAGUAcgBzAGkAbwBuACAAMQAuADAAMAAwADsAUABTACAAMQA7AGgAbwB0AGMAbwBuAHYAIAAxAC4AMAAuADcAOAA7AG0AYQBrAGUAbwB0AGYALgBsAGkAYgAyAC4ANQAuADYAMQA5ADMAMABTAG8AdQByAGMAZQAgAGkAcwAgAGEAIAB0AHIAYQBkAGUAbQBhAHIAawAgAG8AZgAgAEEAZABvAGIAZQAgAFMAeQBzAHQAZQBtAHMAIABJAG4AYwBvAHIAcABvAHIAYQB0AGUAZAAgAGkAbgAgAHQAaABlACAAVQBuAGkAdABlAGQAIABTAHQAYQB0AGUAcwAgAGEAbgBkAC8AbwByACAAbwB0AGgAZQByACAAYwBvAHUAbgB0AHIAaQBlAHMALgBSAHkAbwBrAG8AIABOAEkAUwBIAEkAWgBVAEsAQQAgiX9YWm28W1AAIAAoAGsAYQBuAGEAIAAmACAAaQBkAGUAbwBnAHIAYQBwAGgAcwApADsAIABQAGEAdQBsACAARAAuACAASAB1AG4AdAAgACgATABhAHQAaQBuACwAIABHAHIAZQBlAGsAIAAmACAAQwB5AHIAaQBsAGwAaQBjACkAOwAgAFcAZQBuAGwAbwBuAGcAIABaAEgAQQBOAEcAIF8gZYefmQAgACgAYgBvAHAAbwBtAG8AZgBvACkAOwAgAFMAYQBuAGQAbwBsAGwAIABDAG8AbQBtAHUAbgBpAGMAYQB0AGkAbwBuACDAsLPMzuS7pLLIzwDHdMFYACwAIABTAG8AbwAtAHkAbwB1AG4AZwAgAEoAQQBOAEcAIMelwhjGAQAgACYAIABKAG8AbwAtAHkAZQBvAG4AIABLAEEATgBHACCsFcj8xfAAIAAoAGgAYQBuAGcAdQBsACAAZQBsAGUAbQBlAG4AdABzACwAIABsAGUAdAB0AGUAcgBzACAAJgAgAHMAeQBsAGwAYQBiAGwAZQBzACkARAByAC4AIABLAGUAbgAgAEwAdQBuAGQAZQAgACgAcAByAG8AagBlAGMAdAAgAGEAcgBjAGgAaQB0AGUAYwB0ACwAIABnAGwAeQBwAGgAIABzAGUAdAAgAGQAZQBmAGkAbgBpAHQAaQBvAG4AIAAmACAAbwB2AGUAcgBhAGwAbAAgAHAAcgBvAGQAdQBjAHQAaQBvAG4AKQA7ACAATQBhAHMAYQB0AGEAawBhACAASABBAFQAVABPAFIASQAgZw2Q6GtjjLQAIAAoAHAAcgBvAGQAdQBjAHQAaQBvAG4AIAAmACAAaQBkAGUAbwBnAHIAYQBwAGgAIABlAGwAZQBtAGUAbgB0AHMAKQBoAHQAdABwADoALwAvAHcAdwB3AC4AYQBkAG8AYgBlAC4AYwBvAG0ALwB0AHkAcABlAC8AQwBvAHAAeQByAGkAZwBoAHQAIACpACAAMgAwADEANAAgAEEAZABvAGIAZQAgAFMAeQBzAHQAZQBtAHMAIABJAG4AYwBvAHIAcABvAHIAYQB0AGUAZAANAAoATABpAGMAZQBuAHMAZQBkACAAdQBuAGQAZQByACAAdABoAGUAIABBAHAAYQBjAGgAZQAgAEwAaQBjAGUAbgBzAGUALAAgAFYAZQByAHMAaQBvAG4AIAAyAC4AMAAgACgAdABoAGUAIAAiAEwAaQBjAGUAbgBzAGUAIgApADsAIAB5AG8AdQAgAG0AYQB5ACAAbgBvAHQAIAB1AHMAZQAgAHQAaABpAHMAIABmAGkAbABlACAAZQB4AGMAZQBwAHQAIABpAG4AIABjAG8AbQBwAGwAaQBhAG4AYwBlACAAdwBpAHQAaAAgAHQAaABlACAATABpAGMAZQBuAHMAZQAuACAAWQBvAHUAIABtAGEAeQAgAG8AYgB0AGEAaQBuACAAYQAgAGMAbwBwAHkAIABvAGYAIAB0AGgAZQAgAEwAaQBjAGUAbgBzAGUAIABhAHQAIABoAHQAdABwADoALwAvAHcAdwB3AC4AYQBwAGEAYwBoAGUALgBvAHIAZwAvAGwAaQBjAGUAbgBzAGUAcwAvAEwASQBDAEUATgBTAEUALQAyAC4AMAAuAGgAdABtAGwADQAKAFUAbgBsAGUAcwBzACAAcgBlAHEAdQBpAHIAZQBkACAAYgB5ACAAYQBwAHAAbABpAGMAYQBiAGwAZQAgAGwAYQB3ACAAbwByACAAYQBnAHIAZQBlAGQAIAB0AG8AIABpAG4AIAB3AHIAaQB0AGkAbgBnACwAIABzAG8AZgB0AHcAYQByAGUAIABkAGkAcwB0AHIAaQBiAHUAdABlAGQAIAB1AG4AZABlAHIAIAB0AGgAZQAgAEwAaQBjAGUAbgBzAGUAIABpAHMAIABkAGkAcwB0AHIAaQBiAHUAdABlAGQAIABvAG4AIABhAG4AIAAiAEEAUwAgAEkAUwAiACAAQgBBAFMASQBTACwAIABXAEkAVABIAE8AVQBUACAAVwBBAFIAUgBBAE4AVABJAEUAUwAgAE8AUgAgAEMATwBOAEQASQBUAEkATwBOAFMAIABPAEYAIABBAE4AWQAgAEsASQBOAEQALAAgAGUAaQB0AGgAZQByACAAZQB4AHAAcgBlAHMAcwAgAG8AcgAgAGkAbQBwAGwAaQBlAGQALgAgAFMAZQBlACAAdABoAGUAIABMAGkAYwBlAG4AcwBlACAAZgBvAHIAIAB0AGgAZQAgAHMAcABlAGMAaQBmAGkAYwAgAGwAYQBuAGcAdQBhAGcAZQAgAGcAbwB2AGUAcgBuAGkAbgBnACAAcABlAHIAbQBpAHMAcwBpAG8AbgBzACAAYQBuAGQAIABsAGkAbQBpAHQAYQB0AGkAbwBuAHMAIAB1AG4AZABlAHIAIAB0AGgAZQAgAEwAaQBjAGUAbgBzAGUALgANAAoAUgBlAGcAdQBsAGEAcmAdbpCe0U9TACAAQwBOACAATgBvAHIAbQBhAGwAAAAAAwAAAAAAAP+DADIAAAAAAAAAAAAAAAAAAAAAAAAAAAABAAAACABEAAQAFgAEaWNmYmljZnRpZGVvcm9tbgAGREZMVABiY3lybABoZ3JlawBoaGFuaQBia2FuYQBibGF0bgBoAAQAFgAEaWNmYmljZnRpZGVvcm9tbgAGREZMVAAyY3lybAA4Z3JlawA4aGFuaQAya2FuYQAybGF0bgA4ABgAAAAAAB4AAAAAACQAAAAAACoAAAAAAAIABAAwADQAOAA8AAMABAAkACgALAAwAAIABAAoACwAJAAwAAMABAAcACAAGAAkAAH/uAABA0AAAf+IAAEAAAABADAAAQO4AAEAeAABAAADcADbAdoDYgHqA2IB6wNpAewDYgHuAosB7wOBAfIDYQH0A2gB9QNaAfYD0gH5A2IB+gNhAfsDYQH8A2EB/QNhAf4DYQH/A2ECAANhAgEDYQICA2ECAwNhAgQDYQIFA2ECCgMBAg8DAQK1A1ECtgNYArcDWAK4A1ECuQNRAroDWAK7A1ECvANYAr0DWAK+A1gCvwNRAsADWALBA1gCwgNRAsMDUQLEA1gCxQNRAsYDWALHA1gCyANYBJwFZASdBWQHGALoBxkCjgcaA1wHGwNiB70DXAe/A1wHwAKeB8IDoQfDA6EHxANcB8oC+AfLA2IHzAL6B80DYgfPA2IH0ANiB9EDYgfUAvgH1QNiB9YC+gfXAo4H2AKOB9kC+QfaA2IH3ANiB90DYgfeA2IH3wMhB+ADggfhA4IH4gOCB+MDegfkAwgH5QKgB+YDCAfnAwIH6QOoB+oDoQfrA6gH7AOoB+0DqAfuA6EH7wOoB/ADqAfxAyYH8gNOB/MDXAf1A1wH9gNiB/gDBgf5AwYH+gKeB/sDAgf8AqEH/QMCB/4C+Af/A2IIAAL6CAEDYggDA2IIBAL4CAUDYggGAvoIBwNiCAkDYggLA2gIDAMCCA0C+AgOAwIIEAMGCBEDYggTAvwIFQNiCBYDdQgXA2IIGANiCBwC+QghAvgIIgKeCCMDYggkA2IIJQMCCCYDYggoAyYIKQMmCEkC+XQrA1p0LQNidDcDYnQ4A2J0OQNodDoDYnQ7A2J0PANcdD0DYnQ+A2J0PwNidEADYnRIA2J0SQNidEoDYnRLA2J0TANidE0DYnROA2J0TwNidFADYnRRA1x0UgNidFMDYnRUA2J0VQNidFYDYnRXA2J0WAMOdFkDYnRaA2J0WwNidFwDXHRdA2J0XgNidF8DYnRgA2J0YQNidGgDAnRpA3x0agMCdGsDfHRsAwJ0bQOIdG4Ci3RvA4J0cAN8dHEDAXRyA4J0cwN8dHQDCXR1Awl0dgMCdHcClXR4ApV0eQMIdHoDAnR7A0l0fAL8dH0DAnR+AwJ0fwMCdIACjHSBAwJ0+QNfdPoDYXT+A1t0/wNbdQYDWHUHAwF1CAL6dQkDAXUKAwF1CwL6dQwC+nUNAwF1DgL6dQ8DAXUQAwF1jANcd1sFZHdcB1h3ZP+Id2X/iHdn/4h3aP+I根据【本文末 - 引用1】的分析,得知页面的字体文件与原版的区别在于 修改了每个图元数据的unicode因为图元数据是和原版一致的,所以大概思路为根据加密后的图元数据 去 原版字体中查询,将查询到的unicode替换掉混淆的unicode即可3.解决思路梳理3.1 原版字体建立Map解决思路就是根据原版字体文件 建立 map,后进行k,v翻转// 将原生字体key => value 反向映射 var swappedDict = new Dictionary<string, string>(); foreach (var swappedTempDict in Context.OriginFontsDictionary) { swappedDict[swappedTempDict.Value] = swappedTempDict.Key; }3.2 修改版字体建立Map将页面上的base64编码的ttf文件读取并建立 Mapvar keyHex = "uni" + kvp.Key.ToString("X").ToUpper(); var fontGlyph = font.GetGlyph(kvp.Value); var sb = new StringBuilder(); foreach (var fontGlyphGlyphPoint in fontGlyph.GlyphPoints) { sb.Append( $"{fontGlyphGlyphPoint.X}{fontGlyphGlyphPoint.Y}{(fontGlyphGlyphPoint.onCurve ? "1" : "0")}"); } unicodeAndContourPair[keyHex] = CommonUtil.GetMd5(sb.ToString()); /** * 数据类型如下: * Key = uniXXXX * Value = 每个 pt 标签的x,y,on属性拼接进行求Md5 * */3.3 建立正确的映射关系根据 修改版字体建立的Map 进行遍历// 遍历 unicodeAndContourPair 获取所有的 values 也就是 contour 下 pt标签的x,y,on属性加密后的md5 // 还记得吗? unicodeAndContourPaire的 values 都可以在 原版Map 也就是 swappedDict 的 Keys中找到 // swappedDict 中 values 就是真正字体的 unicode 值! // 遍历加密的 pair var keysList = new Dictionary<string, string>(); foreach (var keyValue in unicodeAndContourPair) { keysList[keyValue.Key] = swappedDict[keyValue.Value].Replace("uni", "\\u"); keysList[keyValue.Key] = Regex.Unescape(keysList[keyValue.Key]); } // 此时得到的 keysList 中 keys 为 加密的每个字的unicode, values为真正的字3.4 题目处理var questionTitle = questionNodes[0].SelectSingleNode("div[@class='Zy_TItle clearfix']/div").InnerText.Trim(); foreach (var c in questionTitle.ToCharArray()) { var temp = Convert.ToString(Convert.ToUInt32(c), 16).Replace("0x", "").ToUpper(); // 拿到当前字符的 unicode 编码 if (keysList.ContainsKey($"uni{temp}")) questionTitle = questionTitle.Replace(c + "", keysList[$"uni{temp}"]); }此时题目还是不可以直接用,结合易姐博客的文章经过查阅资料,我发现这种和普通汉字字形相同,但是 unicode 内码不同的字叫做康熙部首,它位于 unicode 的 2F00—2FDF 区段,当然它们和普通的汉字一一对应,出现此误码的原因可能是一些字体厂家没有把这两种编码的字形做区分那么再次对题目进行清洗,将康熙部首替换为正常汉字即可# 康熙部首替换表 KX_RADICALS_TAB = str.maketrans( # 康熙部首 "⼀⼁⼂⼃⼄⼅⼆⼇⼈⼉⼊⼋⼌⼍⼎⼏⼐⼑⼒⼓⼔⼕⼖⼗⼘⼙⼚⼛⼜⼝⼞⼟⼠⼡⼢⼣⼤⼥⼦⼧⼨⼩⼪⼫⼬⼭⼮⼯⼰⼱⼲⼳⼴⼵⼶⼷⼸⼹⼺⼻⼼⼽⼾⼿⽀⽁⽂⽃⽄⽅⽆⽇⽈⽉⽊⽋⽌⽍⽎⽏⽐⽑⽒⽓⽔⽕⽖⽗⽘⽙⽚⽛⽜⽝⽞⽟⽠⽡⽢⽣⽤⽥⽦⽧⽨⽩⽪⽫⽬⽭⽮⽯⽰⽱⽲⽳⽴⽵⽶⽷⽸⽹⽺⽻⽼⽽⽾⽿⾀⾁⾂⾃⾄⾅⾆⾇⾈⾉⾊⾋⾌⾍⾎⾏⾐⾑⾒⾓⾔⾕⾖⾗⾘⾙⾚⾛⾜⾝⾞⾟⾠⾡⾢⾣⾤⾥⾦⾧⾨⾩⾪⾫⾬⾭⾮⾯⾰⾱⾲⾳⾴⾵⾶⾷⾸⾹⾺⾻⾼髙⾽⾾⾿⿀⿁⿂⿃⿄⿅⿆⿇⿈⿉⿊⿋⿌⿍⿎⿏⿐⿑⿒⿓⿔⿕⺠⻬⻩⻢⻜⻅⺟⻓", # 对应汉字 "一丨丶丿乙亅二亠人儿入八冂冖冫几凵刀力勹匕匚匸十卜卩厂厶又口囗土士夂夊夕大女子宀寸小尢尸屮山巛工己巾干幺广廴廾弋弓彐彡彳心戈戶手支攴文斗斤方无日曰月木欠止歹殳毋比毛氏气水火爪父爻爿片牙牛犬玄玉瓜瓦甘生用田疋疒癶白皮皿目矛矢石示禸禾穴立竹米糸缶网羊羽老而耒耳聿肉臣自至臼舌舛舟艮色艸虍虫血行衣襾見角言谷豆豕豸貝赤走足身車辛辰辵邑酉采里金長門阜隶隹雨青非面革韋韭音頁風飛食首香馬骨高高髟鬥鬯鬲鬼魚鳥鹵鹿麥麻黃黍黑黹黽鼎鼓鼠鼻齊齒龍龜龠民齐黄马飞见母长" )转为 c#:// 康熙部首 const string source = "⼀⼁⼂⼃⼄⼅⼆⼇⼈⼉⼊⼋⼌⼍⼎⼏⼐⼑⼒⼓⼔⼕⼖⼗⼘⼙⼚⼛⼜⼝⼞⼟⼠⼡⼢⼣⼤⼥⼦⼧⼨⼩⼪⼫⼬⼭⼮⼯⼰⼱⼲⼳⼴⼵⼶⼷⼸⼹⼺⼻⼼⼽⼾⼿⽀⽁⽂⽃⽄⽅⽆⽇⽈⽉⽊⽋⽌⽍⽎⽏⽐⽑⽒⽓⽔⽕⽖⽗⽘⽙⽚⽛⽜⽝⽞⽟⽠⽡⽢⽣⽤⽥⽦⽧⽨⽩⽪⽫⽬⽭⽮⽯⽰⽱⽲⽳⽴⽵⽶⽷⽸⽹⽺⽻⽼⽽⽾⽿⾀⾁⾂⾃⾄⾅⾆⾇⾈⾉⾊⾋⾌⾍⾎⾏⾐⾑⾒⾓⾔⾕⾖⾗⾘⾙⾚⾛⾜⾝⾞⾟⾠⾡⾢⾣⾤⾥⾦⾧⾨⾩⾪⾫⾬⾭⾮⾯⾰⾱⾲⾳⾴⾵⾶⾷⾸⾹⾺⾻⾼髙⾽⾾⾿⿀⿁⿂⿃⿄⿅⿆⿇⿈⿉⿊⿋⿌⿍⿎⿏⿐⿑⿒⿓⿔⿕⺠⻬⻩⻢⻜⻅⺟⻓"; // 对应汉字 const string target = "一丨丶丿乙亅二亠人儿入八冂冖冫几凵刀力勹匕匚匸十卜卩厂厶又口囗土士夂夊夕大女子宀寸小尢尸屮山巛工己巾干幺广廴廾弋弓彐彡彳心戈戶手支攴文斗斤方无日曰月木欠止歹殳毋比毛氏气水火爪父爻爿片牙牛犬玄玉瓜瓦甘生用田疋疒癶白皮皿目矛矢石示禸禾穴立竹米糸缶网羊羽老而耒耳聿肉臣自至臼舌舛舟艮色艸虍虫血行衣襾見角言谷豆豕豸貝赤走足身車辛辰辵邑酉采里金長門阜隶隹雨青非面革韋韭音頁風飛食首香馬骨高高髟鬥鬯鬲鬼魚鳥鹵鹿麥麻黃黍黑黹黽鼎鼓鼠鼻齊齒龍龜龠民齐黄马飞见母长"; for (int i = 0; i < questionTitle.Length; i++) { int index = source.IndexOf(questionTitle[i]); if (index >= 0) { questionTitle = questionTitle.Remove(i, 1).Insert(i, target[index].ToString()); } }3.5 总结项目引入了 PresentationCore.dll,Typography.OpenFonttry { // 8. 提取当前页面加密的base64代码 var matchBase64 = Regex.Match(workPageResponse, @"font-cxsecret';src:url\('(.*?)'\)"); var fontBytes = Convert.FromBase64String(matchBase64.Groups[1].Value.Split(',')[1]); // 将字节写到目录的cache文件夹下 var fontFilename = $"{Path.GetRandomFileName()}.ttf"; var fontPath = Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "cache", fontFilename); if (!Directory.Exists(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "cache"))) { Directory.CreateDirectory(Path.Combine(AppDomain.CurrentDomain.BaseDirectory, "cache")); } File.WriteAllBytes(fontPath, fontBytes); var fontReader = new OpenFontReader(); var font = fontReader.Read(new MemoryStream(fontBytes)); var unicodeAndContourPair = new Dictionary<string, string>(); // 将原生字体key => value 反向映射 var swappedDict = new Dictionary<string, string>(); foreach (var swappedTempDict in Context.OriginFontsDictionary) { swappedDict[swappedTempDict.Value] = swappedTempDict.Key; } var families = Fonts.GetFontFamilies(fontPath); foreach (var family in families) { var typefaces = family.GetTypefaces(); foreach (var typeface in typefaces) { typeface.TryGetGlyphTypeface(out var glyph); var characterMap = glyph.CharacterToGlyphMap; foreach (var kvp in characterMap) { var keyHex = "uni" + kvp.Key.ToString("X").ToUpper(); var fontGlyph = font.GetGlyph(kvp.Value); var sb = new StringBuilder(); foreach (var fontGlyphGlyphPoint in fontGlyph.GlyphPoints) { sb.Append( $"{fontGlyphGlyphPoint.X}{fontGlyphGlyphPoint.Y}{(fontGlyphGlyphPoint.onCurve ? "1" : "0")}"); } unicodeAndContourPair[keyHex] = CommonUtil.GetMd5(sb.ToString()); } } } // 遍历加密的 pair var keysList = new Dictionary<string, string>(); foreach (var keyValue in unicodeAndContourPair) { keysList[keyValue.Key] = swappedDict[keyValue.Value].Replace("uni", "\\u"); keysList[keyValue.Key] = Regex.Unescape(keysList[keyValue.Key]); } var questionTitle = questionNodes[0].SelectSingleNode("div[@class='Zy_TItle clearfix']/div").InnerText.Trim(); foreach (var c in questionTitle.ToCharArray()) { var temp = Convert.ToString(Convert.ToUInt32(c), 16).Replace("0x", "").ToUpper(); if (keysList.ContainsKey($"uni{temp}")) questionTitle = questionTitle.Replace(c + "", keysList[$"uni{temp}"]); } // 康熙部首 const string source = "⼀⼁⼂⼃⼄⼅⼆⼇⼈⼉⼊⼋⼌⼍⼎⼏⼐⼑⼒⼓⼔⼕⼖⼗⼘⼙⼚⼛⼜⼝⼞⼟⼠⼡⼢⼣⼤⼥⼦⼧⼨⼩⼪⼫⼬⼭⼮⼯⼰⼱⼲⼳⼴⼵⼶⼷⼸⼹⼺⼻⼼⼽⼾⼿⽀⽁⽂⽃⽄⽅⽆⽇⽈⽉⽊⽋⽌⽍⽎⽏⽐⽑⽒⽓⽔⽕⽖⽗⽘⽙⽚⽛⽜⽝⽞⽟⽠⽡⽢⽣⽤⽥⽦⽧⽨⽩⽪⽫⽬⽭⽮⽯⽰⽱⽲⽳⽴⽵⽶⽷⽸⽹⽺⽻⽼⽽⽾⽿⾀⾁⾂⾃⾄⾅⾆⾇⾈⾉⾊⾋⾌⾍⾎⾏⾐⾑⾒⾓⾔⾕⾖⾗⾘⾙⾚⾛⾜⾝⾞⾟⾠⾡⾢⾣⾤⾥⾦⾧⾨⾩⾪⾫⾬⾭⾮⾯⾰⾱⾲⾳⾴⾵⾶⾷⾸⾹⾺⾻⾼髙⾽⾾⾿⿀⿁⿂⿃⿄⿅⿆⿇⿈⿉⿊⿋⿌⿍⿎⿏⿐⿑⿒⿓⿔⿕⺠⻬⻩⻢⻜⻅⺟⻓"; // 对应汉字 const string target = "一丨丶丿乙亅二亠人儿入八冂冖冫几凵刀力勹匕匚匸十卜卩厂厶又口囗土士夂夊夕大女子宀寸小尢尸屮山巛工己巾干幺广廴廾弋弓彐彡彳心戈戶手支攴文斗斤方无日曰月木欠止歹殳毋比毛氏气水火爪父爻爿片牙牛犬玄玉瓜瓦甘生用田疋疒癶白皮皿目矛矢石示禸禾穴立竹米糸缶网羊羽老而耒耳聿肉臣自至臼舌舛舟艮色艸虍虫血行衣襾見角言谷豆豕豸貝赤走足身車辛辰辵邑酉采里金長門阜隶隹雨青非面革韋韭音頁風飛食首香馬骨高高髟鬥鬯鬲鬼魚鳥鹵鹿麥麻黃黍黑黹黽鼎鼓鼠鼻齊齒龍龜龠民齐黄马飞见母长"; for (var i = 0; i < questionTitle.Length; i++) { var index = source.IndexOf(questionTitle[i]); if (index >= 0) { questionTitle = questionTitle.Remove(i, 1).Insert(i, target[index].ToString()); } } } catch (Exception e) { Console.WriteLine(e); throw; }4.引用关于超星学习通网页版字体加密分析 (出处: 吾爱破解论坛):https://www.52pojie.cn/thread-1631357-1-1.htmlLayoutFarm/Typography: C# Font Reader (TrueType / OpenType / OpenFont / CFF / woff / woff2) , Glyphs Layout and Rendering (github.com):https://github.com/LayoutFarm/Typography研究学习通答题字体加密的随笔 - 易姐的博客 (shakaianee.top):https://shakaianee.top/archives/558/presentationcore.dll free download | DLL‑files.com (dll-files.com): https://www.dll-files.com/presentationcore.dll.html
-
山西省成人高考成绩批量查询工具 目标站点:https://gkpt.sxkszx.cn/Ck-student-web/#一、步骤分析1.登录的时候有个验证码需要过2.成绩查询是html解析,正则匹配一下就取出来了二、工具及源码技术点:网络爬虫,dataGridView导出为excel适合初学者入门学习和二次开发github链接:https://github.com/lisongkun/shanxi-adult-education-batch-query-score引用1.SunnyUI Github:https://github.com/yhuse/SunnyUI2.C# Winform中DataGridView导出为Excel看这一篇就够了,详细!!!(完整快速版):https://blog.csdn.net/Houoy/article/details/1060278793.Fluent HTTP:https://flurl.dev/docs/fluent-http/
-
homestead中如何切换某应用环境变量对应的版本? 在Homestead中切换PHP环境变量对应的版本可以通过以下步骤完成:登录到Homestead虚拟机中,可以使用如下命令登录:vagrant ssh执行以下命令查看Homestead中已经安装的PHP版本:update-alternatives --display php执行后,会列出Homestead中已经安装的PHP版本以及它们的路径。执行以下命令来切换PHP环境变量对应的版本:sudo update-alternatives --set php /usr/bin/phpX.X其中,X.X是你想要切换到的PHP版本号,比如如果你想切换到PHP 7.4版本,命令应该是:sudo update-alternatives --set php /usr/bin/php7.4切换成功后,执行以下命令查看PHP版本是否已经切换:php -v执行后,会显示当前PHP版本号,如果版本号是你想要的版本,则切换成功。
-
selenium爬虫如何防止被浏览器特征抓取反爬 前言爬网站的时候遇到了cf拦截,根据百度到的尝试添加参数还是无法跳过service = Service('msedgedriver.exe') options = Options() # 开启开发者模式 options.add_experimental_option('excludeSwitches', ['enable-automation']) # 禁用Blink运行时功能 options.add_argument('--disable-blink-features=AutomationControlled') driver = webdriver.Edge(service=service)undetected-chromedriverOptimized Selenium Chromedriver patch which does not trigger anti-bot services like Distill Network / Imperva / DataDome / Botprotect.io Automatically downloads the driver binary and patches it.Tested until current chrome beta versionsWorks also on Brave Browser and many other Chromium based browsers, some tweakingPython 3.6++**我主要使用的Edge,介绍说会自动下载Chrome,并没有体验到,于是自己安装了Chrome浏览器代码跟之前selenium的相差不大,成功解决了问题,再没出现过Cf拦截from pyquery import PyQuery as pq import re import time from undetected_chromedriver import ChromeOptions import undetected_chromedriver as uc options = ChromeOptions() options.add_argument('--headless') options.add_argument('--disable-gpu') driver = uc.Chrome(options=options) driver.get('http://...') html_source = driver.page_source doc = pq(html_source) titles = doc.find('tag')引用1.ultrafunkamsterdam/undetected-chromedriver:https://github.com/ultrafunkamsterdam/undetected-chromedriver2.Chrome Headless Detection (Round II):https://intoli.com/blog/not-possible-to-block-chrome-headless/chrome-headless-test.html3.selenium爬虫如何防止被浏览器特征抓取反爬,undetected_chromedriver他来了。:https://blog.csdn.net/wywinstonwy/article/details/118479162
-
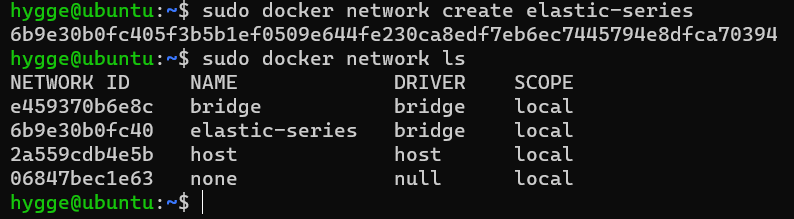
Laravel+Scout+Elasticsearch实现中文分词搜索功能 一、准备工作1.配置机器ssh连接sudo apt update sudo apt install openssh-server # ssh二、Docker安装ElasticSearch2.1 安装说明在平时工作的时候,开发环境大多数会安装单机ElasticSearch,但生产环境基本会安装ElasticSearch集群版。不过中文搜索,会实现分词器集成,可以采用IK分词器。ElasticSearch采用Kibana实现数据可视化分析也是当前主流,所以我们除了安装ElasticSearch和IK分词器外,还需要安装Kibana。安装实践:1:ElasticSearch单机安装 2:IK分词器安装 3:Kibana安装 2.2 Docker安装ElasticSearch当前ElasticSearch已经到了8.0,新版本都有很多新特性,性能和功能都有大幅提升,我们建议使用较高版本,这里将采用8.6.0版本。 2.2.1 网络创建高版本安装Kibana的时候需要和ElasticSearch在同一网段内,所以采用docker安装首先要确认网段,为了方便操作,我们直接创建一个网络,创建脚本如下:sudo docker network create elastic-series2.2.2 ElasticSearch安装安装ElasticSearch脚本如下:sudo docker run -d \ --name elasticsearch \ -e "ES_JAVA_OPTS=-Xms512m -Xmx512m" \ -e "discovery.type=single-node" \ -v es-data:/usr/share/elasticsearch/data \ -v es-plugins:/usr/share/elasticsearch/plugins \ --privileged \ --network elastic-series \ -p 9200:9200 \ -p 9300:9300 \ elasticsearch:8.6.0命令说明:-e "cluster.name=es-docker-cluster":设置集群名称-e "http.host=0.0.0.0":监听的地址,可以外网访问-e "ES_JAVA_OPTS=-Xms512m -Xmx512m":内存大小-e "discovery.type=single-node":非集群模式-v es-data:/usr/share/elasticsearch/data:挂载逻辑卷,绑定elasticsearch的数据目录-v es-logs:/usr/share/elasticsearch/logs:挂载逻辑卷,绑定elasticsearch的日志目录-v es-plugins:/usr/share/elasticsearch/plugins:挂载逻辑卷,绑定elasticsearch的插件目录--privileged:授予逻辑卷访问权--network elastic-series :加入一个名为elastic-series的网络中-p 9200:9200:端口映射配置Docker安装ElasticSearch下载可能会比较慢,需要耐心等待,效果如下:安装完成后,在浏览器中输入:http://192.168.211.128:9200/即可看到elasticsearch的响应结果:You can Generate a new password using/usr/share/elasticsearch/elasticsearch-setup-passwords auto/interactiveinteractive is where you will have to enter password for all user.auto will just print passwords on the shell.elseYou can turn off x-pack security in elasticsearch.yml2.2.2.1 关闭安全验证1.进入容器内部sudo docker exec -it -u root <container> bash2.安装Vim,为编辑文件做准备apt-get update apt-get install vim3.编辑config/elasticsearch.yml# 追加 xpack.security.enabled: false4.退出并重启容器exit sudo docker restart <container>刷新页面,得到正常响应 3 安装Kibana我们可以基于Http请求操作ElasticSearch,但基于Http操作比较麻烦,我们可以采用Kibana实现可视化操作。2.2.2.2 设置密码详见引用第九条三、Docker安装Kibana3.1 Kibana介绍Kibana 是一个免费且开放的用户界面,能够让您对 Elasticsearch 数据进行可视化,并让您在 Elastic Stack 中进行导航。您可以进行各种操作,从跟踪查询负载,到理解请求如何流经您的整个应用,都能轻松完成。Kibana 让您能够自由地选择如何呈现自己的数据。不过借助 Kibana 的交互式可视化,您可以先从一个问题出发,看看能够从中发现些什么。 可视化界面如下: 3.2 Kibana安装使用Docker安装Kibana非常简单,只需要执行如下命令即可,但是执行命令需要注意Kibana操作的ElasticSearch地址,因为Kibana是需要连接ElasticSearch进行操作的,命令如下:sudo docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://192.168.211.128:9200 \ --network elastic-series \ -p 5601:5601 \ kibana:8.6.0命令说明:--network elastic-series :加入一个名为elastic-series的网络中,与elasticsearch在同一个网络中-e ELASTICSEARCH_HOSTS=http://192.168.211.128:9200":设置elasticsearch的地址,因为kibana已经与elasticsearch在一个网络,因此可以用容器名直接访问elasticsearch,也可以写IP地址实现访问。-p 5601:5601:端口映射配置安装的时候如果没有镜像,会下载镜像,效果如下:kibana安装会比较耗时间,也需要耐心等待下载安装完成,如果想实时知道服务安装运行的状态,可以通过查看日志实现,查看日志如下:docker logs -f kibana日志中如果出现了http://0.0.0.0:5601即可访问Kibana后台服务,日志如下:访问http://192.168.211.128:5601效果如下:可以点击Add integrations,添加示例数据,如下图,随意选一个即可,不选其实也是可以的。 3.3 Kibana中文配置我们发现Kibana是英文面板,看起来不是很方便,但Kibana是支持中文配置,所以我们可以把Kibana配置成中文版,便于我们操作。切换中文操作如下:#进入容器 docker exec -it kibana /bin/bash #进入配置文件目录 cd /usr/share/kibana/config #编辑文件kibana.yml vi kibana.yml #在最后一行添加如下配置 i18n.locale: zh-CN #保存退出 exit #并重启容器 docker restart kibana 等待Kibana容器启动,再次访问http://192.168.211.128:5601/效果如下: 四、IK分词器安装我们打开Kibana,点击开发工具,操作如下:输入如下操作,用于查询分词:上图测试代码如下:GET _analyze { "analyzer": "standard", "text": "过去无可挽回,未来可以改变" }表示使用standard对过去无可挽回,未来可以改变进行分词。分词:提取一句话或者一篇文章中的词语。我们在使用ElasticSearch的时候,默认用standard分词器,但standard分词器使用的是按空格分词,这种分词操作方法不符合中文分词标准,我们需要额外安装中文分词器。 4.1 IK分词器介绍IK Analyzer是一个开源的,基于java语言开发的轻量级的中文分词工具包。从2006年12月推出1.0版开始, IKAnalyzer已经推出了多个大版本。最初,它是以开源项目Luence为应用主体的,结合词典分词和文法分析算法的中文分词组件。IK Analyzer则发展为面向Java的公用分词组件,独立于Lucene项目,同时提供了对Lucene的默认优化实现。 ElasticSearch内核其实就是基于Lucene,所以我们可以直接在ElasticSearch中集成IK分词器,IK分词器集成ElasticSearch下载地址:https://github.com/medcl/elasticsearch-analysis-ik/releases 4.2 IK分词器配置下载安装包elasticsearch-analysis-ik-8.6.0.zip后,并解压,目录如下:我们只需要将上面ik拷贝到ElasticSearch的plugins目录中即可,但由于当前服务采用的是docker安装,所以需要将文件拷贝到docker容器的plugins目录才行。操作如下:#将ik文件夹拷贝到elasticsearch容器中 docker cp ik elasticsearch:/usr/share/elasticsearch/plugins #重启容器 docker restart elasticsearch操作效果如下: 4.3 分词测试IK分词器包含两种模式:ik_smart:最少切分ik_max_word:最细切分 前面使用默认的standard分词器,对中文分词非常难用,安装IK分词器后,我们可以使用IK分词器测试,测试代码如下:GET /_analyze { "analyzer": "ik_max_word", "text": "过去无可挽回,未来可以改变" }测试效果如下:我们可以发现对中文的分词效果是比较不错的,但也存在一些不足,比如无可挽回我们希望它是一个词,而可挽回我们希望它不被识别一个词,又该如何实现呢?自定义词典参考引用中的第2个链接五、Laravel集成使用的第三方包matchish/laravel-scout-elasticsearch:https://github.com/matchish/laravel-scout-elasticsearch名称版本php^8.0.2laravel/framework^9.19matchish/laravel-scout-elasticsearch^6.05.1 介绍Laravel Scout 为 Eloquent 模型 的全文搜索提供了一个简单的基于驱动程序的解决方案,通过使用模型观察者,Scout 将自动同步 Eloquent 记录的搜索索引。目前,Scout 附带 Algolia、MeiliSearch 和 MySQL / PostgreSQL (database) 驱动程序。此外,Scout 包括一个「collection」驱动程序,该驱动程序专为本地开发使用而设计,不需要任何外部依赖项或第三方服务。此外,编写自定义驱动程序很简单,你可以使用自己的搜索实现自由扩展 Scout。由于没有自带Elasticsearch的驱动,所以需要第三方包5.1 安装包和配置1.引入包composer require matchish/laravel-scout-elasticsearch2.env设置环境变量SCOUT_DRIVER=Matchish\ScoutElasticSearch\Engines\ElasticSearchEngine ELASTICSEARCH_HOST=192.168.211.128:92003.config/app.php中配置provider'providers' => [ // Other Service Providers \Matchish\ScoutElasticSearch\ElasticSearchServiceProvider::class ],4.发布配置文件php artisan vendor:publish --tag config会新增config/elasticsearch.php文件5.2 更新模型1.更新模型<?php namespace App\Models; use App\Trait\DefaultDatetimeFormat; use Illuminate\Database\Eloquent\Model; use Laravel\Scout\Searchable; class Video extends Model { use DefaultDatetimeFormat, Searchable; protected $fillable = ['img', 'title', 'innerVideoHref', 'innerHref', 'viewNumber', 'likeNumber', 'helpInfo', 'type']; /** * Get the indexable data array for the model. * 我想只根据title来分词检索 * @return array */ public function toSearchableArray() { return $this->only(['title']); } /** * Get the index name for the model. * 指定索引的名称 * @return string */ public function searchableAs() { return 'videos_index'; } /** * 指定 搜索索引中存储的唯一ID * @return mixed */ public function getScoutKey() { return $this->id; } /** * 指定 搜索索引中存储的唯一ID的键名 * @return string */ public function getScoutKeyName() { return 'id'; } }2.修改config/elasticsearch.php<?php return [ 'host' => env('ELASTICSEARCH_HOST','192.168.211.128:9200'), 'indices' => [ 'mappings' => [ 'default' => [ 'properties' => [ 'id' => [ 'type' => 'keyword', ], ], ], // 与上一步的索引名称对应 'videos_index' => [ 'properties' => [ 'title' => [ 'type' => 'text', 'analyzer' => 'ik_max_word', 'search_analyzer' => 'ik_max_word', ], ], ], ], 'settings' => [ 'default' => [ 'number_of_shards' => 1, 'number_of_replicas' => 0, ], ], ], ];3.索引的批量导入php artisan scout:import5.3 使用场景:根据当前播放的视频名称,检索出来十个相关的视频作为推荐public function play($type, $id) { // 直接根据类型和视频ID进行查询 $video = Video::where('type', $type)->where('id', $id)->first(); $videoSeries = Video::search($video->title)->take(10)->get(); dd($videoSeries); }六、遇到的问题6.1 Kibana 服务器尚未准备就绪。在服务器上部署时,访问Kibana出现了查看日志docker logs kibana [2023-01-18T02:05:30.467+00:00][ERROR][elasticsearch-service] Unable to retrieve version information from Elasticsearch nodes. connect ECONNREFUSED 127.0.0.1:9200原因是创建容器时填写的sudo docker run -d \ --name kibana \ -e ELASTICSEARCH_HOSTS=http://127.0.0.1:9200 \ -p 5601:5601 \ kibana:8.6.0这里不可以使用127.0.0.1需要使用私有IP重新创建后即可正常访问6.2 无法访问在虚拟机上部署时按照步骤并开放端口是可以访问9200和5601端口在服务器上按照 创建网络 -> 创建elasticsearch、kibana容器设置网络 的步骤走下来 始终访问不了对应的端口不清楚原因,于是去掉了创建容器时的网络配置引用1.如何在 Ubuntu 20.04 启用 SSH :https://zhuanlan.zhihu.com/p/1457637892.你必须会的Docker安装ElasticSearch教程:https://juejin.cn/post/70741156903402864723.Install Kibana with Docker:https://www.elastic.co/guide/en/kibana/current/docker.html4.Elasticsearch_Installation_asking for username and password:https://stackoverflow.com/questions/71269878/elasticsearch-installation-asking-for-username-and-password5.Releases · medcl/elasticsearch-analysis-ik (github.com):https://github.com/medcl/elasticsearch-analysis-ik/releases6.matchish/laravel-scout-elasticsearch: Search among multiple models with ElasticSearch and Laravel Scout (github.com):https://github.com/matchish/laravel-scout-elasticsearch7.只需五步 集成新版 Elasticsearch7.9 中文搜索 到你的 Laravel7 项目:https://juejin.cn/post/68651885751143301268.php Laravel 使用elasticsearch+ik中文分词器搭建搜索引擎:https://blog.csdn.net/weixin_42701376/article/details/126782529?spm=1001.2101.3001.6650.2&utm_medium=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-2-126782529-blog-109466440.pc_relevant_multi_platform_whitelistv4&depth_1-utm_source=distribute.pc_relevant.none-task-blog-2~default~BlogCommendFromBaidu~Rate-2-126782529-blog-109466440.pc_relevant_multi_platform_whitelistv4&utm_relevant_index=39.docker中设置elasticsearch、kibana用户名密码、修改密码:https://blog.csdn.net/IT_road_qxc/article/details/121858843
-
php-simple-html-dom-parser for PHP7.3 + If you use php 7.3 and higher, then use my edits. Otherwise, you will get errors due to migration to PCRE2 in new versions of PHP.For example: Warning: preg_match_all (): Compilation failed: invalid range in character class at offset 4fixapp\Utils\HtmlDomParser.php<?php namespace App\Utils; require 'simplehtmldom_1_5' . DIRECTORY_SEPARATOR . 'simple_html_dom.php'; class HtmlDomParser { static public function file_get_html($file) { return file_get_html($file); } static public function str_get_html($str) { return str_get_html($str); } }app\Utils\simplehtmldom_1_5\simple_html_dom.php<?php /** * Website: http://sourceforge.net/projects/simplehtmldom/ * Acknowledge: Jose Solorzano (https://sourceforge.net/projects/php-html/) * Contributions by: * Yousuke Kumakura (Attribute filters) * Vadim Voituk (Negative indexes supports of "find" method) * Antcs (Constructor with automatically load contents either text or file/url) * * all affected sections have comments starting with "PaperG" * * Paperg - Added case insensitive testing of the value of the selector. * Paperg - Added tag_start for the starting index of tags - NOTE: This works but not accurately. * This tag_start gets counted AFTER \r\n have been crushed out, and after the remove_noice calls so it will not reflect the REAL position of the tag in the source, * it will almost always be smaller by some amount. * We use this to determine how far into the file the tag in question is. This "percentage will never be accurate as the $dom->size is the "real" number of bytes the dom was created from. * but for most purposes, it's a really good estimation. * Paperg - Added the forceTagsClosed to the dom constructor. Forcing tags closed is great for malformed html, but it CAN lead to parsing errors. * Allow the user to tell us how much they trust the html. * Paperg add the text and plaintext to the selectors for the find syntax. plaintext implies text in the innertext of a node. text implies that the tag is a text node. * This allows for us to find tags based on the text they contain. * Create find_ancestor_tag to see if a tag is - at any level - inside of another specific tag. * Paperg: added parse_charset so that we know about the character set of the source document. * NOTE: If the user's system has a routine called get_last_retrieve_url_contents_content_type availalbe, we will assume it's returning the content-type header from the * last transfer or curl_exec, and we will parse that and use it in preference to any other method of charset detection. * * Licensed under The MIT License * Redistributions of files must retain the above copyright notice. * * @author S.C. Chen <me578022@gmail.com> * @author John Schlick * @author Rus Carroll * @version 1.11 ($Rev: 184 $) * @package PlaceLocalInclude * @subpackage simple_html_dom */ /** * All of the Defines for the classes below. * @author S.C. Chen <me578022@gmail.com> */ define('HDOM_TYPE_ELEMENT', 1); define('HDOM_TYPE_COMMENT', 2); define('HDOM_TYPE_TEXT', 3); define('HDOM_TYPE_ENDTAG', 4); define('HDOM_TYPE_ROOT', 5); define('HDOM_TYPE_UNKNOWN', 6); define('HDOM_QUOTE_DOUBLE', 0); define('HDOM_QUOTE_SINGLE', 1); define('HDOM_QUOTE_NO', 3); define('HDOM_INFO_BEGIN', 0); define('HDOM_INFO_END', 1); define('HDOM_INFO_QUOTE', 2); define('HDOM_INFO_SPACE', 3); define('HDOM_INFO_TEXT', 4); define('HDOM_INFO_INNER', 5); define('HDOM_INFO_OUTER', 6); define('HDOM_INFO_ENDSPACE', 7); define('DEFAULT_TARGET_CHARSET', 'UTF-8'); define('DEFAULT_BR_TEXT', "\r\n"); // helper functions // ----------------------------------------------------------------------------- // get html dom from file // $maxlen is defined in the code as PHP_STREAM_COPY_ALL which is defined as -1. function file_get_html($url, $use_include_path = false, $context = null, $offset = -1, $maxLen = -1, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { // We DO force the tags to be terminated. $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); // For sourceforge users: uncomment the next line and comment the retreive_url_contents line 2 lines down if it is not already done. $contents = file_get_contents($url, $use_include_path, $context, $offset); // Paperg - use our own mechanism for getting the contents as we want to control the timeout. // $contents = retrieve_url_contents($url); if (empty($contents)) { return false; } // The second parameter can force the selectors to all be lowercase. $dom->load($contents, $lowercase, $stripRN); return $dom; } // get html dom from string function str_get_html($str, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $dom = new simple_html_dom(null, $lowercase, $forceTagsClosed, $target_charset, $defaultBRText); if (empty($str)) { $dom->clear(); return false; } $dom->load($str, $lowercase, $stripRN); return $dom; } // dump html dom tree function dump_html_tree($node, $show_attr = true, $deep = 0) { $node->dump($node); } /** * simple html dom node * PaperG - added ability for "find" routine to lowercase the value of the selector. * PaperG - added $tag_start to track the start position of the tag in the total byte index * * @package PlaceLocalInclude */ class simple_html_dom_node { public $nodetype = HDOM_TYPE_TEXT; public $tag = 'text'; public $attr = array(); public $children = array(); public $nodes = array(); public $parent = null; public $_ = array(); public $tag_start = 0; private $dom = null; function __construct($dom) { $this->dom = $dom; $dom->nodes[] = $this; } function __destruct() { $this->clear(); } function __toString() { return $this->outertext(); } // clean up memory due to php5 circular references memory leak... function clear() { $this->dom = null; $this->nodes = null; $this->parent = null; $this->children = null; } // dump node's tree function dump($show_attr = true, $deep = 0) { $lead = str_repeat(' ', $deep); echo $lead . $this->tag; if ($show_attr && count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) echo "[$k]=>\"" . $this->$k . '", '; echo ')'; } echo "\n"; foreach ($this->nodes as $c) $c->dump($show_attr, $deep + 1); } // Debugging function to dump a single dom node with a bunch of information about it. function dump_node() { echo $this->tag; if (count($this->attr) > 0) { echo '('; foreach ($this->attr as $k => $v) { echo "[$k]=>\"" . $this->$k . '", '; } echo ')'; } if (count($this->attr) > 0) { echo ' $_ ('; foreach ($this->_ as $k => $v) { if (is_array($v)) { echo "[$k]=>("; foreach ($v as $k2 => $v2) { echo "[$k2]=>\"" . $v2 . '", '; } echo ")"; } else { echo "[$k]=>\"" . $v . '", '; } } echo ")"; } if (isset($this->text)) { echo " text: (" . $this->text . ")"; } echo " children: " . count($this->children); echo " nodes: " . count($this->nodes); echo " tag_start: " . $this->tag_start; echo "\n"; } // returns the parent of node function parent() { return $this->parent; } // returns children of node function children($idx = -1) { if ($idx === -1) return $this->children; if (isset($this->children[$idx])) return $this->children[$idx]; return null; } // returns the first child of node function first_child() { if (count($this->children) > 0) return $this->children[0]; return null; } // returns the last child of node function last_child() { if (($count = count($this->children)) > 0) return $this->children[$count - 1]; return null; } // returns the next sibling of node function next_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (++$idx >= $count) return null; return $this->parent->children[$idx]; } // returns the previous sibling of node function prev_sibling() { if ($this->parent === null) return null; $idx = 0; $count = count($this->parent->children); while ($idx < $count && $this !== $this->parent->children[$idx]) ++$idx; if (--$idx < 0) return null; return $this->parent->children[$idx]; } // function to locate a specific ancestor tag in the path to the root. function find_ancestor_tag($tag) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // Start by including ourselves in the comparison. $returnDom = $this; while (!is_null($returnDom)) { if (is_object($debugObject)) { $debugObject->debugLog(2, "Current tag is: " . $returnDom->tag); } if ($returnDom->tag == $tag) { break; } $returnDom = $returnDom->parent; } return $returnDom; } // get dom node's inner html function innertext() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = ''; foreach ($this->nodes as $n) $ret .= $n->outertext(); return $ret; } // get dom node's outer text (with tag) function outertext() { global $debugObject; if (is_object($debugObject)) { $text = ''; if ($this->tag == 'text') { if (!empty($this->text)) { $text = " with text: " . $this->text; } } $debugObject->debugLog(1, 'Innertext of tag: ' . $this->tag . $text); } if ($this->tag === 'root') return $this->innertext(); // trigger callback if ($this->dom && $this->dom->callback !== null) { call_user_func_array($this->dom->callback, array($this)); } if (isset($this->_[HDOM_INFO_OUTER])) return $this->_[HDOM_INFO_OUTER]; if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); // render begin tag if ($this->dom && $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]) { $ret = $this->dom->nodes[$this->_[HDOM_INFO_BEGIN]]->makeup(); } else { $ret = ""; } // render inner text if (isset($this->_[HDOM_INFO_INNER])) { // If it's a br tag... don't return the HDOM_INNER_INFO that we may or may not have added. if ($this->tag != "br") { $ret .= $this->_[HDOM_INFO_INNER]; } } else { if ($this->nodes) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->outertext()); } } } // render end tag if (isset($this->_[HDOM_INFO_END]) && $this->_[HDOM_INFO_END] != 0) $ret .= '</' . $this->tag . '>'; return $ret; } // get dom node's plain text function text() { if (isset($this->_[HDOM_INFO_INNER])) return $this->_[HDOM_INFO_INNER]; switch ($this->nodetype) { case HDOM_TYPE_TEXT: return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); case HDOM_TYPE_COMMENT: return ''; case HDOM_TYPE_UNKNOWN: return ''; } if (strcasecmp($this->tag, 'script') === 0) return ''; if (strcasecmp($this->tag, 'style') === 0) return ''; $ret = ''; // In rare cases, (always node type 1 or HDOM_TYPE_ELEMENT - observed for some span tags, and some p tags) $this->nodes is set to NULL. // NOTE: This indicates that there is a problem where it's set to NULL without a clear happening. // WHY is this happening? if (!is_null($this->nodes)) { foreach ($this->nodes as $n) { $ret .= $this->convert_text($n->text()); } } return $ret; } function xmltext() { $ret = $this->innertext(); $ret = str_ireplace('<![CDATA[', '', $ret); $ret = str_replace(']]>', '', $ret); return $ret; } // build node's text with tag function makeup() { // text, comment, unknown if (isset($this->_[HDOM_INFO_TEXT])) return $this->dom->restore_noise($this->_[HDOM_INFO_TEXT]); $ret = '<' . $this->tag; $i = -1; foreach ($this->attr as $key => $val) { ++$i; // skip removed attribute if ($val === null || $val === false) continue; $ret .= $this->_[HDOM_INFO_SPACE][$i][0]; //no value attr: nowrap, checked selected... if ($val === true) $ret .= $key; else { switch ($this->_[HDOM_INFO_QUOTE][$i]) { case HDOM_QUOTE_DOUBLE: $quote = '"'; break; case HDOM_QUOTE_SINGLE: $quote = '\''; break; default: $quote = ''; } $ret .= $key . $this->_[HDOM_INFO_SPACE][$i][1] . '=' . $this->_[HDOM_INFO_SPACE][$i][2] . $quote . $val . $quote; } } $ret = $this->dom->restore_noise($ret); return $ret . $this->_[HDOM_INFO_ENDSPACE] . '>'; } // find elements by css selector //PaperG - added ability for find to lowercase the value of the selector. function find($selector, $idx = null, $lowercase = false) { $selectors = $this->parse_selector($selector); if (($count = count($selectors)) === 0) return array(); $found_keys = array(); // find each selector for ($c = 0; $c < $count; ++$c) { // The change on the below line was documented on the sourceforge code tracker id 2788009 // used to be: if (($levle=count($selectors[0]))===0) return array(); if (($levle = count($selectors[$c])) === 0) return array(); if (!isset($this->_[HDOM_INFO_BEGIN])) return array(); $head = array($this->_[HDOM_INFO_BEGIN] => 1); // handle descendant selectors, no recursive! for ($l = 0; $l < $levle; ++$l) { $ret = array(); foreach ($head as $k => $v) { $n = ($k === -1) ? $this->dom->root : $this->dom->nodes[$k]; //PaperG - Pass this optional parameter on to the seek function. $n->seek($selectors[$c][$l], $ret, $lowercase); } $head = $ret; } foreach ($head as $k => $v) { if (!isset($found_keys[$k])) $found_keys[$k] = 1; } } // sort keys ksort($found_keys); $found = array(); foreach ($found_keys as $k => $v) $found[] = $this->dom->nodes[$k]; // return nth-element or array if (is_null($idx)) return $found; else if ($idx < 0) $idx = count($found) + $idx; return (isset($found[$idx])) ? $found[$idx] : null; } // seek for given conditions // PaperG - added parameter to allow for case insensitive testing of the value of a selector. protected function seek($selector, &$ret, $lowercase = false) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } list($tag, $key, $val, $exp, $no_key) = $selector; // xpath index if ($tag && $key && is_numeric($key)) { $count = 0; foreach ($this->children as $c) { if ($tag === '*' || $tag === $c->tag) { if (++$count == $key) { $ret[$c->_[HDOM_INFO_BEGIN]] = 1; return; } } } return; } $end = (!empty($this->_[HDOM_INFO_END])) ? $this->_[HDOM_INFO_END] : 0; if ($end == 0) { $parent = $this->parent; while (!isset($parent->_[HDOM_INFO_END]) && $parent !== null) { $end -= 1; $parent = $parent->parent; } $end += $parent->_[HDOM_INFO_END]; } for ($i = $this->_[HDOM_INFO_BEGIN] + 1; $i < $end; ++$i) { $node = $this->dom->nodes[$i]; $pass = true; if ($tag === '*' && !$key) { if (in_array($node, $this->children, true)) $ret[$i] = 1; continue; } // compare tag if ($tag && $tag != $node->tag && $tag !== '*') { $pass = false; } // compare key if ($pass && $key) { if ($no_key) { if (isset($node->attr[$key])) $pass = false; } else { if (($key != "plaintext") && !isset($node->attr[$key])) $pass = false; } } // compare value if ($pass && $key && $val && $val !== '*') { // If they have told us that this is a "plaintext" search then we want the plaintext of the node - right? if ($key == "plaintext") { // $node->plaintext actually returns $node->text(); $nodeKeyValue = $node->text(); } else { // this is a normal search, we want the value of that attribute of the tag. $nodeKeyValue = $node->attr[$key]; } if (is_object($debugObject)) { $debugObject->debugLog(2, "testing node: " . $node->tag . " for attribute: " . $key . $exp . $val . " where nodes value is: " . $nodeKeyValue); } //PaperG - If lowercase is set, do a case insensitive test of the value of the selector. if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($nodeKeyValue)); } else { $check = $this->match($exp, $val, $nodeKeyValue); } if (is_object($debugObject)) { $debugObject->debugLog(2, "after match: " . ($check ? "true" : "false")); } // handle multiple class if (!$check && strcasecmp($key, 'class') === 0) { foreach (explode(' ', $node->attr[$key]) as $k) { // Without this, there were cases where leading, trailing, or double spaces lead to our comparing blanks - bad form. if (!empty($k)) { if ($lowercase) { $check = $this->match($exp, strtolower($val), strtolower($k)); } else { $check = $this->match($exp, $val, $k); } if ($check) break; } } } if (!$check) $pass = false; } if ($pass) $ret[$i] = 1; unset($node); } // It's passed by reference so this is actually what this function returns. if (is_object($debugObject)) { $debugObject->debugLog(1, "EXIT - ret: ", $ret); } } protected function match($exp, $pattern, $value) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } switch ($exp) { case '=': return ($value === $pattern); case '!=': return ($value !== $pattern); case '^=': return preg_match("/^" . preg_quote($pattern, '/') . "/", $value); case '$=': return preg_match("/" . preg_quote($pattern, '/') . "$/", $value); case '*=': if ($pattern[0] == '/') { return preg_match($pattern, $value); } return preg_match("/" . $pattern . "/i", $value); } return false; } protected function parse_selector($selector_string) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } // pattern of CSS selectors, modified from mootools // Paperg: Add the colon to the attrbute, so that it properly finds <tag attr:ibute="something" > like google does. // Note: if you try to look at this attribute, yo MUST use getAttribute since $dom->x:y will fail the php syntax check. // Notice the \[ starting the attbute? and the @? following? This implies that an attribute can begin with an @ sign that is not captured. // This implies that an html attribute specifier may start with an @ sign that is NOT captured by the expression. // farther study is required to determine of this should be documented or removed. // $pattern = "/([\w-:\*]*)(?:\#([\w-]+)|\.([\w-]+))?(?:\[@?(!?[\w-]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; $pattern = "/([\w\-:\*]*)(?:\#([\w\-]+)|\.([\w\-]+))?(?:\[@?(!?[\w\-:]+)(?:([!*^$]?=)[\"']?(.*?)[\"']?)?\])?([\/, ]+)/is"; preg_match_all($pattern, trim($selector_string) . ' simple_html_dom.php', $matches, PREG_SET_ORDER); if (is_object($debugObject)) { $debugObject->debugLog(2, "Matches Array: ", $matches); } $selectors = array(); $result = array(); //print_r($matches); foreach ($matches as $m) { $m[0] = trim($m[0]); if ($m[0] === '' || $m[0] === '/' || $m[0] === '//') continue; // for browser generated xpath if ($m[1] === 'tbody') continue; list($tag, $key, $val, $exp, $no_key) = array($m[1], null, null, '=', false); if (!empty($m[2])) { $key = 'id'; $val = $m[2]; } if (!empty($m[3])) { $key = 'class'; $val = $m[3]; } if (!empty($m[4])) { $key = $m[4]; } if (!empty($m[5])) { $exp = $m[5]; } if (!empty($m[6])) { $val = $m[6]; } // convert to lowercase if ($this->dom->lowercase) { $tag = strtolower($tag); $key = strtolower($key); } //elements that do NOT have the specified attribute if (isset($key[0]) && $key[0] === '!') { $key = substr($key, 1); $no_key = true; } $result[] = array($tag, $key, $val, $exp, $no_key); if (trim($m[7]) === ',') { $selectors[] = $result; $result = array(); } } if (count($result) > 0) $selectors[] = $result; return $selectors; } function __get($name) { if (isset($this->attr[$name])) { return $this->convert_text($this->attr[$name]); } switch ($name) { case 'outertext': return $this->outertext(); case 'innertext': return $this->innertext(); case 'plaintext': return $this->text(); case 'xmltext': return $this->xmltext(); default: return array_key_exists($name, $this->attr); } } function __set($name, $value) { switch ($name) { case 'outertext': return $this->_[HDOM_INFO_OUTER] = $value; case 'innertext': if (isset($this->_[HDOM_INFO_TEXT])) return $this->_[HDOM_INFO_TEXT] = $value; return $this->_[HDOM_INFO_INNER] = $value; } if (!isset($this->attr[$name])) { $this->_[HDOM_INFO_SPACE][] = array(' ', '', ''); $this->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; } $this->attr[$name] = $value; } function __isset($name) { switch ($name) { case 'outertext': return true; case 'innertext': return true; case 'plaintext': return true; } //no value attr: nowrap, checked selected... return (array_key_exists($name, $this->attr)) ? true : isset($this->attr[$name]); } function __unset($name) { if (isset($this->attr[$name])) unset($this->attr[$name]); } // PaperG - Function to convert the text from one character set to another if the two sets are not the same. function convert_text($text) { global $debugObject; if (is_object($debugObject)) { $debugObject->debugLogEntry(1); } $converted_text = $text; $sourceCharset = ""; $targetCharset = ""; if ($this->dom) { $sourceCharset = strtoupper($this->dom->_charset); $targetCharset = strtoupper($this->dom->_target_charset); } if (is_object($debugObject)) { $debugObject->debugLog(3, "source charset: " . $sourceCharset . " target charaset: " . $targetCharset); } if (!empty($sourceCharset) && !empty($targetCharset) && (strcasecmp($sourceCharset, $targetCharset) != 0)) { // Check if the reported encoding could have been incorrect and the text is actually already UTF-8 if ((strcasecmp($targetCharset, 'UTF-8') == 0) && ($this->is_utf8($text))) { $converted_text = $text; } else { $converted_text = iconv($sourceCharset, $targetCharset, $text); } } return $converted_text; } function is_utf8($string) { return (utf8_encode(utf8_decode($string)) == $string); } // camel naming conventions function getAllAttributes() { return $this->attr; } function getAttribute($name) { return $this->__get($name); } function setAttribute($name, $value) { $this->__set($name, $value); } function hasAttribute($name) { return $this->__isset($name); } function removeAttribute($name) { $this->__set($name, null); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = null) { return $this->find($name, $idx); } function parentNode() { return $this->parent(); } function childNodes($idx = -1) { return $this->children($idx); } function firstChild() { return $this->first_child(); } function lastChild() { return $this->last_child(); } function nextSibling() { return $this->next_sibling(); } function previousSibling() { return $this->prev_sibling(); } } /** * simple html dom parser * Paperg - in the find routine: allow us to specify that we want case insensitive testing of the value of the selector. * Paperg - change $size from protected to public so we can easily access it * Paperg - added ForceTagsClosed in the constructor which tells us whether we trust the html or not. Default is to NOT trust it. * * @package PlaceLocalInclude */ class simple_html_dom { public $root = null; public $nodes = array(); public $callback = null; public $lowercase = false; public $size; protected $pos; protected $doc; protected $char; protected $cursor; protected $parent; protected $noise = array(); protected $token_blank = " \t\r\n"; protected $token_equal = ' =/>'; protected $token_slash = " />\r\n\t"; protected $token_attr = ' >'; protected $_charset = ''; protected $_target_charset = ''; protected $default_br_text = ""; // use isset instead of in_array, performance boost about 30%... protected $self_closing_tags = array('img' => 1, 'br' => 1, 'input' => 1, 'meta' => 1, 'link' => 1, 'hr' => 1, 'base' => 1, 'embed' => 1, 'spacer' => 1); protected $block_tags = array('root' => 1, 'body' => 1, 'form' => 1, 'div' => 1, 'span' => 1, 'table' => 1); // Known sourceforge issue #2977341 // B tags that are not closed cause us to return everything to the end of the document. protected $optional_closing_tags = array( 'tr' => array('tr' => 1, 'td' => 1, 'th' => 1), 'th' => array('th' => 1), 'td' => array('td' => 1), 'li' => array('li' => 1), 'dt' => array('dt' => 1, 'dd' => 1), 'dd' => array('dd' => 1, 'dt' => 1), 'dl' => array('dd' => 1, 'dt' => 1), 'p' => array('p' => 1), 'nobr' => array('nobr' => 1), 'b' => array('b' => 1), ); function __construct($str = null, $lowercase = true, $forceTagsClosed = true, $target_charset = DEFAULT_TARGET_CHARSET, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { if ($str) { if (preg_match("/^http:\/\//i", $str) || is_file($str)) $this->load_file($str); else $this->load($str, $lowercase, $stripRN, $defaultBRText); } // Forcing tags to be closed implies that we don't trust the html, but it can lead to parsing errors if we SHOULD trust the html. if (!$forceTagsClosed) { $this->optional_closing_array = array(); } $this->_target_charset = $target_charset; } function __destruct() { $this->clear(); } // load html from string function load($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { global $debugObject; // prepare $this->prepare($str, $lowercase, $stripRN, $defaultBRText); // strip out comments $this->remove_noise("'<!--(.*?)-->'is"); // strip out cdata $this->remove_noise("'<!\[CDATA\[(.*?)\]\]>'is", true); // Per sourceforge http://sourceforge.net/tracker/?func=detail&aid=2949097&group_id=218559&atid=1044037 // Script tags removal now preceeds style tag removal. // strip out <script> tags $this->remove_noise("'<\s*script[^>]*[^/]>(.*?)<\s*/\s*script\s*>'is"); $this->remove_noise("'<\s*script\s*>(.*?)<\s*/\s*script\s*>'is"); // strip out <style> tags $this->remove_noise("'<\s*style[^>]*[^/]>(.*?)<\s*/\s*style\s*>'is"); $this->remove_noise("'<\s*style\s*>(.*?)<\s*/\s*style\s*>'is"); // strip out preformatted tags $this->remove_noise("'<\s*(?:code)[^>]*>(.*?)<\s*/\s*(?:code)\s*>'is"); // strip out server side scripts $this->remove_noise("'(<\?)(.*?)(\?>)'s", true); // strip smarty scripts $this->remove_noise("'(\{\w)(.*?)(\})'s", true); // parsing while ($this->parse()) ; // end $this->root->_[HDOM_INFO_END] = $this->cursor; $this->parse_charset(); } // load html from file function load_file() { $args = func_get_args(); $this->load(call_user_func_array('file_get_contents', $args), true); // Per the simple_html_dom repositiry this is a planned upgrade to the codebase. // Throw an error if we can't properly load the dom. if (($error = error_get_last()) !== null) { $this->clear(); return false; } } // set callback function function set_callback($function_name) { $this->callback = $function_name; } // remove callback function function remove_callback() { $this->callback = null; } // save dom as string function save($filepath = '') { $ret = $this->root->innertext(); if ($filepath !== '') file_put_contents($filepath, $ret, LOCK_EX); return $ret; } // find dom node by css selector // Paperg - allow us to specify that we want case insensitive testing of the value of the selector. function find($selector, $idx = null, $lowercase = false) { return $this->root->find($selector, $idx, $lowercase); } // clean up memory due to php5 circular references memory leak... function clear() { foreach ($this->nodes as $n) { $n->clear(); $n = null; } // This add next line is documented in the sourceforge repository. 2977248 as a fix for ongoing memory leaks that occur even with the use of clear. if (isset($this->children)) foreach ($this->children as $n) { $n->clear(); $n = null; } if (isset($this->parent)) { $this->parent->clear(); unset($this->parent); } if (isset($this->root)) { $this->root->clear(); unset($this->root); } unset($this->doc); unset($this->noise); } function dump($show_attr = true) { $this->root->dump($show_attr); } // prepare HTML data and init everything protected function prepare($str, $lowercase = true, $stripRN = true, $defaultBRText = DEFAULT_BR_TEXT) { $this->clear(); // set the length of content before we do anything to it. $this->size = strlen($str); //before we save the string as the doc... strip out the \r \n's if we are told to. if ($stripRN) { $str = str_replace("\r", " ", $str); $str = str_replace("\n", " ", $str); } $this->doc = $str; $this->pos = 0; $this->cursor = 1; $this->noise = array(); $this->nodes = array(); $this->lowercase = $lowercase; $this->default_br_text = $defaultBRText; $this->root = new simple_html_dom_node($this); $this->root->tag = 'root'; $this->root->_[HDOM_INFO_BEGIN] = -1; $this->root->nodetype = HDOM_TYPE_ROOT; $this->parent = $this->root; if ($this->size > 0) $this->char = $this->doc[0]; } // parse html content protected function parse() { if (($s = $this->copy_until_char('<')) === '') return $this->read_tag(); // text $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = $s; $this->link_nodes($node, false); return true; } // PAPERG - dkchou - added this to try to identify the character set of the page we have just parsed so we know better how to spit it out later. // NOTE: IF you provide a routine called get_last_retrieve_url_contents_content_type which returns the CURLINFO_CONTENT_TYPE fromt he last curl_exec // (or the content_type header fromt eh last transfer), we will parse THAT, and if a charset is specified, we will use it over any other mechanism. protected function parse_charset() { global $debugObject; $charset = null; if (function_exists('get_last_retrieve_url_contents_content_type')) { $contentTypeHeader = get_last_retrieve_url_contents_content_type(); $success = preg_match('/charset=(.+)/', $contentTypeHeader, $matches); if ($success) { $charset = $matches[1]; if (is_object($debugObject)) { $debugObject->debugLog(2, 'header content-type found charset of: ' . $charset); } } } if (empty($charset)) { $el = $this->root->find('meta[http-equiv=Content-Type]', 0); if (!empty($el)) { $fullvalue = $el->content; if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag found' . $fullValue); } if (!empty($fullvalue)) { $success = preg_match('/charset=(.+)/', $fullvalue, $matches); if ($success) { $charset = $matches[1]; } else { // If there is a meta tag, and they don't specify the character set, research says that it's typically ISO-8859-1 if (is_object($debugObject)) { $debugObject->debugLog(2, 'meta content-type tag couldn\'t be parsed. using iso-8859 default.'); } $charset = 'ISO-8859-1'; } } } } // If we couldn't find a charset above, then lets try to detect one based on the text we got... if (empty($charset)) { // Have php try to detect the encoding from the text given to us. $charset = mb_detect_encoding($this->root->plaintext . "ascii", $encoding_list = array("UTF-8", "CP1252")); if (is_object($debugObject)) { $debugObject->debugLog(2, 'mb_detect found: ' . $charset); } // and if this doesn't work... then we need to just wrongheadedly assume it's UTF-8 so that we can move on - cause this will usually give us most of what we need... if ($charset === false) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'since mb_detect failed - using default of utf-8'); } $charset = 'UTF-8'; } } // Since CP1252 is a superset, if we get one of it's subsets, we want it instead. if ((strtolower($charset) == strtolower('ISO-8859-1')) || (strtolower($charset) == strtolower('Latin1')) || (strtolower($charset) == strtolower('Latin-1'))) { if (is_object($debugObject)) { $debugObject->debugLog(2, 'replacing ' . $charset . ' with CP1252 as its a superset'); } $charset = 'CP1252'; } if (is_object($debugObject)) { $debugObject->debugLog(1, 'EXIT - ' . $charset); } return $this->_charset = $charset; } // read tag info protected function read_tag() { if ($this->char !== '<') { $this->root->_[HDOM_INFO_END] = $this->cursor; return false; } $begin_tag_pos = $this->pos; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // end tag if ($this->char === '/') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // This represetns the change in the simple_html_dom trunk from revision 180 to 181. // $this->skip($this->token_blank_t); $this->skip($this->token_blank); $tag = $this->copy_until_char('>'); // skip attributes in end tag if (($pos = strpos($tag, ' ')) !== false) $tag = substr($tag, 0, $pos); $parent_lower = strtolower($this->parent->tag); $tag_lower = strtolower($tag); if ($parent_lower !== $tag_lower) { if (isset($this->optional_closing_tags[$parent_lower]) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent if ($this->parent->parent) $this->parent = $this->parent->parent; $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && isset($this->block_tags[$tag_lower])) { $this->parent->_[HDOM_INFO_END] = 0; $org_parent = $this->parent; while (($this->parent->parent) && strtolower($this->parent->tag) !== $tag_lower) $this->parent = $this->parent->parent; if (strtolower($this->parent->tag) !== $tag_lower) { $this->parent = $org_parent; // restore origonal parent $this->parent->_[HDOM_INFO_END] = $this->cursor; return $this->as_text_node($tag); } } else if (($this->parent->parent) && strtolower($this->parent->parent->tag) === $tag_lower) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } else return $this->as_text_node($tag); } $this->parent->_[HDOM_INFO_END] = $this->cursor; if ($this->parent->parent) $this->parent = $this->parent->parent; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } $node = new simple_html_dom_node($this); $node->_[HDOM_INFO_BEGIN] = $this->cursor; ++$this->cursor; $tag = $this->copy_until($this->token_slash); $node->tag_start = $begin_tag_pos; // doctype, cdata & comments... if (isset($tag[0]) && $tag[0] === '!') { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until_char('>'); if (isset($tag[2]) && $tag[1] === '-' && $tag[2] === '-') { $node->nodetype = HDOM_TYPE_COMMENT; $node->tag = 'comment'; } else { $node->nodetype = HDOM_TYPE_UNKNOWN; $node->tag = 'unknown'; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, true); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // text if ($pos = strpos($tag, '<') !== false) { $tag = '<' . substr($tag, 0, -1); $node->_[HDOM_INFO_TEXT] = $tag; $this->link_nodes($node, false); $this->char = $this->doc[--$this->pos]; // prev return true; } if (!preg_match("/^[\w\-:]+$/", $tag)) { $node->_[HDOM_INFO_TEXT] = '<' . $tag . $this->copy_until('<>'); if ($this->char === '<') { $this->link_nodes($node, false); return true; } if ($this->char === '>') $node->_[HDOM_INFO_TEXT] .= '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } // begin tag $node->nodetype = HDOM_TYPE_ELEMENT; $tag_lower = strtolower($tag); $node->tag = ($this->lowercase) ? $tag_lower : $tag; // handle optional closing tags if (isset($this->optional_closing_tags[$tag_lower])) { while (isset($this->optional_closing_tags[$tag_lower][strtolower($this->parent->tag)])) { $this->parent->_[HDOM_INFO_END] = 0; $this->parent = $this->parent->parent; } $node->parent = $this->parent; } $guard = 0; // prevent infinity loop $space = array($this->copy_skip($this->token_blank), '', ''); // attributes do { if ($this->char !== null && $space[0] === '') break; $name = $this->copy_until($this->token_equal); if ($guard === $this->pos) { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next continue; } $guard = $this->pos; // handle endless '<' if ($this->pos >= $this->size - 1 && $this->char !== '>') { $node->nodetype = HDOM_TYPE_TEXT; $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = '<' . $tag . $space[0] . $name; $node->tag = 'text'; $this->link_nodes($node, false); return true; } // handle mismatch '<' if ($this->doc[$this->pos - 1] == '<') { $node->nodetype = HDOM_TYPE_TEXT; $node->tag = 'text'; $node->attr = array(); $node->_[HDOM_INFO_END] = 0; $node->_[HDOM_INFO_TEXT] = substr($this->doc, $begin_tag_pos, $this->pos - $begin_tag_pos - 1); $this->pos -= 2; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->link_nodes($node, false); return true; } if ($name !== '/' && $name !== '') { $space[1] = $this->copy_skip($this->token_blank); $name = $this->restore_noise($name); if ($this->lowercase) $name = strtolower($name); if ($this->char === '=') { $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $this->parse_attr($node, $name, $space); } else { //no value attr: nowrap, checked selected... $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = true; if ($this->char != '>') $this->char = $this->doc[--$this->pos]; // prev } $node->_[HDOM_INFO_SPACE][] = $space; $space = array($this->copy_skip($this->token_blank), '', ''); } else break; } while ($this->char !== '>' && $this->char !== '/'); $this->link_nodes($node, true); $node->_[HDOM_INFO_ENDSPACE] = $space[0]; // check self closing if ($this->copy_until_char_escape('>') === '/') { $node->_[HDOM_INFO_ENDSPACE] .= '/'; $node->_[HDOM_INFO_END] = 0; } else { // reset parent if (!isset($this->self_closing_tags[strtolower($node->tag)])) $this->parent = $node; } $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next // If it's a BR tag, we need to set it's text to the default text. // This way when we see it in plaintext, we can generate formatting that the user wants. if ($node->tag == "br") { $node->_[HDOM_INFO_INNER] = $this->default_br_text; } return true; } // parse attributes protected function parse_attr($node, $name, &$space) { // Per sourceforge: http://sourceforge.net/tracker/?func=detail&aid=3061408&group_id=218559&atid=1044037 // If the attribute is already defined inside a tag, only pay atetntion to the first one as opposed to the last one. if (isset($node->attr[$name])) { return; } $space[2] = $this->copy_skip($this->token_blank); switch ($this->char) { case '"': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_DOUBLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('"')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; case '\'': $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_SINGLE; $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next $node->attr[$name] = $this->restore_noise($this->copy_until_char_escape('\'')); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next break; default: $node->_[HDOM_INFO_QUOTE][] = HDOM_QUOTE_NO; $node->attr[$name] = $this->restore_noise($this->copy_until($this->token_attr)); } // PaperG: Attributes should not have \r or \n in them, that counts as html whitespace. $node->attr[$name] = str_replace("\r", "", $node->attr[$name]); $node->attr[$name] = str_replace("\n", "", $node->attr[$name]); // PaperG: If this is a "class" selector, lets get rid of the preceeding and trailing space since some people leave it in the multi class case. if ($name == "class") { $node->attr[$name] = trim($node->attr[$name]); } } // link node's parent protected function link_nodes(&$node, $is_child) { $node->parent = $this->parent; $this->parent->nodes[] = $node; if ($is_child) $this->parent->children[] = $node; } // as a text node protected function as_text_node($tag) { $node = new simple_html_dom_node($this); ++$this->cursor; $node->_[HDOM_INFO_TEXT] = '</' . $tag . '>'; $this->link_nodes($node, false); $this->char = (++$this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return true; } protected function skip($chars) { $this->pos += strspn($this->doc, $chars, $this->pos); $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next } protected function copy_skip($chars) { $pos = $this->pos; $len = strspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next if ($len === 0) return ''; return substr($this->doc, $pos, $len); } protected function copy_until($chars) { $pos = $this->pos; $len = strcspn($this->doc, $chars, $pos); $this->pos += $len; $this->char = ($this->pos < $this->size) ? $this->doc[$this->pos] : null; // next return substr($this->doc, $pos, $len); } protected function copy_until_char($char) { if ($this->char === null) return ''; if (($pos = strpos($this->doc, $char, $this->pos)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } protected function copy_until_char_escape($char) { if ($this->char === null) return ''; $start = $this->pos; while (1) { if (($pos = strpos($this->doc, $char, $start)) === false) { $ret = substr($this->doc, $this->pos, $this->size - $this->pos); $this->char = null; $this->pos = $this->size; return $ret; } if ($pos === $this->pos) return ''; if ($this->doc[$pos - 1] === '\\') { $start = $pos + 1; continue; } $pos_old = $this->pos; $this->char = $this->doc[$pos]; $this->pos = $pos; return substr($this->doc, $pos_old, $pos - $pos_old); } } // remove noise from html content protected function remove_noise($pattern, $remove_tag = false) { $count = preg_match_all($pattern, $this->doc, $matches, PREG_SET_ORDER | PREG_OFFSET_CAPTURE); for ($i = $count - 1; $i > -1; --$i) { $key = '___noise___' . sprintf('% 3d', count($this->noise) + 100); $idx = ($remove_tag) ? 0 : 1; $this->noise[$key] = $matches[$i][$idx][0]; $this->doc = substr_replace($this->doc, $key, $matches[$i][$idx][1], strlen($matches[$i][$idx][0])); } // reset the length of content $this->size = strlen($this->doc); if ($this->size > 0) $this->char = $this->doc[0]; } // restore noise to html content function restore_noise($text) { while (($pos = strpos($text, '___noise___')) !== false) { $key = '___noise___' . $text[$pos + 11] . $text[$pos + 12] . $text[$pos + 13]; if (isset($this->noise[$key])) // $text = simple_html_dom . phpsubstr($text, 0, $pos) . $this->noise[$key] . substr($text, $pos + 14); $text = substr($text, 0, $pos).$this->noise[$key].substr($text, $pos+14); } return $text; } function __toString() { return $this->root->innertext(); } function __get($name) { switch ($name) { case 'outertext': return $this->root->innertext(); case 'innertext': return $this->root->innertext(); case 'plaintext': return $this->root->text(); case 'charset': return $this->_charset; case 'target_charset': return $this->_target_charset; } } // camel naming conventions function childNodes($idx = -1) { return $this->root->childNodes($idx); } function firstChild() { return $this->root->first_child(); } function lastChild() { return $this->root->last_child(); } function getElementById($id) { return $this->find("#$id", 0); } function getElementsById($id, $idx = null) { return $this->find("#$id", $idx); } function getElementByTagName($name) { return $this->find($name, 0); } function getElementsByTagName($name, $idx = -1) { return $this->find($name, $idx); } function loadFile() { $args = func_get_args(); $this->load_file($args); } } ?> 引用1.php-simple-html-dom-parser for PHP7.3 +:https://github.com/sunra/php-simple-html-dom-parser/issues/75
-
Laravel Blade分页模板 自带的有点丑,整个模板换掉模板放在/resources/views/vendor/pagination/bootstrap-3.blade.php<nav aria-label="Page navigation example"> <ul class="stui-page text-center clearfix"> <li><a href="{{ $paginator->url(1) }}">首页</a></li> <li><a href="{{ $paginator->previousPageUrl() }}">上一页</a></li> @if($paginator->onFirstPage()) <li class="hidden-xs active"><a href="{{ $paginator->url(1) }}">1</a></li> @for($i = 2;$i <= (($paginator->lastPage() > 5) ? 5 : $paginator->lastPage());$i++) <!-- 判断当前数据总数是否能够渲染当前页面 --> <li class="hidden-xs"><a href="{{ $paginator->appends(request()->query())->url($i) }}">{{ $i }}</a></li> @endfor @elseif(!$paginator->hasMorePages()) @for($i = $paginator->lastPage() - 3;$i <= $paginator->lastPage();$i++) <li class="hidden-xs"><a href="{{ $paginator->url($i) }}">{{ $i }}</a></li> @endfor <li class="hidden-xs active"><a href="{{ $paginator->url($paginator->lastPage()) }}">{{ $paginator->lastPage() }}</a></li> @else <!-- 分页功能显示中间部分 --> @for($i = $paginator->currentPage() - 2; $i <= $paginator->currentPage() + 2; $i++) @if($i > 0) @if($i == $paginator->currentPage()) <li class="hidden-xs active"><a href="{{ $paginator->url($i) }}">{{ $i }}</a></li> @else <li class="hidden-xs"><a href="{{ $paginator->url($i) }}">{{ $i }}</a></li> @endif @endif @endfor @endif <li class="active"><span class="num">{{ $paginator->currentPage() }}/{{ $paginator->lastPage() }}</span></li> <li><a href="{{ $paginator->nextPageUrl() }}">下一页</a></li> <li><a href="{{ $paginator->url($paginator->lastPage()) }}">尾页</a></li> </ul> </nav>样式:.stui-page li { display: inline-block; margin-left: 10px; } ul, ol, li, dt, dd { margin: 0; padding: 0; list-style: none; } .stui-page li .num, .stui-page li a { display: inline-block; padding: 5px 15px; border-radius: 4px; background-color: #fff; border: 1px solid #eee; } .stui-page li.active a, .stui-page li.disabled a { background-color: #f2990d; border: 1px solid #f2990d; color: #fff; } a, h1, h2, h3, h4, h5, h6 { color: #333333; } a, button { text-decoration: none; outline: none; -webkit-tap-highlight-color: rgba(0,0,0,0); }有些class是Boostrap3的在其他文件中使用时,如下@component('vendor.pagination.bootstrap-3', ['paginator' => $videoList]) @endcomponent
-
Homestead中PHP版本问题 Homestead中PHP版本问题1.项目运行时PHP版本1.1 查看Homestead中可用的PHP版本ll /etc/php可用版本是有许多的默认Homestead环境使用的是最新的PHP 8.1.8:1.2 切换项目使用版本在Homestead.yaml文件中进行配置:... sites: - map: yxq.test to: /home/vagrant/yxq-admin/public php: "7.3" ...然后重载一下虚拟机vagrant reload --provision2.Composer使用版本项目是从Github上Clone下来的,在composer update时报了一堆错误看了一下已上线的环境使用的PHP 7.3当我直接使用composer update时,默认会调用环境变量中的PHP 8.1查看一下PHP的环境变量设置whereis php发现各个版本都是有的,只是调用时候要加上版本号所以只能放弃全局的Composer,单独在项目中下载一个composer.pharphp7.3 composer.phar update之后的所有对artisan的操作,都要使用php7.3 artisan ...的方式了,避免因为版本不正确而导致错误发生。PS:可以直接更换环境变量,一劳永逸,我主用的还是最新版 所以没必要换了。# 安装完新项目的依赖后,要拷贝一下.env vagrant@homestead:~/yxq-admin$ cp .env.example .env # 生成key vagrant@homestead:~/yxq-admin$ php7.3 artisan key:generate Application key set successfully.接下来数据库迁移修改一下.envDB_DATABASE=yxq DB_USERNAME=homestead DB_PASSWORD=secret执行迁移php7.3 artisan migrate3.Vagrant常用命令序号命令解释1vagrant up启动虚拟机2vagrant ssh登录虚拟机 通过 exit 退出3vagrant status查看虚拟机状态4vagrant halt关机5vagrant destroy删除虚拟机6vagrant reload --provision修改配置文件后重载引用1.Laravel Homestead:https://laravel.com/docs/9.x/homestead#main-content2.composer.phar Download: https://getcomposer.org/download/3.多版本php环境,指定composer 使用的php版本: https://segmentfault.com/q/10100000126268834.homestead 添加新站点:https://www.cnblogs.com/cjjjj/p/9420844.html